你好,我是徐逸。
上节课我们一起学习了并发等待技术。不过在实际的编程实践中,我们会遇到各种各样的并发场景,所需要的并发技术也会有所不同。今天咱们就来聊聊在并发环境下,如何巧妙地运用锁,实现高性能、安全地访问多协程共享的数据。
我们先从一个问题入手。假如我们现在需要实现一个底层用map类型存储数据的本地缓存,该怎么设计,才能在并发环境下高性能且安全地访问这个缓存呢?
互斥锁 对于多协程共享数据的安全访问,最简单的方案就是用互斥锁。互斥锁能保证在同一时刻,只有一个协程能够访问被保护的共享数据 。
在Golang中,并发包sync里面的Mutex类型实现了互斥锁功能。它的核心是下面两个方法。
Lock方法,用于加锁,当锁已经被占用时,调用协程会阻塞直到锁可用。 Unlock方法,用于释放锁。 1 2 func (m *Mutex) func (m *Mutex)
知道了Mutex类型的方法,如同下面的代码一样,咱们可以在本地缓存的读写操作中,调用Mutex对象的Lock和Unlock方法来实现并发安全的本地缓存访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import ( "sync" ) type MutexCache struct { mu sync.Mutex data map [string ]string } func NewMutexCache () c := &MutexCache{data: make (map [string ]string )} return c } func (c *MutexCache) string ) { c.mu.Lock() defer c.mu.Unlock() c.data[key] = value } func (c *MutexCache) string ) (string , bool ) { c.mu.Lock() defer c.mu.Unlock() value, ok := c.data[key] return value, ok }
读写锁 **在一些读QPS不高的场景,简单通过互斥锁实现本地缓存功能的确可行。**但是在一些写比较少,读QPS特别高的场景,读请求之间对互斥锁的频繁竞争,会对读请求的性能产生不利的影响,导致读请求的处理速度下降,响应时间延长,影响到服务整体的吞吐。
那在读多写少的场景,我们该如何提升共享数据并发访问的性能呢?
为了提升共享数据读多写少场景的读性能,读写锁就能派上用场了 。与互斥锁不同,读写锁区分了读操作和写操作。
读写锁有三种状态:读模式锁定、写模式锁定和未锁定。当读写锁处于读模式锁定时,可以有多个协程同时进行读操作;而当读写锁处于写模式锁定时,只有一个协程能进行写操作,并且在写模式锁定时,读操作会被阻塞。
在 Go 语言中,sync并发包的RWMutex类型实现了读写锁功能。它的核心是下面几个方法。
Lock方法,用于获取写锁,如果读锁或写锁已经被占用,则阻塞直到写锁可用。 Unlock方法,用于释放写锁。 RLock方法,用于获取读锁,当写锁没被占用时,可以获取到读锁,否则阻塞直到写锁被释放。 RUnlock方法,用于释放读锁。 我用RWMutex类型实现了一个本地缓存结构,它的实现和互斥锁类似,不过需要在缓存的读操作中调用读锁RLock和RUnlock方法,在写操作中调用写锁Lock和Unlock方法。你可以对照后面的示例代码看一看。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import ( "sync" ) type RWMutexCache struct { rw sync.RWMutex data map [string ]string } func NewRWMutexCache () c := &RWMutexCache{data: make (map [string ]string )} return c } func (c *RWMutexCache) string ) { c.rw.Lock() defer c.rw.Unlock() c.data[key] = value } func (c *RWMutexCache) string ) (string , bool ) { c.rw.RLock() defer c.rw.RUnlock() value, ok := c.data[key] return value, ok }
那在读多写少的场景,读写锁的性能是不是真的比互斥锁高呢?咱们可以用下面的benchmark脚本测一测,benchmark设置的读写比例为90比1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 const ( cost = 1 * time.Millisecond readCnt = 90 writeCnt = 1 ) func BenchmarkMutexReadMore (b *testing.B) c := NewMutexCache() for i := 0 ; i < b.N; i++ { var wg sync.WaitGroup for j := 0 ; j < 1000 ; j++ { for k := 0 ; k < readCnt; k++ { wg.Add(1 ) go func () defer wg.Done() c.Get("11" ) time.Sleep(cost) }() } for k := 0 ; k < writeCnt; k++ { wg.Add(1 ) go func () defer wg.Done() c.Set("11" , "11" ) time.Sleep(cost) }() } } wg.Wait() } } func BenchmarkRwReadMore (b *testing.B) c := NewRWMutexCache() for i := 0 ; i < b.N; i++ { var wg sync.WaitGroup for j := 0 ; j < 1000 ; j++ { for k := 0 ; k < readCnt; k++ { wg.Add(1 ) go func () defer wg.Done() c.Get("11" ) time.Sleep(cost) }() } for k := 0 ; k < writeCnt; k++ { wg.Add(1 ) go func () defer wg.Done() c.Set("11" , "11" ) time.Sleep(cost) }() } } wg.Wait() } }
测试结果出来了,我们可以看到**用读写锁实现的缓存,在读多写少场景,性能比互斥锁高很多。**并发读写缓存相同的次数,读写锁耗时为52ms,而互斥锁需要62ms。
1 2 3 4 5 6 7 killianxu@KILLIANXU-MB0 7 % go test -bench . -benchmem goos: darwin goarch: amd64 pkg: server-go/7 cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz BenchmarkMutexReadMore-4 19 61786436 ns/op 9646439 B/op 183424 allocs/op BenchmarkRwReadMore-4 20 52166710 ns/op 9676492 B/op 183801 allocs/op
分段锁 虽然读写锁能提升读多写少场景的性能,但是当缓存写请求占用锁时,所有的缓存读请求仍然会被阻塞。那有没有办法减少阻塞的请求数呢?
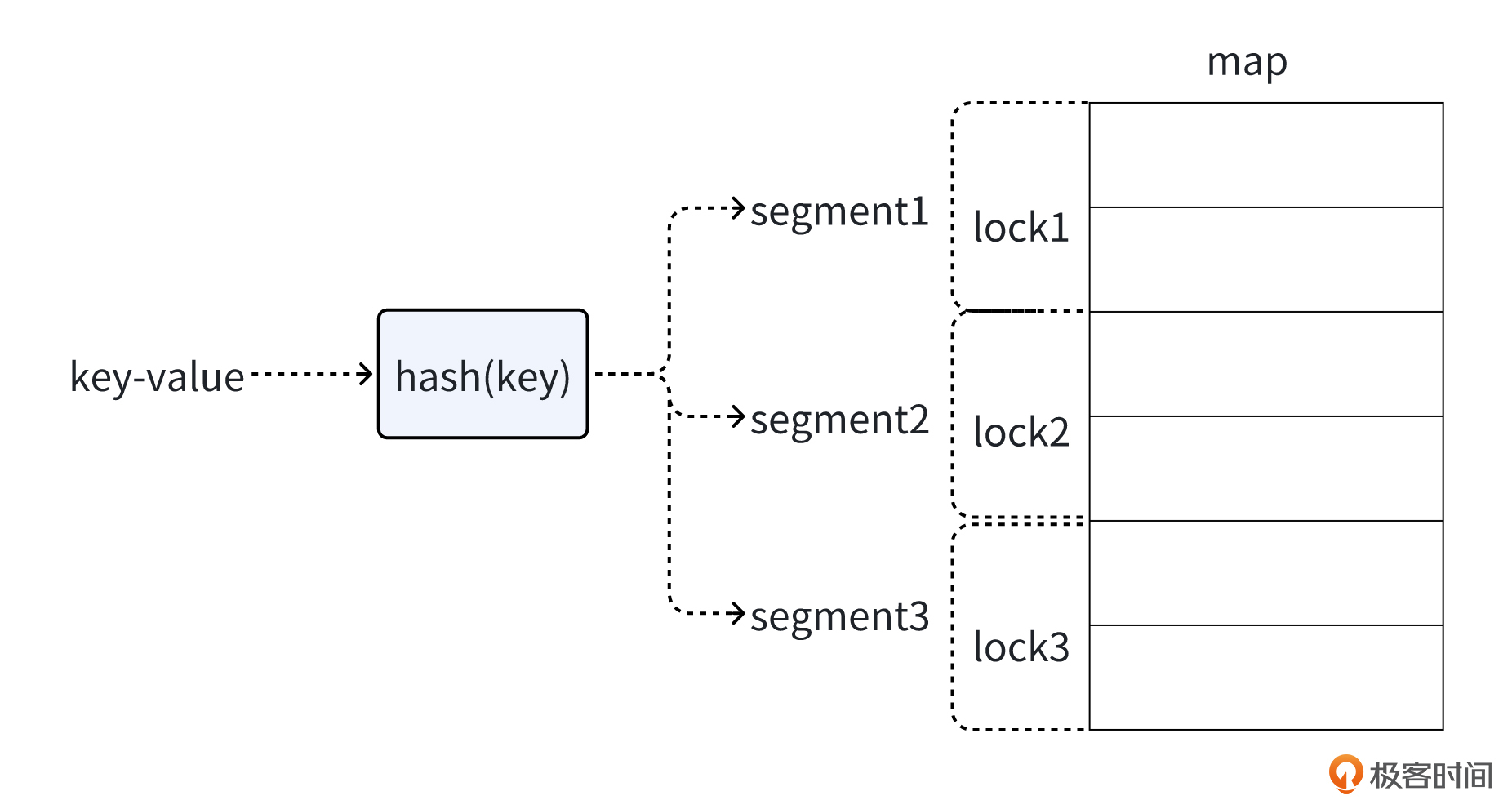
实际上,对于map结构,当并发对map的访问相对均匀地分布在不同的键上时,可以用分段锁来提高并发性能 。
就像下面的图展示的一样,分段锁的核心思想是将一个大的共享数据结构(如map)划分成多个较小的段(segment),每个段都有自己独立的锁**。**这样,当多个协程访问共享数据时,只要它们访问的是不同段的数据,就可以并发地进行操作,而不会互相阻塞。只有当多个操作涉及同一个段时,才会在这个段的锁上产生竞争。
Golang官方库没有现成的分段锁Map实现,我这里给了一个简单的实现,方便你体会分段锁的思想。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 type ConcurrentMap struct { segments []*segment numSegments int } type segment struct { lock sync.RWMutex data map [string ]string } func NewConcurrentMap (numSegments int ) cm := &ConcurrentMap{ segments: make ([]*segment, numSegments), numSegments: numSegments, } for i := range cm.segments { cm.segments[i] = &segment{ data: make (map [string ]string ), } } return cm } func (cm *ConcurrentMap) string ) int { hash := 0 for _, char := range key { hash += int (char) } return hash % cm.numSegments } func (cm *ConcurrentMap) string ) { segmentIndex := cm.getSegmentIndex(key) cm.segments[segmentIndex].lock.Lock() defer cm.segments[segmentIndex].lock.Unlock() cm.segments[segmentIndex].data[key] = value } func (cm *ConcurrentMap) string ) (string , bool ) { segmentIndex := cm.getSegmentIndex(key) cm.segments[segmentIndex].lock.RLock() defer cm.segments[segmentIndex].lock.RUnlock() value, ok := cm.segments[segmentIndex].data[key] return value, ok }
这段代码的核心是下面几个要点。
首先定义了ConcurrentMap结构体和segment结构体类型。ConcurrentMap结构体表示整个并发安全的map,它包含一个segment类型的切片,而segment包含一个读写锁lock和一个用于存储数据的map对象,每个segment代表了数据的一个分段。 在ConcurrentMap结构的写入方法里面,会先根据Key算出需要写入的分段,并将对应的分段加写锁进行写入。 在ConcurrentMap结构的读取方法里面,会先根据Key算出需要读取的分段,并将对应的分段加读锁进行读取。 无锁编程 除了上面的分段锁,实际上,在我们的实践中,如果发现内存缓存的数据量不大时,完全可以利用atomic包,去除本地缓存的锁依赖,从而最大限度地提升缓存读性能。
atomic包提供了对数据进行原子操作的功能。所谓原子操作,是指对数据的一个操作,如果分成多个步骤,这些步骤对外会表现成不可分割的整体,要么完整地执行,要么就根本不执行,外界不会看到它们只执行到一半的状态 。
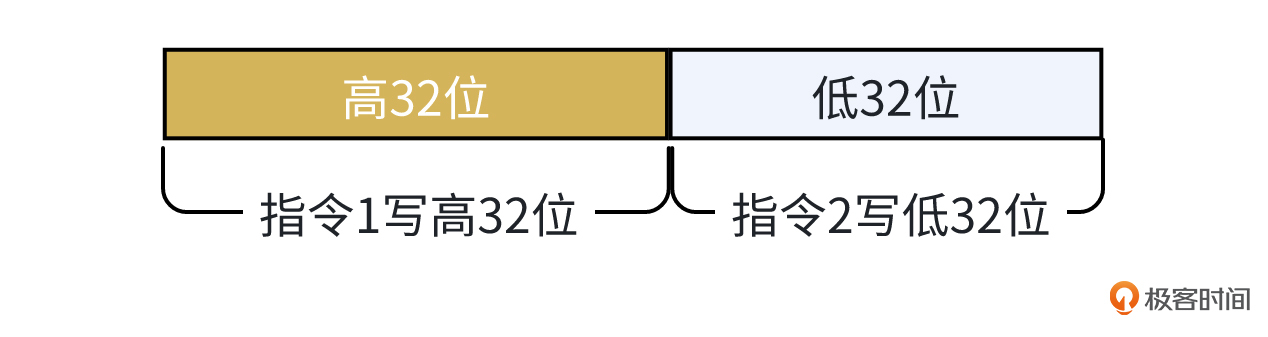
比如对int64类型变量的赋值操作,在32位机器上可能会拆分成两条CPU指令,每条指令写这个变量的一部分。如果一个协程写完低32位,还没来得及写高32位时,另一个协程读取了这个变量,那它读到的就是一个脏数据,很可能使我们的程序出现Bug,而原子操作就能避免其它协程读到这个中间状态变量。
让我们来看看atomic包提供的常见原子操作方法和类型。atomic包提供了以下5类操作。
Add操作,用于对变量进行加法操作。它们接受一个指向变量的指针和一个值作为参数,原子地将变量的值增加给定的增量。 1 2 3 4 5 func AddInt32 (addr *int32 , delta int32 ) new int32 )func AddInt64 (addr *int64 , delta int64 ) new int64 )func AddUint32 (addr *uint32 , delta uint32 ) new uint32 )func AddUint64 (addr *uint64 , delta uint64 ) new uint64 )func AddUintptr (addr *uintptr , delta uintptr ) new uintptr )
CAS操作,用于实现比较并交换的原子操作。它接受三个参数:一个指向变量的指针、一个预期的旧值和一个新值。它的操作逻辑是先比较指针所指向变量的当前值是否与预期的旧值相等,如果相等,就将变量的值原子地替换为新值,并返回 true,表示交换成功;如果不相等,就不进行替换操作,直接返回 false,表示交换失败。 1 2 3 4 5 6 func CompareAndSwapInt32 (addr *int32 , old, new int32 ) bool )func CompareAndSwapInt64 (addr *int64 , old, new int64 ) bool )func CompareAndSwapPointer (addr *unsafe.Pointer, old, new unsafe.Pointer) bool )func CompareAndSwapUint32 (addr *uint32 , old, new uint32 ) bool )func CompareAndSwapUint64 (addr *uint64 , old, new uint64 ) bool )func CompareAndSwapUintptr (addr *uintptr , old, new uintptr ) bool )
Load操作,用于原子地读取一个变量的值。这些函数以一个指向变量的指针作为参数,返回变量的当前值。 1 2 3 4 5 6 func LoadInt32 (addr *int32 ) int32 )func LoadInt64 (addr *int64 ) int64 )func LoadPointer (addr *unsafe.Pointer) func LoadUint32 (addr *uint32 ) uint32 )func LoadUint64 (addr *uint64 ) uint64 )func LoadUintptr (addr *uintptr ) uintptr )
Store操作,用于设置变量的值。同样以指针作为参数,将给定的值原子地存储到变量中。 1 2 3 4 5 6 func StoreInt32 (addr *int32, val int32) func StoreInt64 (addr *int64, val int64) func StorePointer (addr *unsafe.Pointer , val unsafe.Pointer ) func StoreUint32 (addr *uint32, val uint32) func StoreUint64 (addr *uint64, val uint64) func StoreUintptr (addr *uintptr, val uintptr)
Swap操作,用于交换变量的值。它接受一个指向变量的指针和一个新值作为参数,原子地将变量的当前值替换为新值,并返回被替换的旧值 。 1 2 3 4 5 6 func SwapInt32 (addr *int32 , new int32 ) int32 )func SwapInt64 (addr *int64 , new int64 ) int64 )func SwapPointer (addr *unsafe.Pointer, new unsafe.Pointer) func SwapUint32 (addr *uint32 , new uint32 ) uint32 )func SwapUint64 (addr *uint64 , new uint64 ) uint64 )func SwapUintptr (addr *uintptr , new uintptr ) uintptr )
上面5类操作的对象,都是常见的整型和指针类型,为了提供对复杂类型对象进行原子存取的能力,atomic包还提供了Value类型。
Value类型提供了下面4个方法,这几个方法的功能和atomic包的功能类似,但是操作的是任意类型的对象。
1 2 3 4 func (v *Value) new any) (swapped bool )func (v *Value) func (v *Value) func (v *Value) new any) (old any)
在了解了atomic包功能之后,现在让我们用atomic包的Value类型来实现一个读写无需加锁的本地缓存结构,示例代码如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import ( "sync/atomic" ) type LockFreeCache struct { cacheMap atomic.Value } func NewLockFreeCache () c := &LockFreeCache{} initialMap := make (map [string ]interface {}) c.cacheMap.Store(&initialMap) return c } func (c *LockFreeCache) map [string ]interface {}) { newMapPtr := &newMap c.cacheMap.Store(newMapPtr) } func (c *LockFreeCache) string ) (interface {}, bool ) { cacheMap := c.cacheMap.Load().(*map [string ]interface {}) value, ok := (*cacheMap)[key] return value, ok }
这段代码也很好理解,核心是下面几步。
首先,咱们设计一个LockFreeCache的结构,这个结构的成员变量是atomic包的Value类型,用于存储map类型的对象指针。
接着,在NewLockFreeCache构造函数中创建LockFreeCache对象,并初始化成员变量。
然后,我们提供了Update方法,内部调用Value类型的Store方法,原子地将map对象指针存入Value对象里,从而实现全量缓存数据更新。
最后,我们提供了Get方法,它的内部调用Value类型的Load方法,原子地获取map对象指针,从map对象里获取缓存Key对应的value。
小结 今天这节课,我以一个本地缓存数据结构的设计为例,在逐步对其进行设计优化的过程中,带你学习了Golang锁和atomic包的知识。现在让我们回顾一下锁和atomic包的应用场景。
当对数据的写操作较多或者读操作不频繁时,可以使用互斥锁保证并发访问的安全性; 当读操作远远多于写操作时,可以使用读写锁,允许多个协程同时进行读操作,而在写操作时进行独占式访问,这样可以提高并发读取的性能; 当大量数据存储在map中,并且协程对map的访问相对均匀地分布在不同的键上时,可以考虑使用分段锁提高性能。具体是通过将map分成多个段,每个段有自己的锁,降低锁粒度,从而提升并发性能。 当需要对共享对象进行原子操作时,可以利用atomic包无锁编程,避免加锁操作,从而提升性能。 希望你能够用心去体会各种锁和atomic包的应用。在今后遇到需要对数据进行并发操作的场景时,别忘了选择合适的并发安全访问方式。
思考题 在众多的数据结构中,栈是比较重要的一个数据结构,请你使用这节课学到的atomic包知识,实现一个并发安全的无锁栈。
欢迎你把你的答案分享在评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!