你好,我是金伟。
经过上节课,我想你已经对Agent智能体的应用开发有了一定的了解。你有没有想过Coze这样的平台底层是如何实现的呢?
我把上节课的话茬留在了我们选择自研了一套营销Agent平台底层,那这节课,我就带你完全实现一遍Agent平台底层框架,对你了解完整的Agent平台架构非常有帮助。
我们先说最核心的第一部分,底层开发。
底层开发
先回顾一下我们上节课说的Agent和大型模型之间的代理关系。这个代理层构成了系统的核心部分。我们应该将这一万个Agent视为一个统一的Agent实体。这个统一的Agent可以通过提示词进行重新定义。本质上,它就是一个基于大型模型的聊天应用程序。
关键在于,我们需要一种机制,将我们的业务执行逻辑嵌入到聊天的过程中。
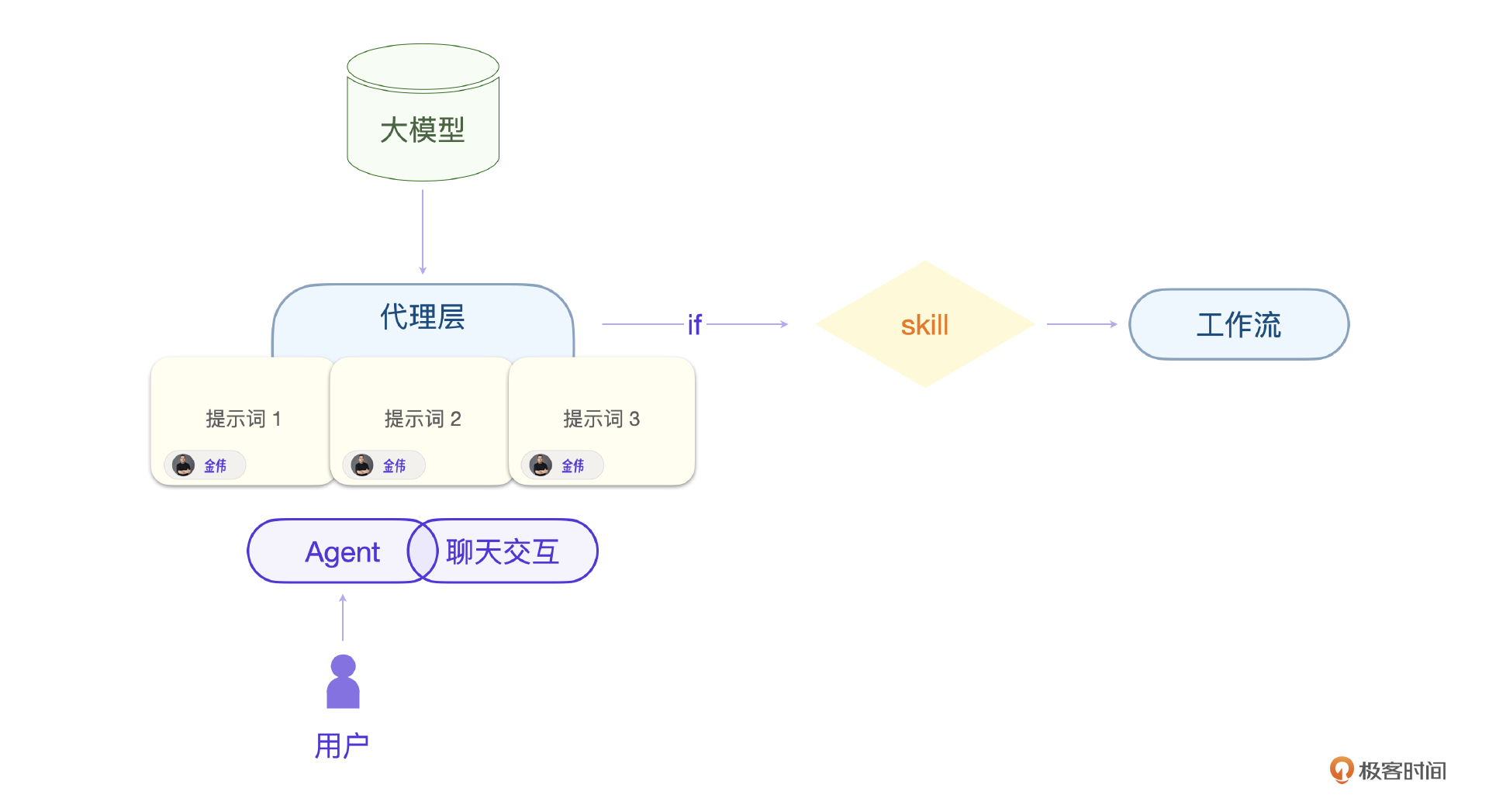
有的人可能会想,让大模型直接调用我们的业务逻辑不就行了吗?从广义上来说,这样实现也没问题,只不过我们这里说的大模型指的是只有文本聊天能力的大模型。所以还需要一个“助理”角色代理执行。
意图识别
那怎么才能实现这个核心的代理层呢?我们先从一个简单的例子开始说。用过GPT的朋友可能都有下面的体验,当我们要求GPT基于互联网已有知识回答问题,它会怎么做呢?

你看,我问了一个问题,GPT搜索了7个网站,然后根据这些网站的内容做出了回答。但是显然大模型是不具备网络搜索能力的。那它是怎么做的呢?答案是我们提问里的 请你先查询网络资料再回答我 这个意图必须被识别出来,并改变原有流程,它才能做到执行搜索操作。
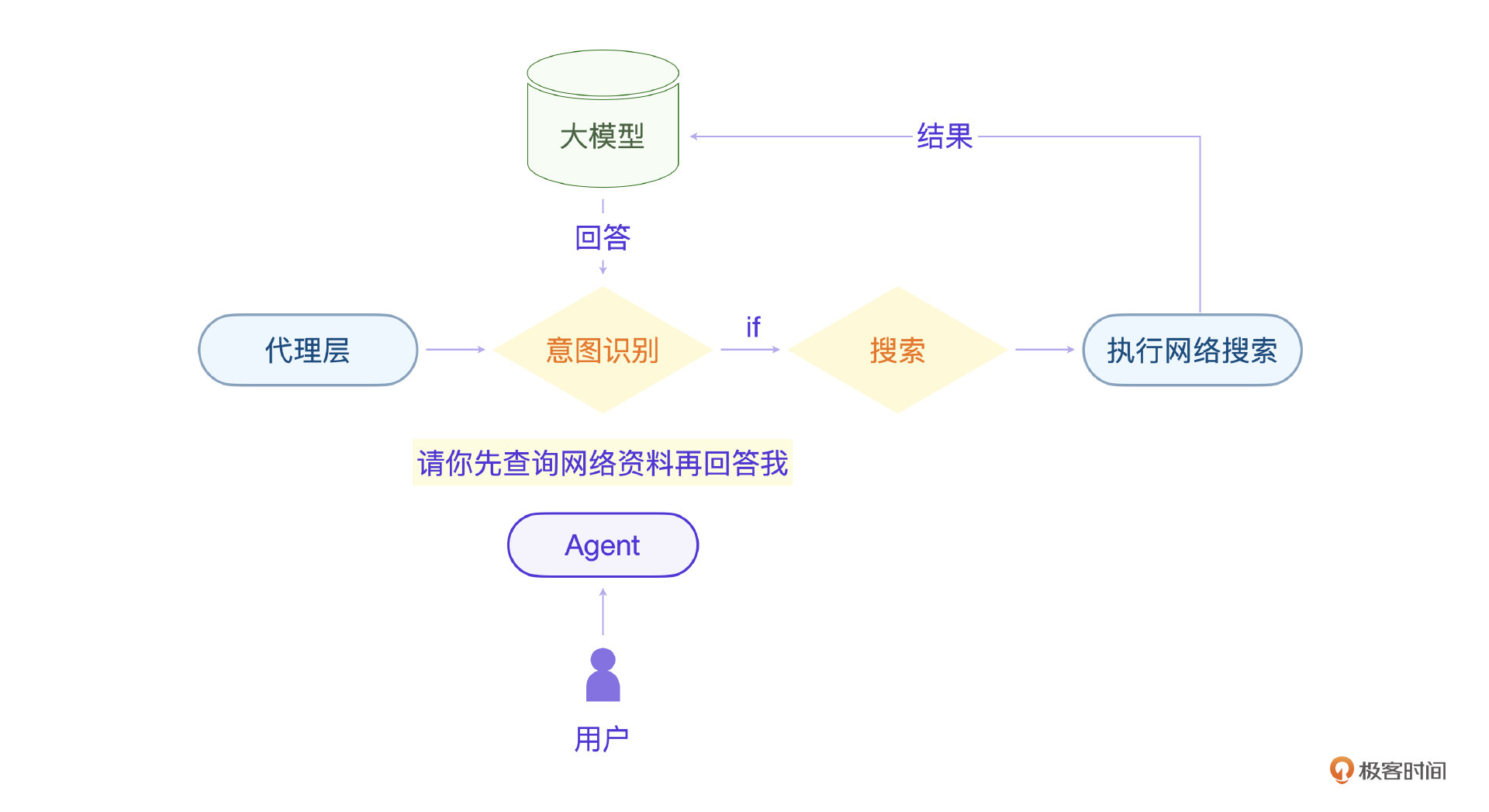
当然,请你先查询网络资料再回答我 这句话还有别的表述方式,比如下面的这些。
1
2
3
4
5
6
7
8
9
10
| 请先通过网络搜索相关资料,然后再回答我的问题。
先查阅一些网络资源,再给我详细解答。
请先在网上找一些资料,然后再为我解答。
先在互联网搜集相关信息,然后再回答我。
请先查找网络上的相关内容,再来回答我的问题。
请先从网上获取相关信息,然后再给出答案。
先通过网络查询一下,再给我提供答案。
请先在网上找到一些相关资料,再来回答我的问题。
请先通过网络查询相关内容,然后再回答我。
请先利用网络搜索相关资料,然后再给出解答。
|
这也就引申出一个问题,就是**意图识别模块必须识别出所有的表述方式。**还有一点需要注意,意图识别还需要具备上下文的识别能力。因为一个意图很可能隐藏在多次的上下文交互中。
当用户的搜索意图被识别之后,代理可以调起插件或工作流。你可以这么理解,大模型的插件能力和Agent平台的插件能力以及工作流没有本质区别,都是让大模型具备额外程序执行能力的一种方法。
比意图识别更重要的还有参数问题。比如上节课的营销AI,在助理聊天交互中,代理层需要根据聊天上下文识别出对应工作流的参数,就是公司名称。
那上面例子里的网络读取插件,输入参数是什么呢?你可以想想。
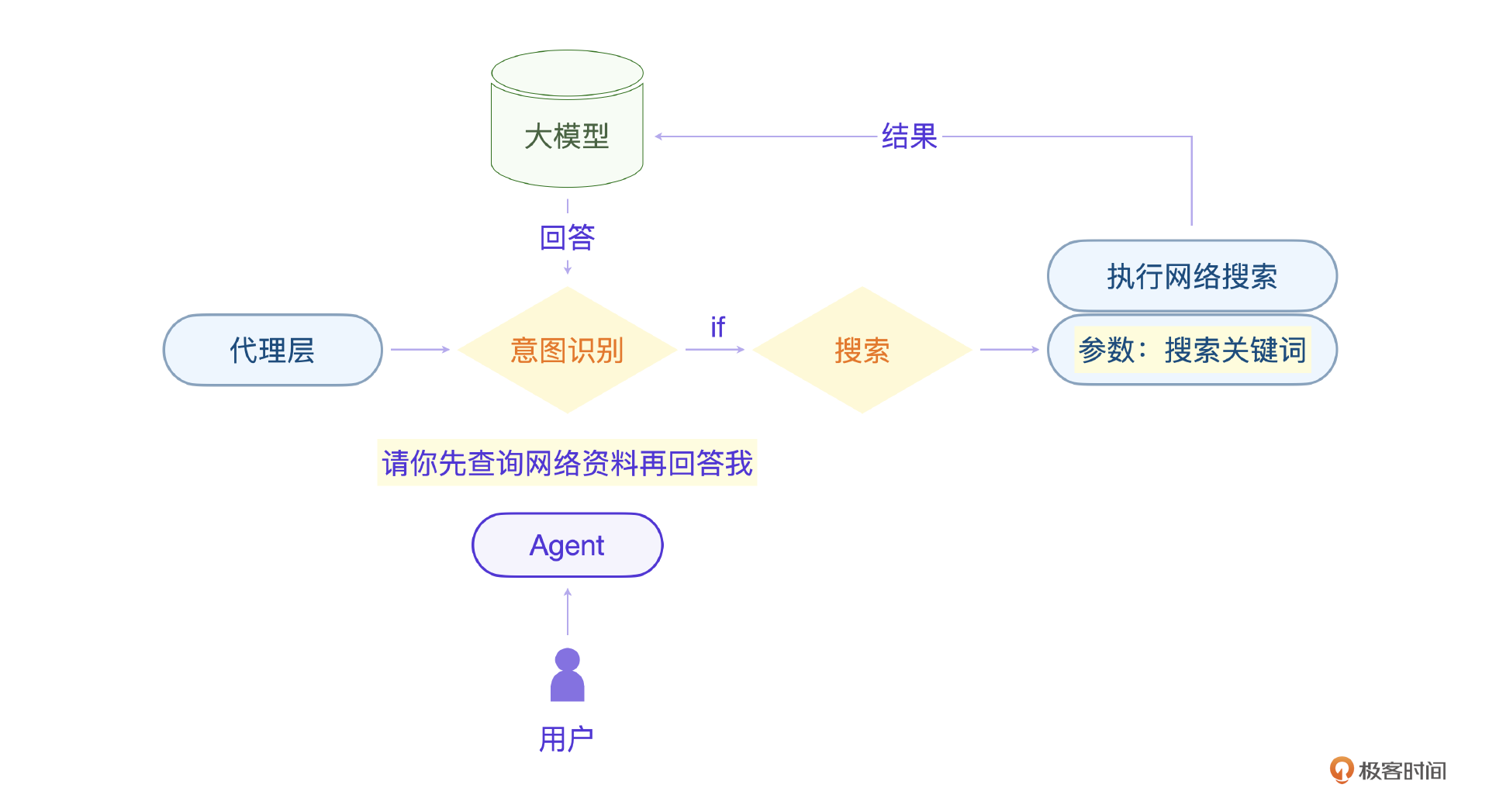
我想你也注意到了,要实现这个Agent的底层,最核心的就是意图识别和参数识别。需要注意,这两个能力都是大模型具备的,我们实现的Agent底层也是用大模型来做意图识别和参数识别。
Agent逆向分析
为了更好地设计这个底层的架构,我在斑头雁平台上写了几个测试用的Agent,专门用于意图识别和参数识别的逆向分析实验。这对理解这两个模块至关重要,你一定要跟着我一步步来做。
下面是我基于Agent平台做的一个读取变量的工作流,看看它的具体工作流代码。
1
| 提示词:把 {{message}} 里的变量名取出,没有就直接输出 "123" 字符串
|
我们可以设计一些case,并测试这个Agent,理解Agent平台的代理模块是如何工作的。
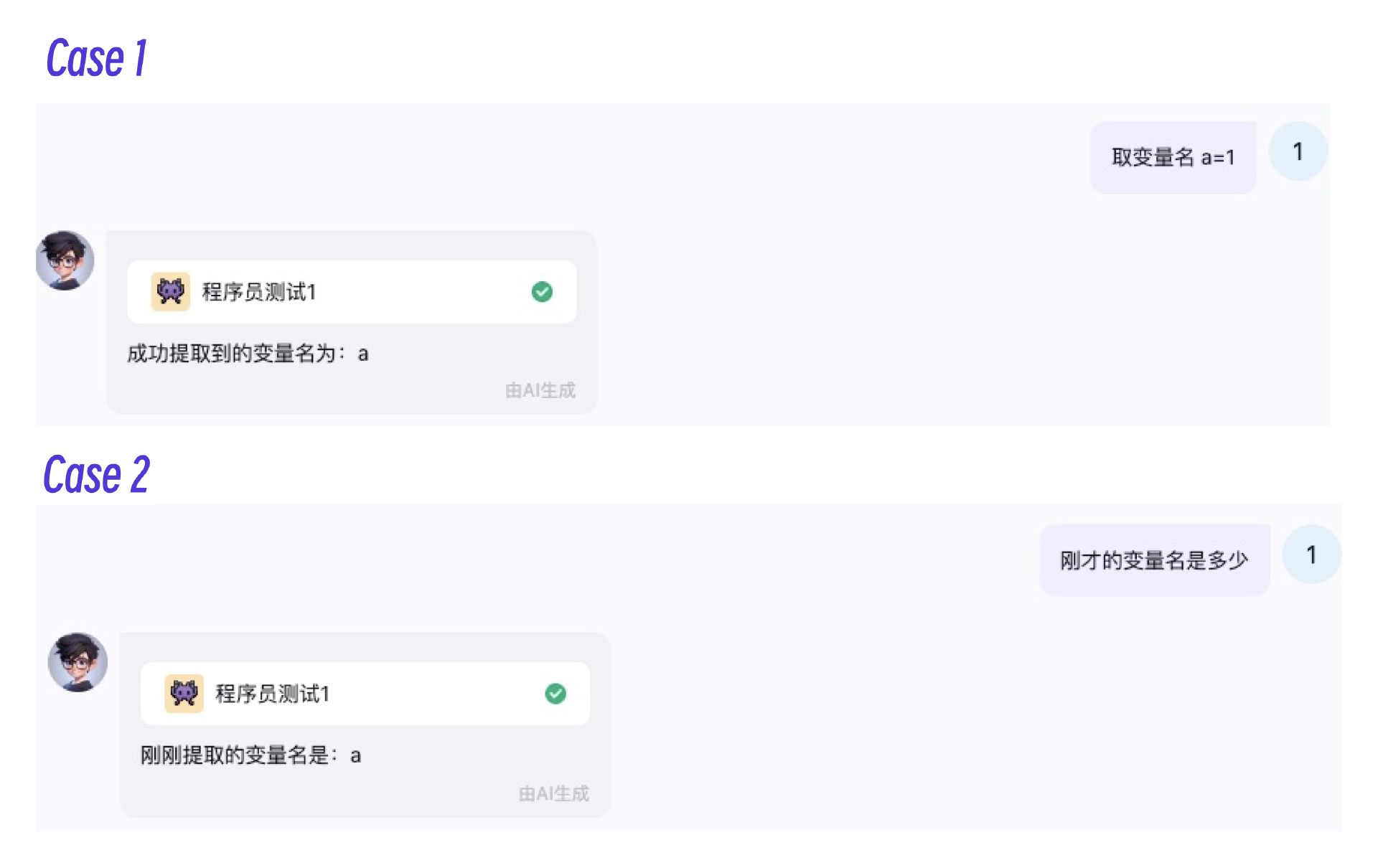
第一个case里,工作流的输入是 取变量名 a=1 这句话,经过LLM的分析,输出的变量名是 a,最后助理给的回复是 成功提取到的变量名为:a。在第二个case里,我们没有输入变量名,但是工作流仍然可以根据上下文提取出刚才的变量名来。
OK,我们可以得出两个结论。一是工作流输出的 a 被返回给大模型重新组织语言,最后才返回给助理。二是代理模块将上下文一起交给了工作流,这样它才能准确识别之前的变量名。
下面通过另外一个工作流的测试,也可以印证这几个结论。
1
2
3
4
| if orderId == "1":
return '您的退换货申请已通过,钱款已按原路径退还'
else:
return '没有查询到'
|
对于的case测试如下,你也可以好好分析一下。
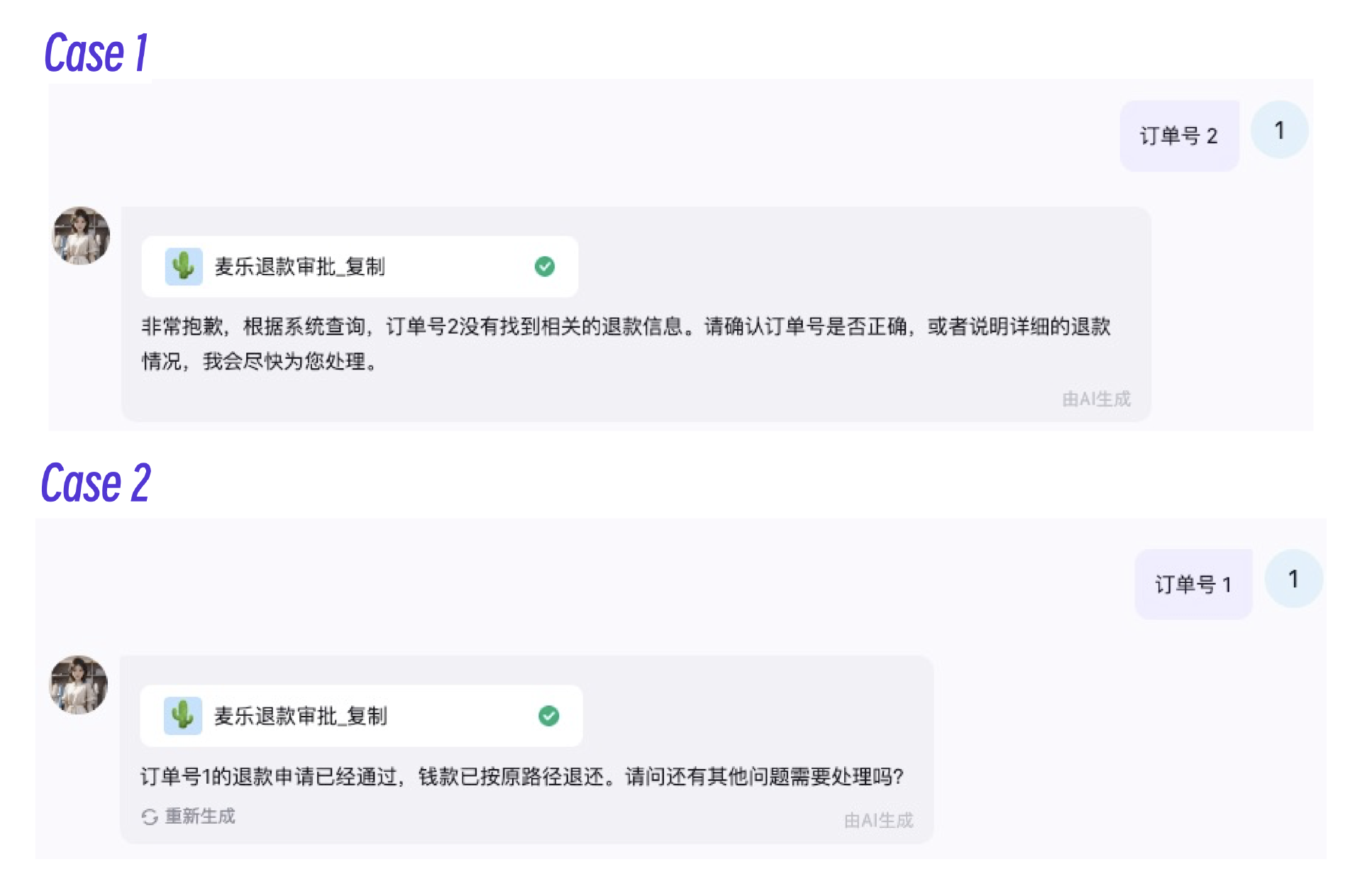
注意看,case 2中助理的最终回复和我Python程序的输出 您的退换货申请已通过,钱款已按原路径退还 是不同的。因此我们可以得出结论,代理层只是参考工作流的输出,具体如何回复客户都是大模型决定的。
这也正符合之前提到的:Agent只是一个公司的客服角色,它的职责是满足客户的需求,并负责沟通,工作流则像公司内部的部门,他们并不直接对外。
最后,我们回想一下上节课的Agent助理,可以配置的部分是不是只有助理提示词和工作流节点的输入输出参数呢?我想告诉你的是,这些配置就是用于让大模型做意图识别和参数识别的。
下面是我做的Agent底层的架构流程图。
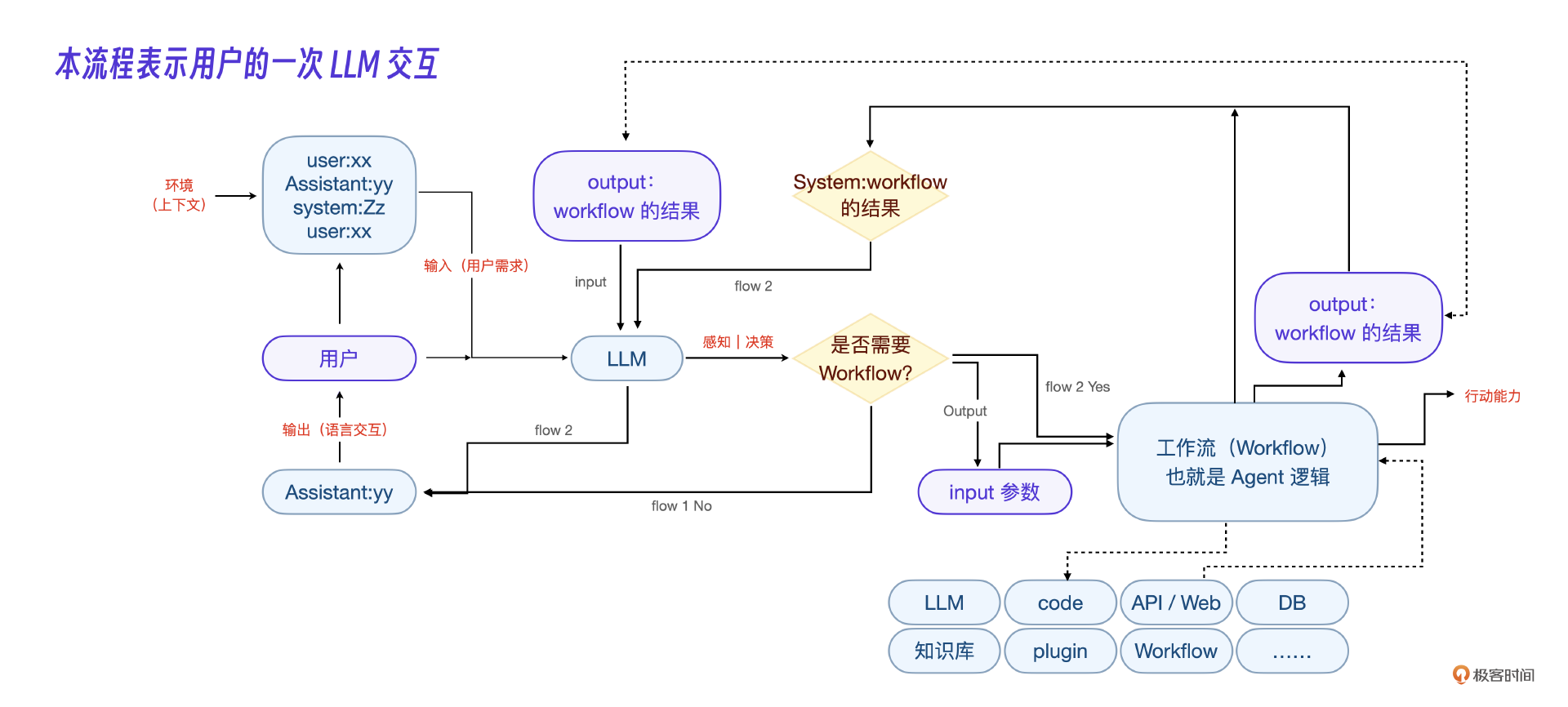
我想这个流程图已经把整个Agent代理层的程序流程做得非常清楚了,你可以代入一次用户的提问好好看一下。
技术实现
最后,我们说技术实现。意图识别和参数识别的具体实现方法有两种,可以通过微调大模型实现,也可以通过提示词实现,思想都是想通的。
下面是一个Demo级别的核心架构代码演示,这个代码就是上述Agent底层架构的核心逻辑实现例子。这个Demo以一个用餐业务为例,分为提示词和核心代码两个部分。理解了这个例子,剩下的一万个Agent也就理解了。
首先是核心提示词。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| 现在有3个角色,sys 代表应用程序系统,user 代表用户,你的角色是一名餐厅服务员,你的目的是服务用户,请你根据上下文决定是否调用 sys应用程序系统。
调用系统则输出 to_sys: 应用程序参数
回复用户则输出 to_user: 回复的消息
规则:
1,要一句一句的和我沟通,每次只能选择和to_sys或to_user其中之一,我会代为转达和处理消息,并且用sys 或 user开头的消息回复你
2,调用程序的具体参数要在上下文中确定,比如我们应用程序有个参数a,上下文里用户或系统没有提供,你就不能擅自决定a的具体数值,调用程序用json格式
3,当我用sys:开头给你回复的时候,表示本次应用程序返回,你要结合这个返回信息继续和用户沟通,你直接用to_user和用户沟通,要注意影藏程序系统这个信息,让用户感知不到
反例:
1,类似下面的回复是错误的,错误原因是在消息里同时出现to_sys 和 to_user
"""
to_sys: {
‘app’ : '点餐应用',
'usernum' : 1,
'caiming' : '包子',
'cainum' : 3
}
to_user: 好的,三个包子已经为您下单了,稍等片刻就会上菜。是否还需要点其他菜品或者饮料呢?
"""
[应用程序列表如下]
1,点餐应用,当用户点餐时调用,
请你和用户沟通确定这些参数:用户人数,菜名(必填),数量(必填)
输出json格式例子:{
‘app’ : '点餐应用', #应用名字(必填)
'usernum' : 1, #用户人数
'caiming' : '包子', #菜名
'cainum' : 5 #数量
}
2,菜单应用,在点餐之前调用,
参数:无
输出json格式例子:{
‘app’ : '菜单应用', #应用名字(必填)
}
3,结账应用,当用户用完餐需要结账时调用,
参数:无
输出json格式例子:{
‘app’ : '结账应用', #应用名字(必填)
}
接下来用to_user给用户开始第一条消息
你的餐厅名字是: 成都小吃
|
我们可分析一下这个核心提示词,有三个层次。
其一是定义角色,提示词里表明了代理、系统、用户三者的关系,让大模型根据上下文来决定具体的回复,这也就解决了意图识别的问题。其二是对 sys 类参数的限定提示词,让大模型按插件和工作流的参数格式来回答。其三是将应用的工作流和具体参数注入提示词,让大模型理解应用。
这段提示词的作用就是告诉大模型我们的具体场景以及助理的具体能力,将上下文交给它处理。需要注意的是,各个插件和工作流的参数都是大模型来组织的,我们给于引导即可。
和提示词对应的Demo程序代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| import json
def deal_app(app, params):
print(">>> " + app)
if app == "菜单应用":
return '菜单 1包子 2饺子 3 可乐或雪碧'
if app == "结账应用":
return '一共消费100元'
if app == "点餐应用":
if 'caiming' not in params or params['caiming'] == None:
return "请先选择菜品和数量"
if params['caiming'] == '面包':
return '面包卖完了'
return "已下单"
return "没有这个应用"
def deal_answer(answer):
if answer.find("to_user:") >= 0 and answer.find("to_sys:") >= 0:
print(answer)
return xf_ai('user', "请不要同时回复to_user 和 to_sys, 两者只能选一个,也不要[等待系统回复]这样的说明", "sys:")
if answer.find("to_sys:") >= 0 and answer.find("\nsys:") >= 0:
print(answer)
return xf_ai('user', "请不要同时回复to_sys 和 sys, 只回复to_sys的数据", "sys:")
if answer.find("to_user:") == 0:
return answer.replace("to_user:", "")
if answer.find("to_sys:") == 0:
# print(answer)
j = answer.replace("to_sys:", "")
j = j.strip()
end = j.find("}")
j = j[0:end+1]
print(j)
jj = json.loads(j)
app = jj['app']
s = deal_app(app, jj)
o = xf_ai('user', s, "sys:请告诉用户:")
return o
# print(answer)
return ""
def get_input_from_command_line():
"""
Get input string from command line using input function.
"""
input_string = input("用户: ")
return input_string
def out_user_message(s):
if s == False:
return
print('服务员:' + s)
if __name__ == '__main__':
o = xf_ai('user', prompt)
out_user_message(o)
while True:
s = get_input_from_command_line()
if s == 'quit':
exit()
o = xf_ai('user', s, "user:")
out_user_message(o)
|
这个程序就是代理层的核心逻辑代码了。整体的思想就是围绕核心提示词构建处理流程,在一般情况下直接回答用户的问题,在工作流状态下调用工作流逻辑,根据返回信息再让模型组织语言回复用户,完成整个交互。
下面是它核心程序流程图。
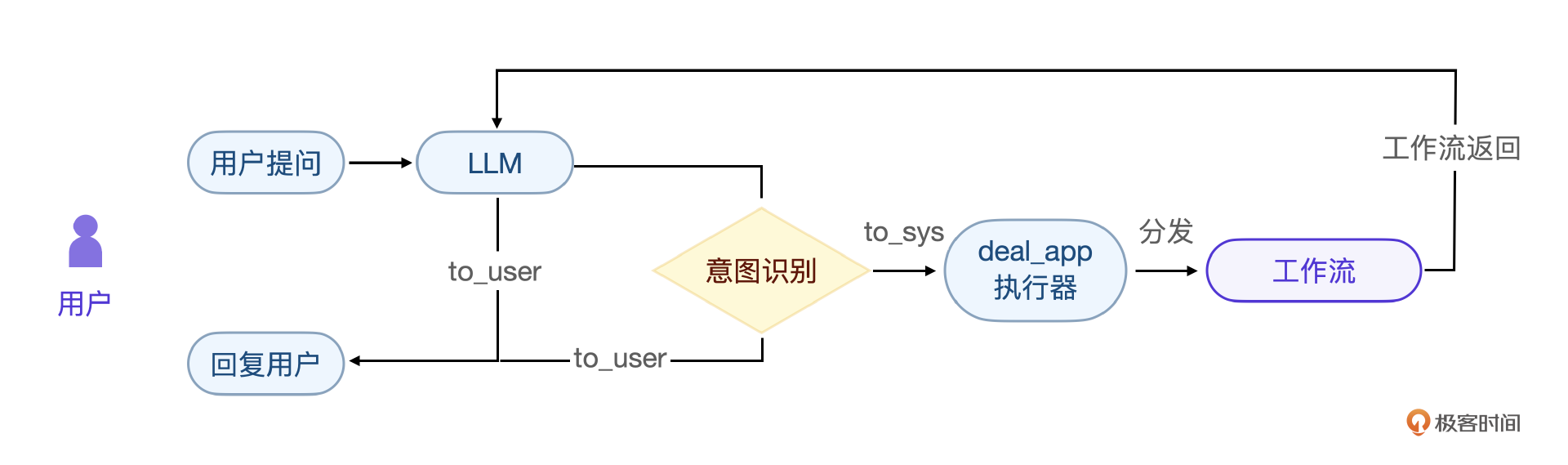
千万不要小看这个提示词和底层Demo,实际上麻雀虽小,五脏俱全。我们整个系统都是在这个基础代码上构建的,你可以把这部分的实现单独作为一个实验来做,一定会对大模型开发有更深入的体会。
如果要更好地理解整套Agent系统,我想可以从我们最终的助理创建界面继续给你分析。
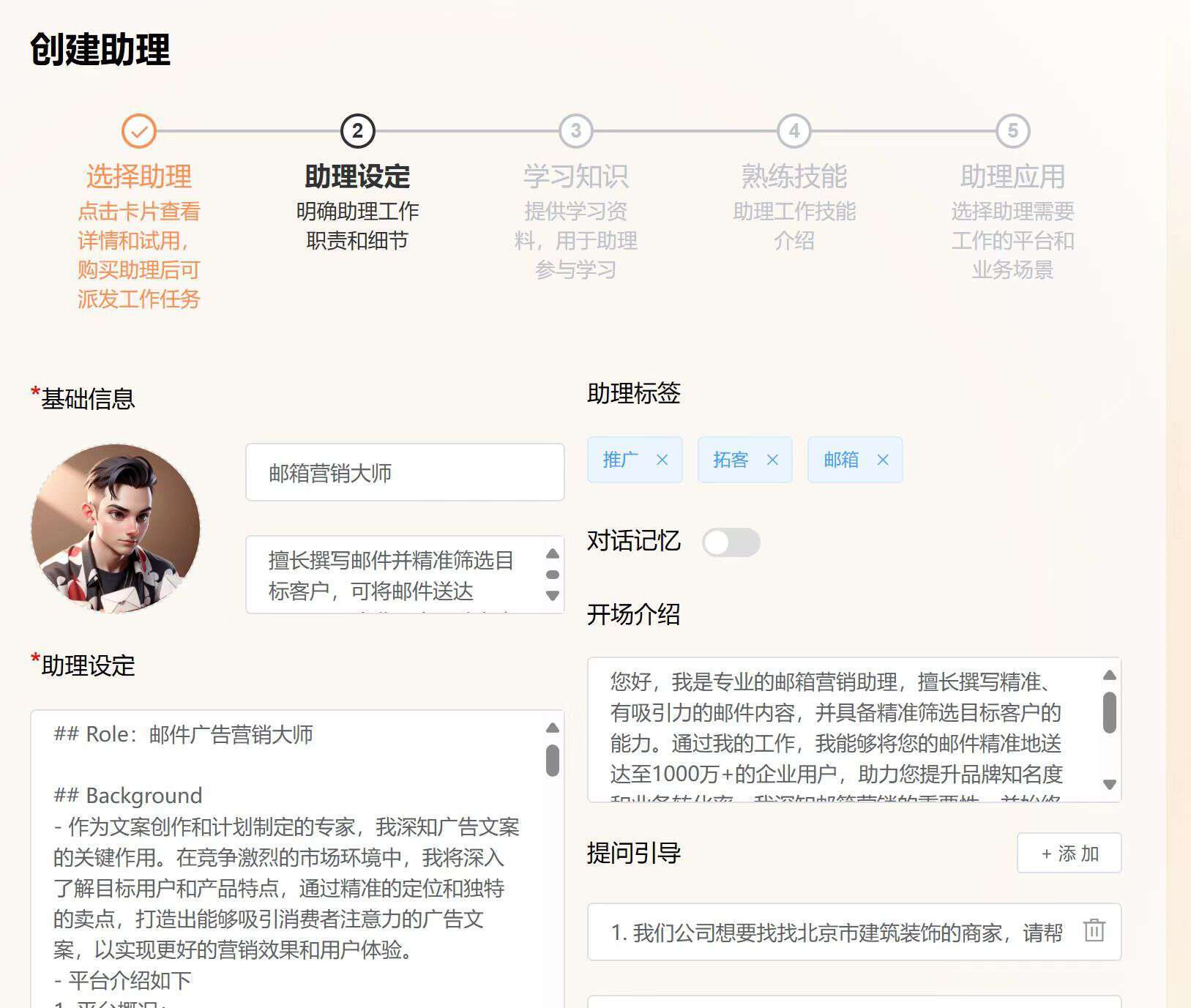
我们的创建助理功能实际分为5步,每一步都必须完成,这是和Coze这类平台不同的,其中最重要的一步就是给每个助理配一个知识库。
应用开发
这里我还是会举一个具体的应用例子,因为我们的底层demo是以餐馆菜单为基础实现的,所以这里我们就继续扩展这个案例,开发一个黄焖鸡点餐大师。
知识库插件
那么显然,菜单数据是它的核心。实际上大部分应用都会用到数据库,这也是我们为什么给每个助理都配置知识库的原因。

要实现这套客户自助配置,如何跟现有系统对接呢?需要分为两部分。其一是数据层面的自助训练,其二是业务逻辑层面的工作流移植。
在数据层面,我们提供了知识库自助训练,这样每个客户都可以拥有一个自己定制化的小模型,保证数据的私有属性。
以一个黄焖鸡餐馆菜单的数据为例,我们看一下私有知识库的搭建流程。
第一步,将菜单数据整理成固定的输入格式,这一步比较简单。
1
2
3
4
5
| {
"1": {"name": "经典黄焖鸡", "description": "鸡肉鲜嫩,配以浓郁酱汁和土豆", "price": "12元", "category": "主菜"},
"2": {"name": "辣味黄焖鸡", "description": "经典黄焖鸡基础上加入辣椒调味", "price": "13元", "category": "主菜"},
"3": {"name": "香菇黄焖鸡", "description": "黄焖鸡加入香菇,风味独特", "price": "14元", "category": "主菜"}
}
|
第二步,将菜单向量化,将类似 item["description"] 这样的本字段转化为向量表示,具体伪代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| from transformers import BertModel, BertTokenizer
import torch
# 使用BERT模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
def get_embedding(texts):
embeddings = []
for text in texts:
inputs = tokenizer(text, return_tensors='pt')
outputs = model(**inputs)
vector = outputs.last_hidden_state.mean(dim=1).detach().numpy()
embeddings.append(vector)
return embeddings
# 读取数据并向量化
with open('huangmenji_menu.json', 'r') as f:
menu_data = json.loads(f.read())
menu_descriptions = [item["description"] for item in menu_data.values()]
menu_embeddings = get_embedding(menu_descriptions)
|
这一步核心是 get_embedding(menu_descriptions) 这个逻辑。它实现的是文本向量的转化,只有转化为向量数据格式才能在向量数据库做后续操作。
第三步,存储和读取向量数据库,这里以 Milvus向量数据库 为例,注意要将菜单信息和向量信息一起存储,具体伪代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| from pymilvus import MilvusClient, FieldSchema, CollectionSchema, DataType, Collection
import numpy as np
# 连接到Milvus
client = MilvusClient(uri="http://localhost:19530", db_name="default")
# 定义集合schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768)
]
schema = CollectionSchema(fields, "黄焖鸡餐馆菜单")
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="IVF_FLAT",
metric_type="IP",
params={"nlist": 128}
)
# 创建集合
collection_name = "huangmenji_menu"
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
# 插入数据
entities = [
{"id": int(item_id),
"name": menu_data[item_id]["name"],
"description": menu_data[item_id]["description"],
"embedding": menu_embeddings[int(item_id)-1].tolist()}
for item_id in menu_data
]
client.insert(collection_name=collection_name, data=entities)
|
整个模块最核心的一行代码其实就是这句 FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768)。你可以把它理解为传统数据库里的索引。加上这个字段后,后续工作流中需要用到菜单时都可以用向量查询,具体查询类似下面的伪代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # 查询向量化输入
query = "我喜欢吃辣,有什么菜品推荐"
query_embedding = get_embedding([query])
# 搜索相似的菜单项
res = client.search(
collection_name=collection_name,
data=query_embedding,
limit=3,
search_params={"metric_type": "IP", "params": {}},
output_fields=['name', 'description']
)
# 显示结果
for result in res:
print(f"Found menu item: {result['name']} - {result['description']}")
|
注意,用户的输入例如 “喜欢辣味的菜品” 可能每个人表述不一样。但是同样需求下,通过向量查询就可以找到相似的菜品信息,这正是向量数据库的核心作用。
如果单独针对一个应用开发这样一个知识库是没问题的,但是我们要做的是让所有助理可以复用一套知识库逻辑,因此在实战中,我们会针对这类逻辑开发一个统一的插件。
下面是这个知识库插件的伪代码表示。
1
2
3
4
5
6
7
8
9
10
11
12
13
| # AI知识库插件
def plugin_ai_knowledge_base_query(query: str, knowledge_base_name: str, field: str) -> str:
"""
输入:
query (str) - 用户查询的问题或主题
knowledge_base_name (str) - 知识库的名称
field (str) - 需要获取的具体字段名称
输出:str - 从知识库中获取的相关信息
"""
# 调用原系统函数获取知识库信息
return original_system_get_knowledge_base_info(query, knowledge_base_name, field)
|
要注意,这里的伪代码已经提供了核心的逻辑,如果你想做这部分实验,完整的代码可以在课后交流群资料中领取。
类似上节课提到的公司信息功能、邮件发送功能、文章生成功能,在营销场景下场景的功能有几十个,我们将原有功能全部转换为了内部Agent插件。
黄焖鸡点餐大师
其实,点餐大师的应用逻辑就是工作流的编排逻辑,只不过在我们的营销Agent项目里,没有实现拖拽开发,而是通过一个简单的yaml配置文件来编排工作流。
先回顾上一节课的工作流编排逻辑的例子。

以黄焖鸡餐馆的菜单推荐需求为例,我们开发一个菜单推荐工作流,用来给门店点餐助理扩展能力。你只需要在yaml配置文件里将工作的前后关系和输入输出配置即可,下面是对应的伪代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| version: '1.0'
name: '菜单推荐工作流'
description: '一个基于用户喜好使用AI知识库和自定义逻辑推荐菜品的工作流。'
steps:
- id: 'input_step'
type: 'input'
description: '获取用户对菜品的喜好'
input:
description: '用户输入的菜品喜好'
example: '我喜欢吃辣,有什么菜品推荐'
output:
name: 'user_preference'
type: 'str'
- id: 'query_knowledge_base'
type: 'plugin'
plugin: 'plugin_ai_knowledge_base_query'
description: '根据用户喜好查询AI知识库中的菜品推荐'
inputs:
query: '{user_preference}'
knowledge_base_name: 'huangmenji_menu'
# 在这里具体化字段的选择
field: 'embedding' # 使用向量数据库的嵌入向量字段进行查询
outputs:
name: 'dish_recommendations'
type: 'str'
- id: 'custom_logic_filter_spicy'
type: 'custom'
function: 'filter_spicy_dishes'
description: '过滤推荐的菜品,仅保留辣味菜品'
inputs:
recommendations: '{dish_recommendations}'
outputs:
name: 'spicy_dish_recommendations'
type: 'list'
- id: 'output_step'
type: 'output'
description: '向用户提供最终的辣味菜品推荐列表'
inputs:
spicy_dishes: '{spicy_dish_recommendations}'
output:
description: '菜品推荐列表'
example: ['麻婆豆腐', '辣子鸡', '四川火锅']
|
在这个工作流配置中,query_knowledge_base 是刚才说的插件能力,在用户上传自己的菜单之后可以直接使用,filter_spicy_dishes 则是我们内部针对菜单这个行业场景开发的菜品推荐逻辑,它可以是基于LLM开发的。
看到这个编排工作流的yaml配置,你可能意识到它没办法和我们的Agent底层Demo直接对接到一起。实际上我们还需要一个统一的、基于yaml配置调度具体工作流逻辑的框架。你也可以自己想一想这部分的逻辑。如果理解了Agent底层的逻辑,这部分相对比较简单,具体代码可以在课后交流群领取。
这里只是借助应用的配置更好地说明Agent底层是怎么工作的。
好,我再来说一个更进一步的配置例子,黄焖鸡营销大师应用。它能根据客户输入的用户标签,自动筛选和发送营销短信。实际上,这个工作流的开发更加简单,只需要通过配置组合现有的插件能力就可以完成,不需要编写代码。其配置文件的伪代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| version: '1.0'
name: '客户营销工作流'
description: '根据用户标签和营销需求进行个性化营销的工作流。'
steps:
- id: 'input_step'
type: 'input'
description: '获取用户标签和营销需求'
input:
description: '用户输入的标签和营销需求'
example:
tag: '潜在客户'
marketing_need: '推广新产品'
output:
name: 'user_tag'
type: 'str'
name: 'marketing_need'
type: 'str'
- id: 'get_user_info'
type: 'plugin'
plugin: 'plugin_user_info_by_tag_get'
description: '根据用户标签获取用户详细信息'
inputs:
tag: '{user_tag}'
outputs:
name: 'user_info'
type: 'dict'
- id: 'generate_marketing_article'
type: 'plugin'
plugin: 'plugin_marketing_article_generate'
description: '生成适合目标用户的营销文章'
inputs:
topic: '{marketing_need}'
audience: '{user_info[preferences]}'
outputs:
name: 'marketing_article'
type: 'str'
- id: 'send_sms'
type: 'plugin'
plugin: 'plugin_sms_send'
description: '发送营销短信给用户'
inputs:
mobile: '{user_info[mobile]}'
subject: '最新产品推荐'
body: '{marketing_article}'
outputs:
name: 'sms_status'
type: 'bool'
- id: 'output_step'
type: 'output'
description: '输出短信发送状态'
inputs:
sms_status: '{sms_status}'
output:
description: '短信发送是否成功'
example: true
|
需要注意,这里的 plugin_sms_send 也是原营销平台的短信功能直接移植的。插件能力足够多的情况下,我们开发工作流的效率会很高。
小结
这节课,我们分析了Agent平台的操作逻辑,设计并实现了一套自有的Agent代理层核心。基于这套核心,我们把原有营销平台的功能全部转化开发了Agent平台的插件能力。
实现营销Agent平台的核心是实现Agent代理层的逻辑,而Agent代理层的核心有两点,一是基于上下文的用户意图识别,二是调用自定义的工作流完成业务逻辑。而最好的上下文意图识别的方案就是大模型。
思考题
如何通过大模型微调让大模型识别到插件能力?相比于提示词的方案,这种方案有什么优势和劣势?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!
>>戳此加入课程交流群