你好,我是王健伟。
前面我们已经讲解了图的概念、图的存储结构以及图的遍历问题。那么你可能非常想知道图都有哪些具体的实际用途。这节课,我就和你分享图的第一个实际用途——最小生成树。
首先我们先一起看一看什么是最小生成树。
最小生成树
前面我们曾经展示过生成树:一个无向连通图的生成树是包含图中全部顶点的一个极小连通子图。
这里的极小,指的是边尽可能少但要保持连通。一个连通图可能会有多个生成树,生成树中如果有n个顶点,则必须有n-1条边,若减去一条边,则会变成非连通图,若增加一条边则图中就会存在回路。
好了,现在我们假设要在n个城市(顶点)之间修路(边)。通常来讲每两个城市之间都可以修一条路(无向完全图),这意味着n个城市最多可以修$\frac{n(n-1)}{2}$条路。但是每修一条路都需要花费一定的资金,所以在每两个城市之间都修一条路是很不划算的。
要想让这n个城市连通,只需要修n-1条路即可,那么如何在这些可能的路线中选择n-1条以使总的资金花销最少呢?
图1是一个带权的无向图,你可以把图中的各个顶点看成是一座座城市。图中城市之间的连线对应的权值代表修一条连通这两个城市之间的道路所需要的资金。
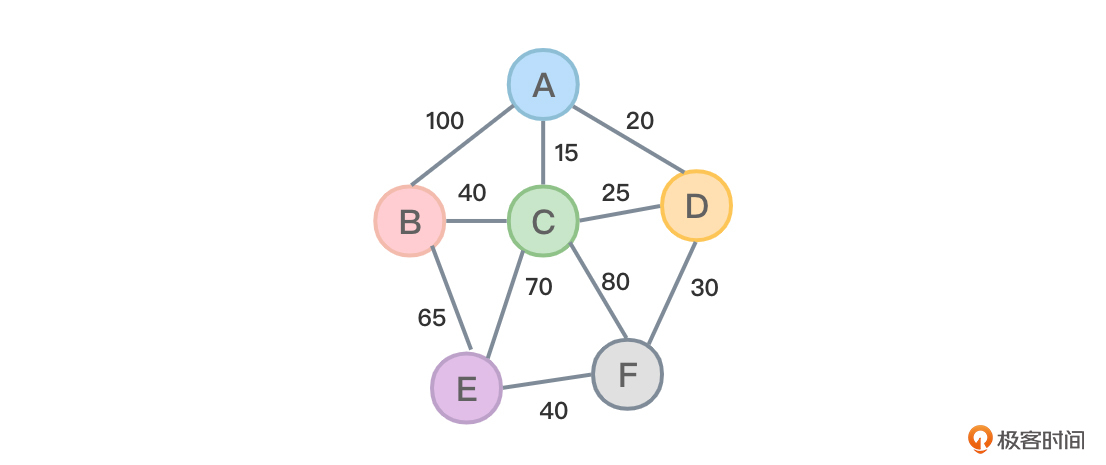
图2中所示的是随意列举的三种连通方案:
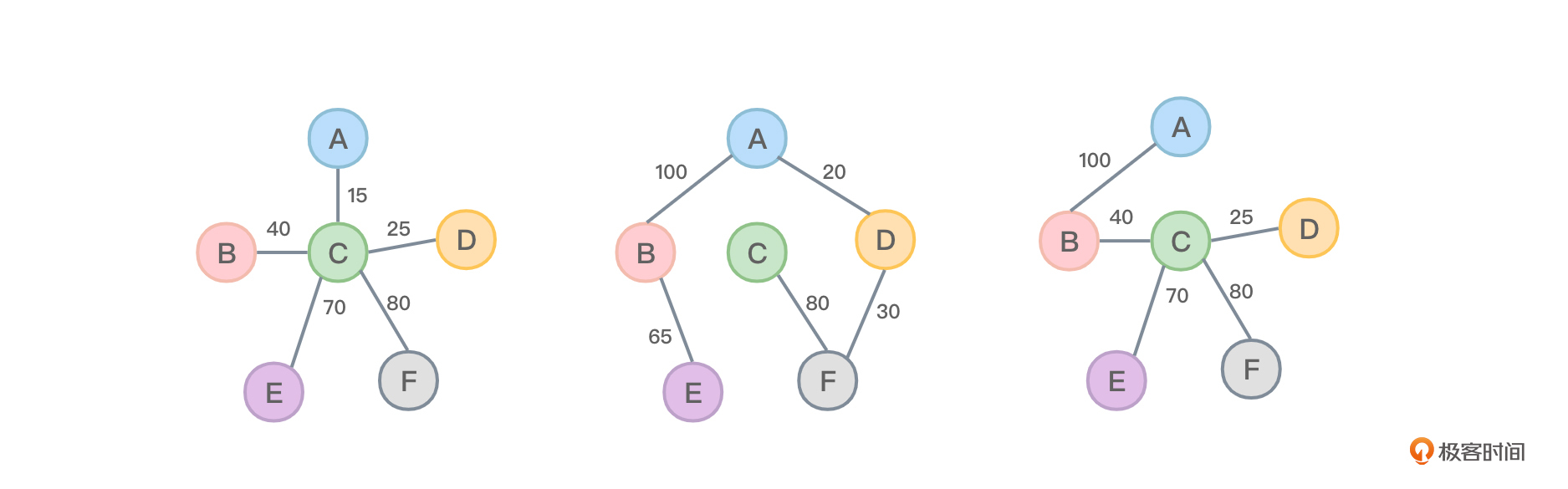
图2的三种修路方式中,第一种方式所需要的资金是40+15+25+80+70=230。第二种方式所需要的资金是100+20+65+80+30=295。第三种方式所需要的资金是100+40+25+70+80=315。
所谓最小生成树,就是在图1的所有生成树中找到最小代价(所需要资金最少)生成树即找到所需要资金最少的修路方式。
这里我们给出最小生成树的定义:对于一个带权无向连通图,其生成树不同,树中所有边上的权值之和也可能不同,边上权值之和最小的生成树就是该带权连通无向图的最小生成树(Minimum Spanning Tree,简称MST)。这里有下面几点需要说明。
- 最小生成树是可能有多个的,但最小生成树边的权值之和肯定是最小且唯一的。
- 最小生成树的边数是顶点数-1。再减少一条边则变成了非连通图,增加一条边则图中就会存在回路。
- 如果连通图本身是一棵树(连通且不存在回路),则其最小生成树就是它本身。
寻找连通图的最小生成树的算法有很多,其中有两种比较典型,分别是普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法。这节课我们就先说普里姆算法。
普里姆(Prim)算法详解
普里姆算法从任意顶点(比如顶点A)开始构建最小生成树。针对图1,我来描述一下具体步骤。
- 将顶点A放入到最小生成树中。
- 找与顶点A连通的所有其他顶点中代价最小(两个顶点对应的边权值最小)的顶点放入到最小生成树中。这里应该是将顶点C放入到最小生成树中。
- 找与最小生成树中所有顶点相邻的,其他不在最小生成树里的顶点中,边权值最小的顶点(如果多个则任选一个)放入到最小生成树中。这里应该是将顶点D放入到最小生成树中,因为顶点A和顶点D之间的边权值是20。
- 重复上面这个步骤,再分别将顶点F、E、B放入到最小生成树中,直至图中所有顶点都加入到了最小生成树中,如图3所示:
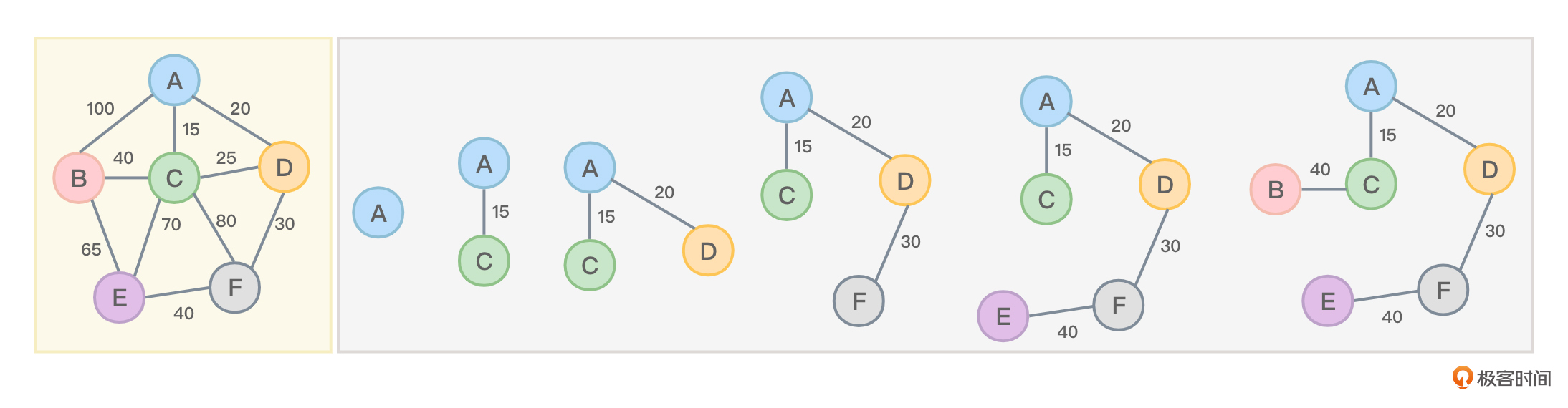
从图3可以看到,最少生成树所对应边的权值之和是15+20+30+40+40=145。
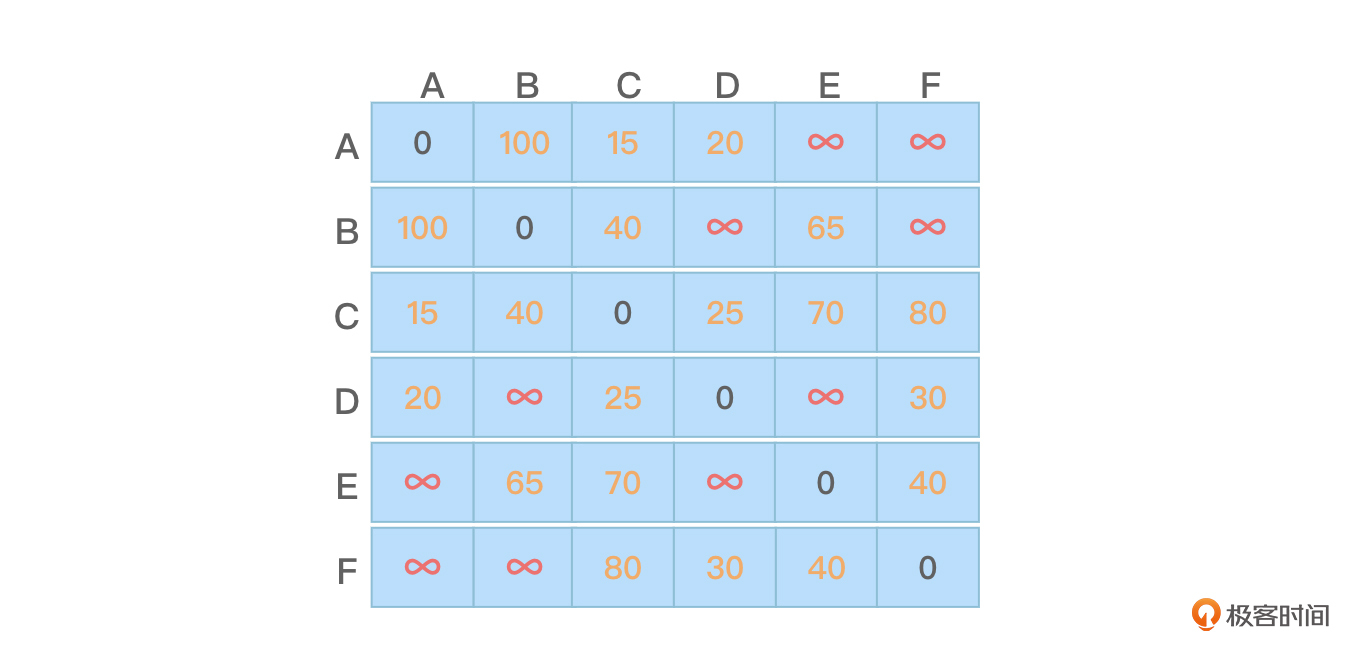
采用邻接矩阵的存储方式保存图更容易访问到图中边的权值,所以下面的代码中将采用邻接矩阵的方式来存储图1所示的带权无向图并用普利姆算法构建该图的最小生成树。因为图中顶点的边是带有权值的,因此两个不同的顶点之间若没有边则可以将它们之间代表边的权值设置为一个非常大的数字并在显示时显示为∞(无穷),相同顶点的权值显示为0即可,图1所对应的邻接矩阵如图4所示:
普里姆算法的实现代码也有很多种写法,这里先选择一种简单好理解的实现方法,我们看一下代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
| #define MaxVertices_size 100 //最大顶点数大小
#define INT_MAX_MY 2147483647//整型能够保存的最大数值,用以表示两个顶点之间不存在边
template<typename T> //T代表顶点类型
class GraphMatrix//邻接矩阵代表的图
{
public:
GraphMatrix() //构造函数,空间复杂度O(n)+O(n^2)=O(n^2)
{
m_numVertices = 0;
m_numEdges = 0;
pm_VecticesList = new T[MaxVertices_size];
pm_Edges = new int* [MaxVertices_size];
for (int i = 0; i < MaxVertices_size; ++i)
{
pm_Edges[i] = new int[MaxVertices_size];
} //end for
for (int i = 0; i < MaxVertices_size; ++i)
{
for (int j = 0; j < MaxVertices_size; ++j)
{
if (i == j)
{
//顶点自己到自己对应的边的权值应该用0标记
pm_Edges[i][j] = 0;
}
else
{
pm_Edges[i][j] = INT_MAX_MY; //开始时矩阵中不记录边信息,即边与边之间的权值信息给成最大值INT_MAX_MY
}
}
}
}
~GraphMatrix() //析构函数
{
delete[] pm_VecticesList;
for (int i = 0; i < MaxVertices_size; ++i)
{
delete[] pm_Edges[i];
} //end for
delete[] pm_Edges;
}
public:
//插入顶点
bool InsertVertex(const T& tmpv)
{
if (m_numVertices >= MaxVertices_size) //顶点空间已满
{
cout <<"顶点空间已满"<< endl;
return false;
}
if (GetVertexIdx(tmpv) != -1) //该顶点已经存在
{
cout <<"顶点"<< tmpv <<"已经存在!"<< endl;
return false;
}
pm_VecticesList[m_numVertices] = tmpv;
m_numVertices++;
return true;
}
//插入边
bool InsertEdge(const T& tmpv1, const T& tmpv2,int weight) //在tmpv1和tmpv2两个顶点之间插入一条边,注意权值也要插入进来。weight代表边与边之间的权值
{
int idx1 = GetVertexIdx(tmpv1);
int idx2 = GetVertexIdx(tmpv2);
if (idx1 == -1 || idx2 == -1)//某个顶点不存在,不可以插入边
return false;
if (pm_Edges[idx1][idx2] != INT_MAX_MY)//边重复
return false;
pm_Edges[idx1][idx2] = pm_Edges[idx2][idx1] = weight; //无向图是个对称矩阵。tmpv1到tmpv2之间插入边就等于tmpv2到tmpv1之间插入了边
m_numEdges++; //边数量增加1
return true;
}
void DispGraph() //显示图信息,其实就是显示矩阵信息
{
cout <<""; //为了凑一些对齐关系,所以先输出三个空格
//输出图中的顶点,其实就是矩阵的最顶上一行的顶点名信息
for (int i = 0; i < m_numVertices; ++i)
{
printf("%5c", pm_VecticesList[i]); //5:不够5位的右对齐
}
cout << endl; //换行
//输出对应的邻接矩阵
for(int i = 0; i < m_numVertices; ++i)//注意循环结束条件是真实的顶点个数
{
//输出矩阵左侧的顶点名
cout << pm_VecticesList[i] <<"";
for (int j = 0; j < m_numVertices; ++j)
{
if (pm_Edges[i][j] == INT_MAX_MY)
{
printf("%5s", "∞"); //两个顶点之间没有边
}
else
{
printf("%5d", pm_Edges[i][j]);
}
} //end for j
cout << endl; //换行
} //end for i
cout << endl; //换行
}
//判断某个idx值是否位于最小生成树顶点下标数组中
bool IfInMstVertIdxArray(int curridx,int *p_inMstVertIdxArray,int in_MstVertCount)
{
for (int i = 0; i < in_MstVertCount; ++i)
{
if (p_inMstVertIdxArray[i] == curridx) //这个idx位于最小生成树顶点下标数组中
return true;
} //end for
return false; //这个idx不在最小生成树顶点下标数组中
}
//用 普里姆(Prim)算法创建最小生成树
bool CreateMinSpanTree_Prim(const T& tmpv) //tmpv作为创建最小生成树时的起始顶点
{
int idx = GetVertexIdx(tmpv);
if (idx == -1) //顶点不存在
return false;
int in_MstVertCount = 1; //已经增加到生成树【最小生成树】中的顶点数量,刚开始肯定是要把起始顶点放进去所以这里给1
int* p_inMstVertIdxArray = new int[m_numVertices]; //已经增加到生成树中的顶点的下标会保存到该数组中
p_inMstVertIdxArray[0] = idx; //起始顶点下标
int minWeight = INT_MAX_MY; //用来记录当前的最小权值,先给成最大值
int minTmpStartVertIdx = -1; //临时存放一个开始顶点的下标值(一个边的开始顶点)
int minTmpEndVertIdx = -1; //临时存放一个目标顶点的下标值(一个边的末端顶点)
while (true)
{
if (in_MstVertCount == m_numVertices) //生成树中的顶点数量等于了整个图的顶点数量,最小生成树创建完毕
break;
minWeight = INT_MAX_MY; //权值先给成最大值
for (int iv = 0; iv < in_MstVertCount; ++iv) //遍历所有生成树中已有的顶点,从其中找到以该顶点开始的边中权值最小的边所对应的目标顶点
{
int tmpidx = p_inMstVertIdxArray[iv]; //拿到该位置的信息【顶点索引】
for (int i = 0; i < m_numVertices; ++i) //遍历所有顶点以找到所有以tmpidx顶点为起点的边
{
if (pm_Edges[tmpidx][i] != 0 && pm_Edges[tmpidx][i] != INT_MAX_MY) //当前顶点与目标顶点不是同一个顶点(否则权值==0)并且与目标顶点之间有连线(否则权值 == INT_MAX_MY)
{
//在以iv顶点为起点的所有边中找权值最小的边
//权值最小的边所对应目标顶点不在最小生成树顶点下标数组中,说明是个新顶点
if (pm_Edges[tmpidx][i] < minWeight && IfInMstVertIdxArray(i, p_inMstVertIdxArray, in_MstVertCount) == false)
{
minWeight = pm_Edges[tmpidx][i];
minTmpStartVertIdx = tmpidx; //记录边对应的开始顶点下标
minTmpEndVertIdx = i; //记录边对应的目标顶点下标
}
}
} //end for i
}//end for iv
//走到这里,肯定找到了个新顶点,输出最小生成树的边信息
cout << pm_VecticesList[minTmpStartVertIdx] <<"--->"<< pm_VecticesList[minTmpEndVertIdx] <<" : 权值="<< minWeight << endl;
p_inMstVertIdxArray[in_MstVertCount] = minTmpEndVertIdx; //将新顶点增加到最小生成树的下标数组中
in_MstVertCount++;
} //end while
//内存释放
delete[] p_inMstVertIdxArray;
return true;
}
private:
//获取顶点下标
int GetVertexIdx(const T& tmpv)
{
for (int i = 0; i < m_numVertices; ++i)
{
if (pm_VecticesList[i] == tmpv)
return i;
}
return -1; //不存在的顶点
}
private:
int m_numVertices; //当前顶点数量
int m_numEdges; //边数量
T* pm_VecticesList; //顶点列表
int** pm_Edges; //边信息,二维数组
};
|
在main主函数中,增加下面的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| GraphMatrix<char> gm;
//向图中插入顶点
gm.InsertVertex('A');
gm.InsertVertex('B');
gm.InsertVertex('C');
gm.InsertVertex('D');
gm.InsertVertex('E');
gm.InsertVertex('F');
//向图中插入边
gm.InsertEdge('A', 'B', 100); //100代表边的权值
gm.InsertEdge('A', 'C', 15);
gm.InsertEdge('A', 'D', 20);
gm.InsertEdge('B', 'C', 40);
gm.InsertEdge('B', 'E', 65);
gm.InsertEdge('C', 'D', 25);
gm.InsertEdge('C', 'E', 70);
gm.InsertEdge('C', 'F', 80);
gm.InsertEdge('D', 'F', 30);
gm.InsertEdge('E', 'F', 40);
gm.DispGraph();
gm.CreateMinSpanTree_Prim('A');
|
执行结果为:

上述代码中,成员函数CreateMinSpanTree_Prim实现了用普里姆算法创建最小生成树,代码性能也许算不上最优,但胜在实现方法简单且易于理解。我们尝试具体描述一下。
- 创建一个数组专门保存最小生成树中的顶点并把开始顶点放入其中。
- 下面的步骤会不断循环直到最小生成树中的顶点数量等于整个图的顶点数量。
- 遍历最小生成树中的所有顶点,从其中找到以该顶点开始的边中权值最小的边所对应的目标顶点,当然该目标顶点必须是没有出现在最小生成树顶点数组中。
- 以“开始顶点—>目标顶点:权值”的格式显示输出最小生成树的边信息并将目标顶点放入最小生成树顶点数组中。
CreateMinSpanTree_Prim所实现的普里姆最小生成树算法代码有改进空间,通过改进来进一步提升代码执行效率,但改进也会增加代码理解难度。这里我来具体描述一下。
1. 引入一个称为lowcost的数组用来保存权值信息。lowcost会记录最小生成树中顶点到达所有顶点的最小权值信息——最小权值也就是最近的邻接边。之后,引入一个称为veridx的数组用来保存顶点对应的下标信息。
假设是从顶点A开始构建最小生成树,那么观察图4可以看到,顶点A与其他各个顶点相关边的权值信息为“0 100 15 20 ∞ ∞”,将这个信息保存在lowcost数组中。而因为顶点A的下标为0,所以将0这个下标值保存在veridx数组中。目前lowcost和veridx两个数组中的内容看起来如下:
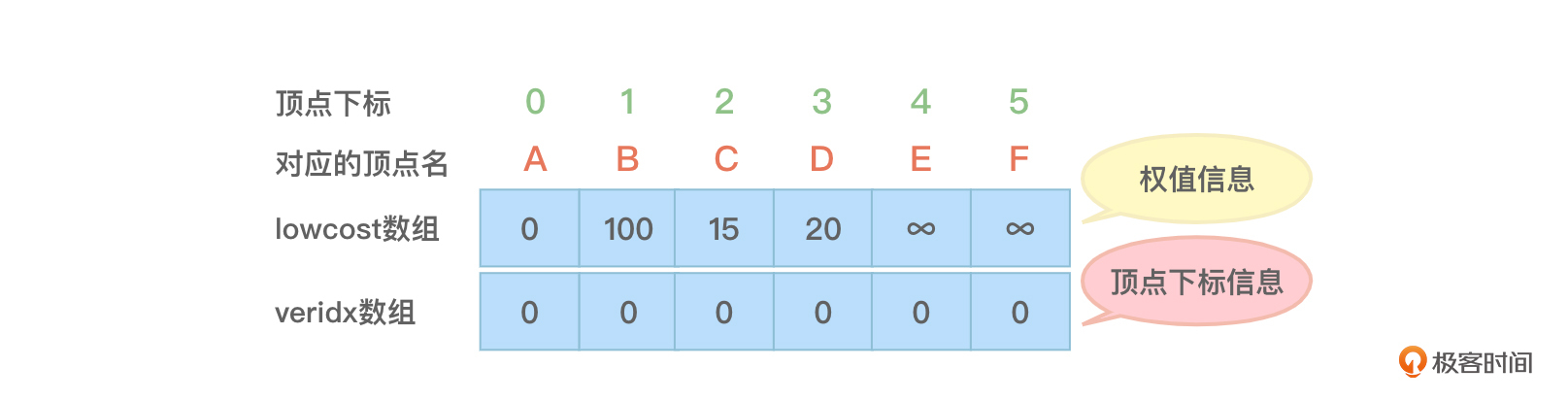
- 以下步骤会不断循环直到最小生成树中的顶点数量等于整个图的顶点数量。第一次循环描述如下:
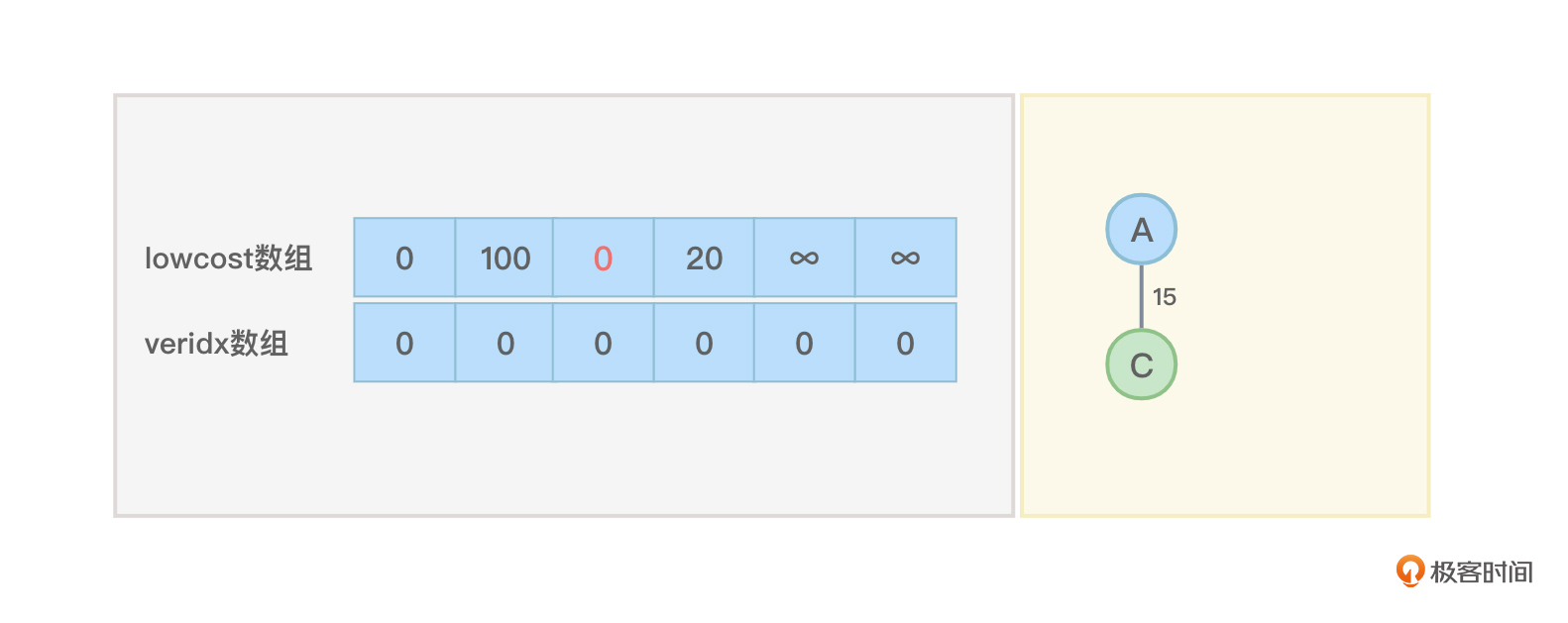
- 在lowcost数组中寻找一个权值最小的边(但权值不能为0),该边对应的目标顶点下标也就同时从lowcost数组中拿到了。在图5中,最小的权值是15,对应的顶点下标是2。
- veridx数组中下标2对应的位置的值是0,这代表下标为0的顶点和下标为2的顶点之间的边的权值是15。
- 下标为0到下标为2的顶点之间的边就是最小生成树的一条边,将该信息显示到屏幕上。然后将lowcost数组下标2对应位置的权值15修改为0,之后标示下标2代表的顶点被加入到了最小生成树中。目前lowcost和veridx两个数组中的内容和已经产生的部分生成树看起来如下:
- 因为找到了下标为2的新顶点,所以需要更新lowcost和veridx数组信息。新顶点相关边的权值信息通过看邻接矩阵就可以看到,为“15 40 0 25 70 80”,这些信息与lowcost数组对应位置的权值信息做比较,如果新顶点对应位置的权值信息小于lowcost数组对应位置的权值信息(这说明新加入到最小生成树的顶点到达其他相同顶点的距离更短),则将lowcost数组对应位置的权值更改为新顶点对应位置的权值信息,并将veridx数组对应位置的内容修改为新顶点的下标值。这一系列操作后lowcost和veridx两个数组中的内容看起来如下:
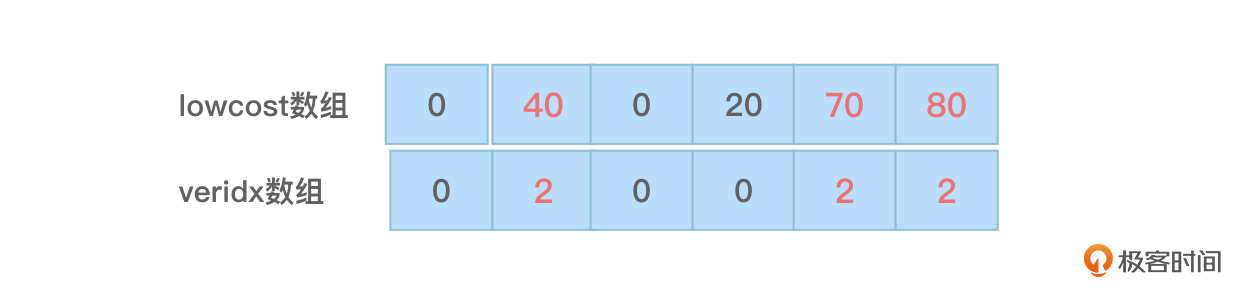
之所以进行上述操作,是因为新加入到最小生成树中的下标为2的新顶点(顶点C)比下标为0的顶点(顶点A)到达图7中下标为1、4、5的顶点(顶点B、E、F)的权值更小,所以当然要记录权值更小的顶点信息。换个角度再想一想:原来顶点A与顶点B之间的边权值是100,现在因为最小生成树中加入了顶点C,而顶点C和顶点B之间边的权值是40,当然就不再需要理会原来顶点A与顶点B之间的权值,只需要记录顶点C与顶点B之间的权值是40即可。
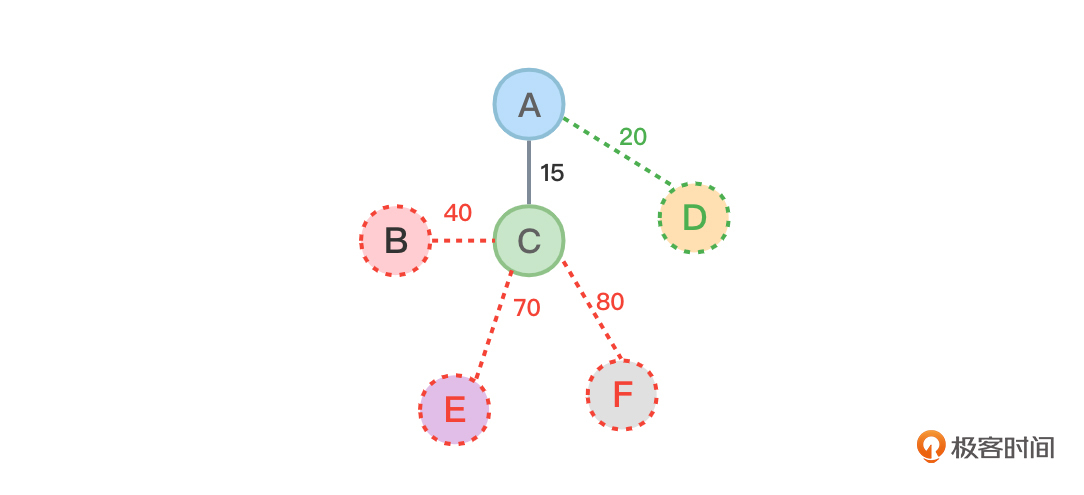
图7包含的信息非常多,你可能无法从图7中解读出全部有用的信息,这里解读一下试试看。
信息一:下标为0的位置(该位置代表顶点A),lowcost数组对应位置内容为0,这表示顶点A已经位于最小生成树中。
信息二:下标为1的位置(该位置代表顶点B),lowcost数组对应位置内容为40,veridx数组对应位置为2(顶点C),这表示顶点B和顶点C之间的边权值为40。
信息三:下标为2的位置(该位置代表顶点C),lowcost数组对应位置内容为0,这表示顶点C已经位于最小生成树中。
信息四:下标为3的位置(该位置代表顶点D),lowcost数组对应位置内容为20,veridx数组对应位置为0(顶点A),这表示顶点D和顶点A之间的边权值为20。
信息五:下标为4的位置(该位置代表顶点E),lowcost数组对应位置内容为70,veridx数组对应位置为2(顶点C),这表示顶点E和顶点C之间的边权值为70。
信息六:下标为5的位置(该位置代表顶点F),lowcost数组对应位置内容为80,veridx数组对应位置为2(顶点C),这表示顶点F和顶点C之间的边权值为80。
图8中虚线绘制部分内容代表了图7所表达的信息:
将上述改进过的普里姆最小生成树算法实现代码命名为CreateMinSpanTree_Prim2,就是下面的内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| //用普里姆(Prim)算法创建最小生成树的第二种方法
bool CreateMinSpanTree_Prim2(const T& tmpv)//tmpv作为创建最小生成树时的起始顶点
{
int idx = GetVertexIdx(tmpv);
if (idx == -1) //顶点不存在
return false;
int lowcost[MaxVertices_size]; //保存权值的数组,采用new动态分配也可以
int veridx[MaxVertices_size]; //保存顶点下标的数组,采用new动态分配也可以
for (int i = 0; i < m_numVertices; ++i)
{
lowcost[i] = pm_Edges[idx][i]; //保存开始顶点的权值信息
veridx[i] = idx; //保持开始顶点的下标信息
} //end for
int minTmpStartVertIdx = -1;
int minTmpEndVertIdx = -1;
for (int i = 0; i < m_numVertices - 1; ++i)//循环“顶点数-1”次即可创建出最小生成树
{
//在lowcost数组中找权值最小的顶点
int minWeight = INT_MAX_MY;
for (int w = 0; w < m_numVertices; ++w) //遍历lowcost数组,找到其中权值最小的
{
if(lowcost[w] != 0 && minWeight > lowcost[w])
{
minWeight = lowcost[w];
minTmpEndVertIdx = w;
}
} //end for w
minTmpStartVertIdx = veridx[minTmpEndVertIdx];
cout << pm_VecticesList[minTmpStartVertIdx] <<"--->"<< pm_VecticesList[minTmpEndVertIdx] <<" : 权值="<< minWeight << endl; //显示边和权值信息
lowcost[minTmpEndVertIdx]= 0;//权值设置为0表示该顶点被放入了最小生成树中
//通过最新寻找到的顶点来修改lowcost数组和veridx数组中的内容
for (int v = 0; v < m_numVertices; ++v)
{
if (lowcost[v] > pm_Edges[minTmpEndVertIdx][v])
{
lowcost[v] = pm_Edges[minTmpEndVertIdx][v];
veridx[v] = minTmpEndVertIdx;
}
} //end for v
}//end for i
return true;
}
|
在main主函数中,继续增加下面的测试代码,这次以顶点E作为开始顶点构建最小生成树。
1
2
| cout <<"---------------------"<< endl;
gm.CreateMinSpanTree_Prim2('E');
|
新增代码的执行结果如下:

从代码中可以看到,普里姆算法是从某个顶点开始构建最小生成树,每次将权值最小的新顶点加入到最小生成树直到所有顶点都加入到最小生成树中。因为算法涉及到了双重for循环,所以普里姆算法的时间复杂度为O($|V|^{2}$),即O($n^{2}$)。
因为普利姆算法只与图中顶点的数量有关,与边数无关,所以当图中顶点数比较少,而边数比较多时使用该算法构造最小生成树效果较好。
小结
这节课我首先带你回顾了一下无向连通图的生成树的概念,接着,我们给出了一个带权无向连通图的最小生成树的定义。之所以给出这个最小生成树的定义,是因为我们要用一些算法来寻找连通图的最小生成树。最小生成树对于解决在多个城市之间如何修路所花费的资金最少等问题具有非常现实的意义。
接着我向你介绍了利用普里姆(Prim)算法来寻找一个无向连通图的最小生成树。我们重点描述一下利用该算法从图中任意一个顶点构建最小生成树的步骤。
- 将任意顶点放入到最小生成树中。
- 找与该顶点连通的所有其他顶点中代价最小的顶点放入到最小生成树中。
- 找与最小生成树中所有顶点相邻的,其他不在最小生成树里的顶点中,边权值最小的顶点放入到最小生成树中。
- 重复上面的步骤。
另外,在编写代码方面,代码中我们采用邻接矩阵来保存图,而后我带你实现了一个比较好理解的普里姆算法来创建最小生成树。不过,比较好理解的普里姆算法的缺点是执行效率上稍差一些,所以,我们又改进了现有算法,实现了另外一种比较难理解但执行效率更高的普里姆算法,这种改进算法需要引入一个lowcost权值信息数组以及保存顶点对应下标信息的veridx数组,我向你详细阐述了这两个数组的用法以帮助你更好地理解改进后的普里姆算法实现最小生成树的代码。
普里姆算法的时间复杂度是O($n^{2}$),并且因为该算法只与图中顶点的数量相关,与边数无关,所以当图中顶点数比较少,边数比较多时最适合使用该算法构造最小生成树。
课后思考
请你想一想,现实生活中有哪些问题比较适合用普里姆算法实现的最小生成树来解决?
欢迎你在留言区和我分享。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!