你好,我是徐逸。
在上节课的内容中,我们一起学习了锁和无锁编程技术,还使用分段锁和map类型,实现了一个缓存结构。不过,值得留意的是,其实 Go 语言的 sync 包已经提供了一种并发安全的 Map 类型。
今天,我就以大规模数据缓存的数据结构设计要点为例,带你掌握sync.Map类型以及针对map的GC优化技巧。
假如我们现在需要实现一个key-value类型的本地缓存,且缓存的key特别多,达到百万甚至千万级别,那么我们该怎么设计,才能在并发环境下高性能、安全地访问这个缓存呢?
针对大规模数据缓存的场景,我们在数据结构设计上要考虑的技术点有两个。
- 如何实现并发安全的map类型。
- 如何减少甚至避免因大规模数据缓存导致的GC开销。
并发map选择
实际上,大规模且有读写操作的数据缓存,咱们可以考虑的map类型有两种,一个是分段锁实现的map类型,另一个是sync包提供的Map类型。
那么我们到底该选择哪个呢?
在选型之前,我们需要先掌握sync.Map类型的基础知识和原理。
sync.Map是 Go 语言sync包中提供的一个内置的并发安全的map类型。它在设计上考虑了高并发场景,尽量避免加锁操作从而提升读写性能。
sync.Map该如何使用呢?下面我给了一段简单的代码,这段代码使用了sync.Map提供的Store、Load和Delete方法,分别用于写、读和删除操作。
1 | package main |
sync.Map是如何实现并发高性能操作的呢?
首先,我们来看下sync.Map的底层数据结构,它的核心是read和dirty两个map结构。read存储了部分写入Map的内容,用来加速读操作。而dirty存储了全量内容,需要加锁才能读写数据。
1 | type Map struct { |
接着,让我们来看下写入操作。当有key-value值写入时,如果这个key在read中不存在,接下来就要做新增操作,它会加锁写入dirty map中,并且将amended标记设置为true。而amended标记用于表示dirty中是否有不在read中的key-value值。
这个操作过程你可以结合后面的示意图看一下,这样理解起来更直观。
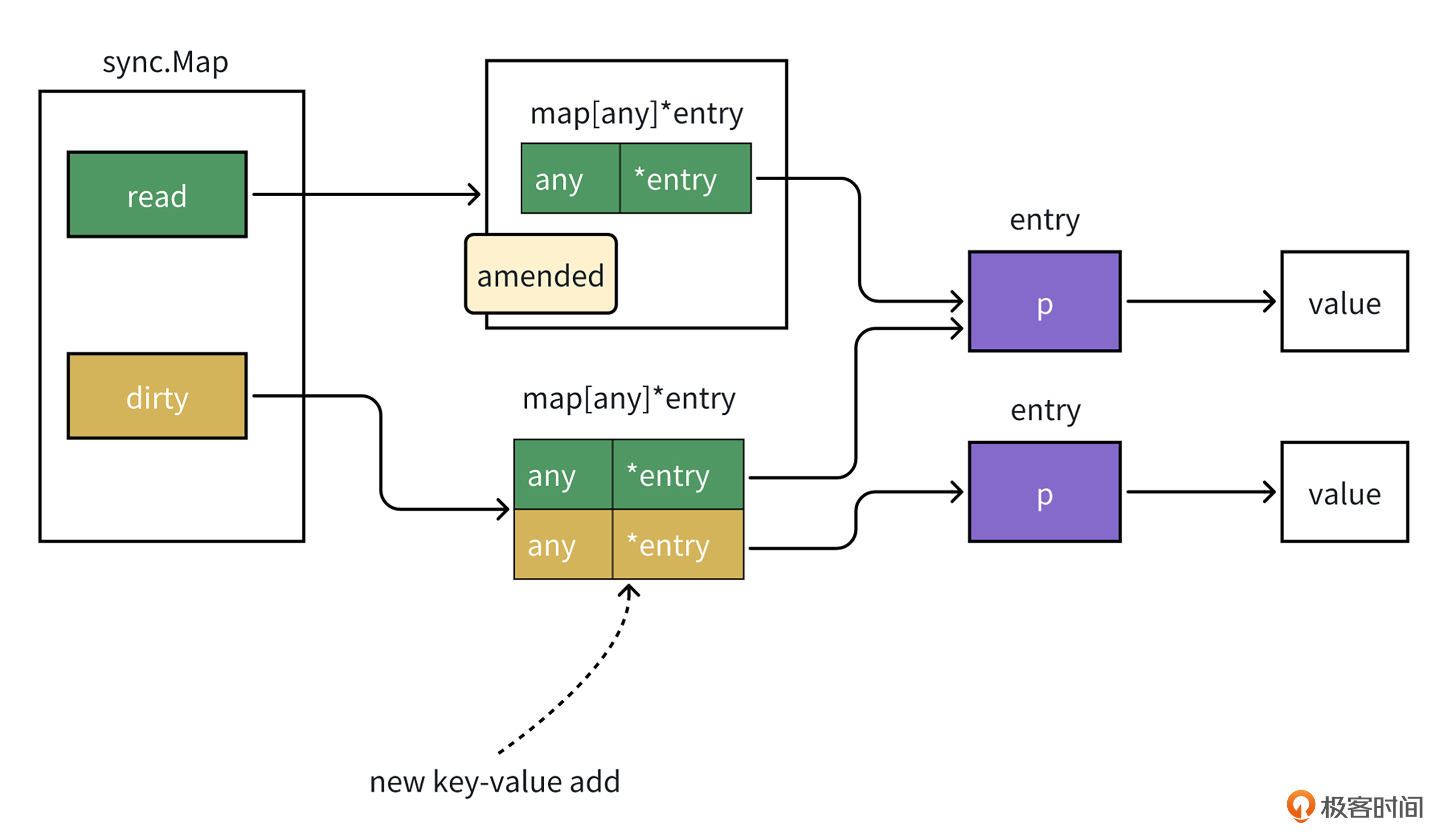
如果这个key在read中存在,则会进行更新操作,由于read map和dirty map里面存储的值是entry类型的指针,且entry类型的成员变量也是atomic.Pointer类型(如后面代码所示)。
1 | // An entry is a slot in the map corresponding to a particular key. |
因此在更新时就像下面的图那样,可以直接用CAS无锁操作替换指针p指向的变量,而无需做加锁操作。
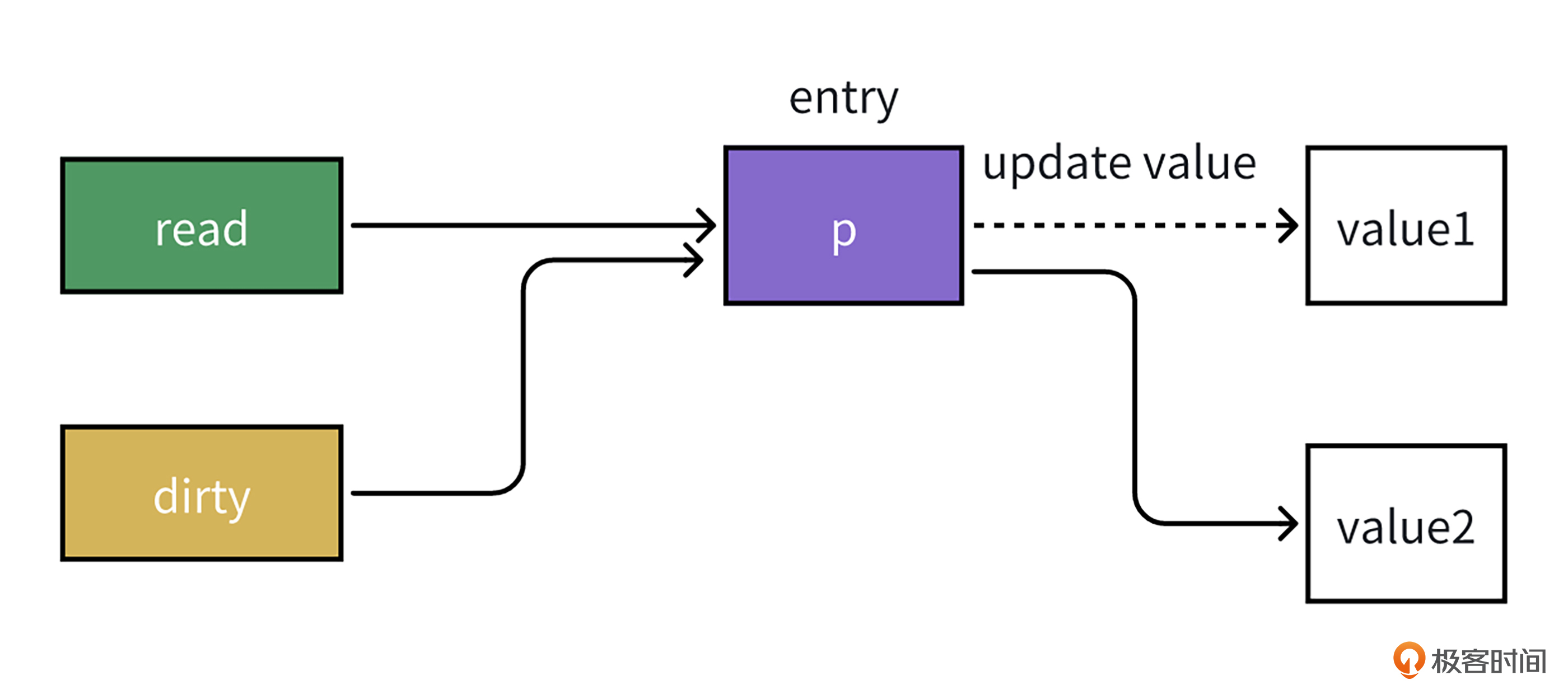
然后,让我们来看看读取操作,我们还是结合具体代码来理解。
1 | // Load returns the value stored in the map for a key, or nil if no |
当读取key对应的值时,会先从read中读取,当read中读不到,并且amended为true时,则会加锁从dirty map中读。这里可能导致从sync.Map读取的性能劣化,因为它既要从read中读一遍,又要加锁从dirty map中读一遍。
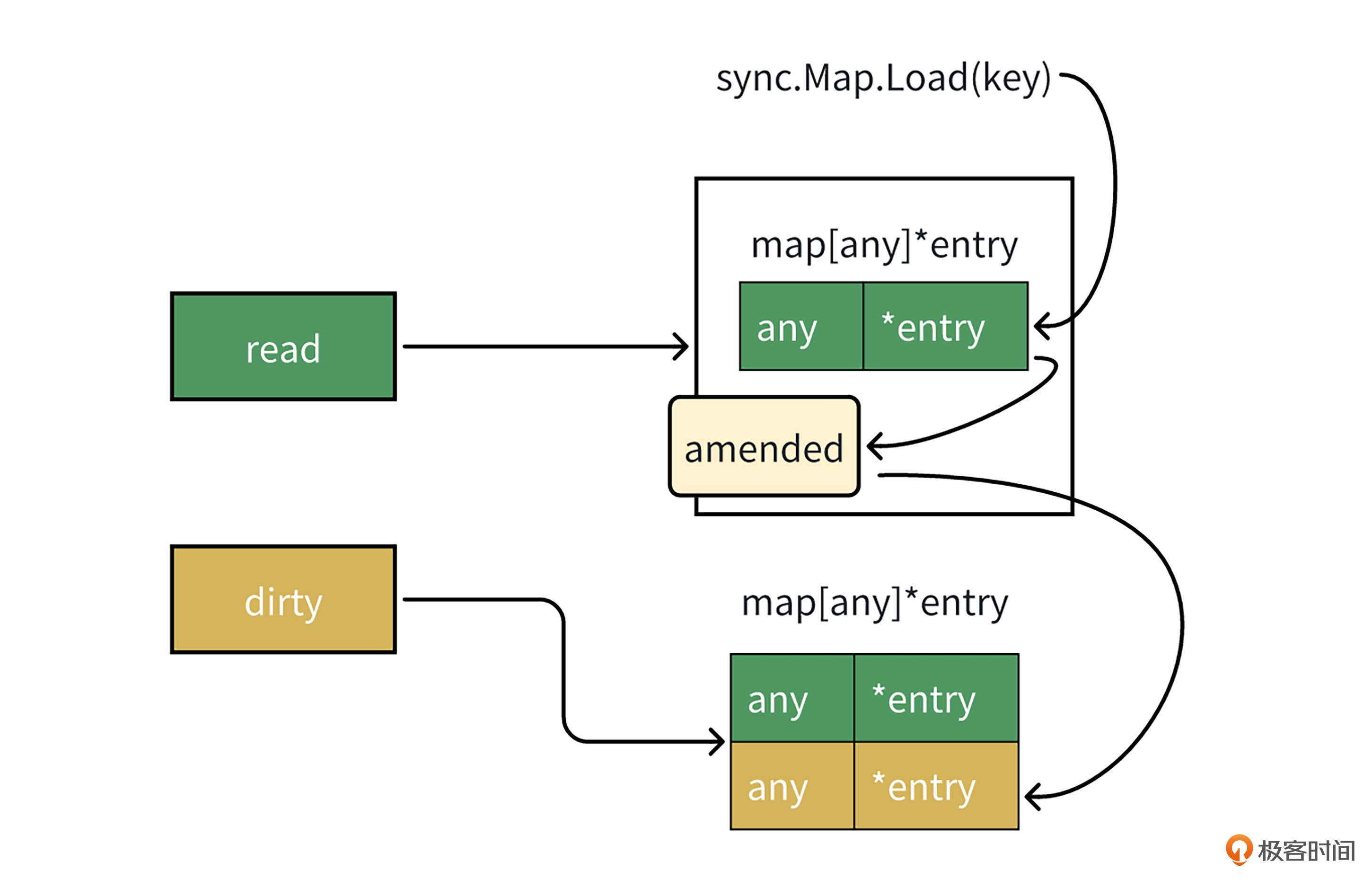
同时,每次read读不到,从dirty map中读时,它会调用missLocked方法,这个方法用于将map的misses字段加1,misses字段用于表示read读未命中次数,如果misses值比较大,说明read map的数据可能比dirty map少了很多。为了提升读性能,missLocked方法里会将dirty map变成新的read map,代码如下。
1 | func (m *Map) missLocked() { |
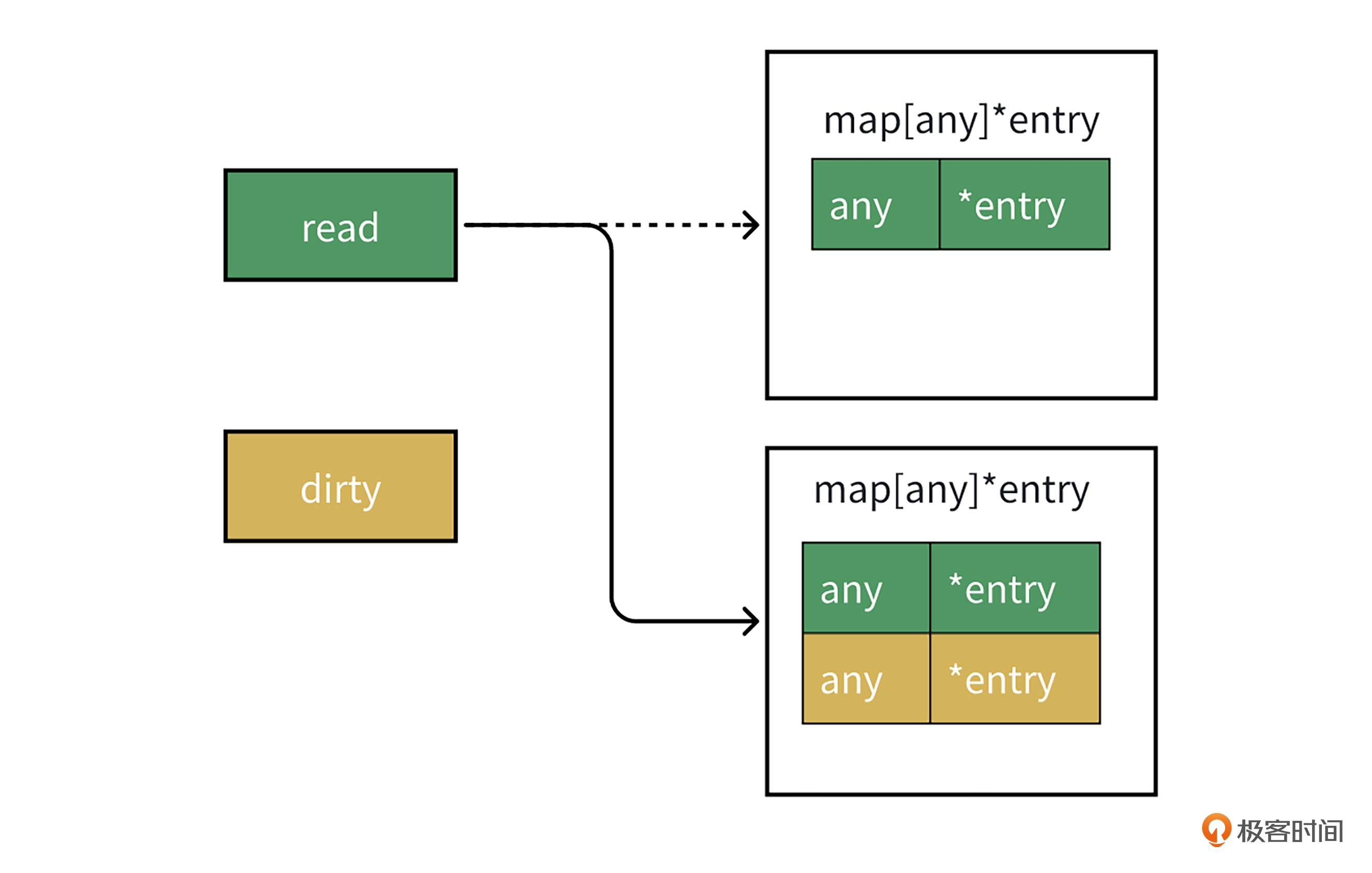
最后,让我们来看看另一个可能导致写入sync.Map的性能劣化的点。上面的missLocked方法,会将dirty map置为nil,当有新的key-value值写入时,为了能保持dirty map有全量数据,就像下面代码的swap方法,它会加锁并且调用dirtyLocked方法,遍历read map并全量赋值拷贝给dirty map。
你可以看看后面的代码,再想想这样写会不会有什么问题?
1 | // Swap swaps the value for a key and returns the previous value if any. |
不知道你有没有发现?当数据量比较大时,这样会导致大量数据的拷贝,性能会劣化严重。比如我们缓存几百万条数据,就存在几百万条数据的赋值拷贝。
通过上面sync.Map的原理分析,我们可以看出,sync.Map是通过两个map来实现读写分离,从而达到高性能读的目的。不过它存在下面几个缺点。
- 由于有两个map,因此占用内存会比较高。
- 更适用于读多写少的场景,当由于写比较多或者本地缓存没有全量数据时,会导致读map经常读不到数据,而需要加锁再读一次,从而导致读性能退化。
- 当数据量比较大时,如果写入触发读map向写map拷贝,会导致较大的性能开销。
可以看出来,sync.Map的使用场景还是比较苛刻的。
那回到刚开始的问题,在大规模数据缓存时,我们是该选择分段锁实现的map还是sync.Map类型来缓存数据呢?
答案是分段锁map。原因是我们很难准确地预估读写比例,而且读写比例也会随着业务的发展变化。此外,在大规模数据缓存时,两个map的内存和拷贝开销也是不得不考虑的稳定性风险点,因此在大规模数据缓存时,我们一般使用分段锁实现的map来缓存数据。
map gc优化
在做了并发map的选型之后,我们还需要考虑的一点是在缓存大量数据时,如何避免GC导致的性能开销。
我以下面的代码为例,分别测试key、value为string类型的map在不同数据规模下的GC开销。
1 | import ( |
测试结果出来了,map中储存1k条数据和500w条数据的GC耗时差异巨大。500w条数据,GC耗时290ms,而1k条数据耗时只需要480µs,有600倍的性能差异。
1 | killianxu@KILLIANXU-MB0 8 % go test -gcflags=all=-l gc_size_test.go -v |
那么在大规模数据缓存下,GC为什么耗时会这么长呢?
这是因为GC在做对象扫描标记时,需要扫描标记map里面的全量key-value对象,数据越多,需要扫描的对象越多,GC时间也就越长。
扫描标记的耗时过长,会引发一系列不良影响。它不仅会大量消耗 CPU 资源,降低服务吞吐,而且在标记工作未能及时完成的情况下,GC 会要求处理请求的协程暂停手头的业务逻辑处理流程,转而协助 GC 开展标记任务。这样一来,部分请求的响应延时将会不可避免地大幅升高,严重影响系统的响应效率与性能表现。
为了避免GC对程序性能造成影响,对于map类型,Golang在 1.5版本提供了一种绕过GC扫描的方法。绕过GC要满足下面两个条件。
第一,map的key-value类型不能是指针类型且内部不能包含指针。比如string类型,它的底层数据结构中有指向数组的指针,因此不满足这个条件。
1 | // 字符串数据结构 |
那到底不含指针类型,能不能缩短GC开销呢?咱们将代码里map的key-value类型换成int类型再试一下。
1 | // 测试key-value非指针类型,int的gc开销 |
你会发现,key-value换成int类型的map,gc性能提升非常明显,gc时间从290ms变成了2.3ms,提升了几百倍。
1 | killianxu@KILLIANXU-MB0 8 % go test -gcflags=all=-l -run Test500wIntGCDuration -v |
第二,key-value除了需要满足非指针这个条件,key/value的大小也不能超过 128 字节,如果超过128字节,key-value就会退化成指针,导致被GC扫描。
我们用value大小分别是128、129字节的结构体测试一下,测试代码如下。
1 | func TestSmallStruct(t *testing.T) { |
**果然,key-value的大小超过128字节会导致GC性能开销变大。**对于129字节的结构体,GC耗时264ms,而128字节,只需要2.4ms,性能差距高达百倍。
1 | killianxu@KILLIANXU-MB0 8 % go test -gcflags=all=-l -run "TestSmallStruct|TestBigStruct" -v |
通过前面的测试,我们知道了,在缓存大规模数据时,为了避免GC开销,key-value不能含指针类型且key-value的大小不能超过128字节。
实际上,咱们在缓存大规模数据时,可以使用成熟的开源库来实现,比如 bigcache、freecache 等。它们的底层就是使用分段锁加map类型来实现数据存储的,同时,它们也利用了刚刚讲过的map的key-value特性,来避免GC扫描。
以bigcache为例,它的使用比较简单。通过Get和Set方法就可以实现读写操作。
1 | import ( |
小结
今天这节课,我以大规模数据缓存的场景为例,带你学习了golang sync包的Map类型以及map的gc优化技巧。
现在让我们回顾一下sync.Map的知识以及map的zero gc特性。
sync.Map 在底层巧妙地借助两个 map 来达成读写分离的设计架构,以此实现高性能的读取操作。然而,这种设计并非毫无瑕疵,它存在着一些不容忽视的问题。
一方面,其内存占用相对较高;另一方面,当写入操作较为频繁时,读取性能会出现明显的退化现象。
此外,由于其基于两个 map 的架构特性,在数据处理过程中还会产生两个 map 之间的数据拷贝开销,这在一定程度上影响了整体的性能表现与资源利用效率。正因为 sync.Map 的使用场景较为严苛,在实际的编程实践中,使用这个方法的频率反倒比较低。
当map中缓存的数据比较多时,为了避免GC开销,我们可以将map中的key-value类型设计成非指针类型且大小不超过128字节,从而避免GC扫描。
希望你能够用心去体会map gc的优化技巧。在今后遇到大规模数据缓存的场景,别忘了用上学到的技巧去做GC优化。
思考题
在大规模数据缓存时,我们虽然可以用bigcache来避免gc,但是却会引起其它开销,那么是哪些开销呢?
欢迎你把你的答案分享在评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!