你好,我是徐逸。
在上一节课中,我们深入探讨了如何应对Redis中的热Key问题,并掌握了多种解决方案。然而,在面对高并发的挑战时,我们不仅要关注热Key问题,还必须关注另一个可能影响Redis性能的因素——大Key问题。
今天这节课,我们就来聊聊Redis大Key问题和相应的解决方案。
什么是大Key问题
Redis 作为单线程应用程序,它的请求处理模式类似排队系统,就像下面的图一样,所有请求只能依序逐个处理。一旦处于队列前面的请求处理时间过长,后续请求的等待时间就会被迫延长。
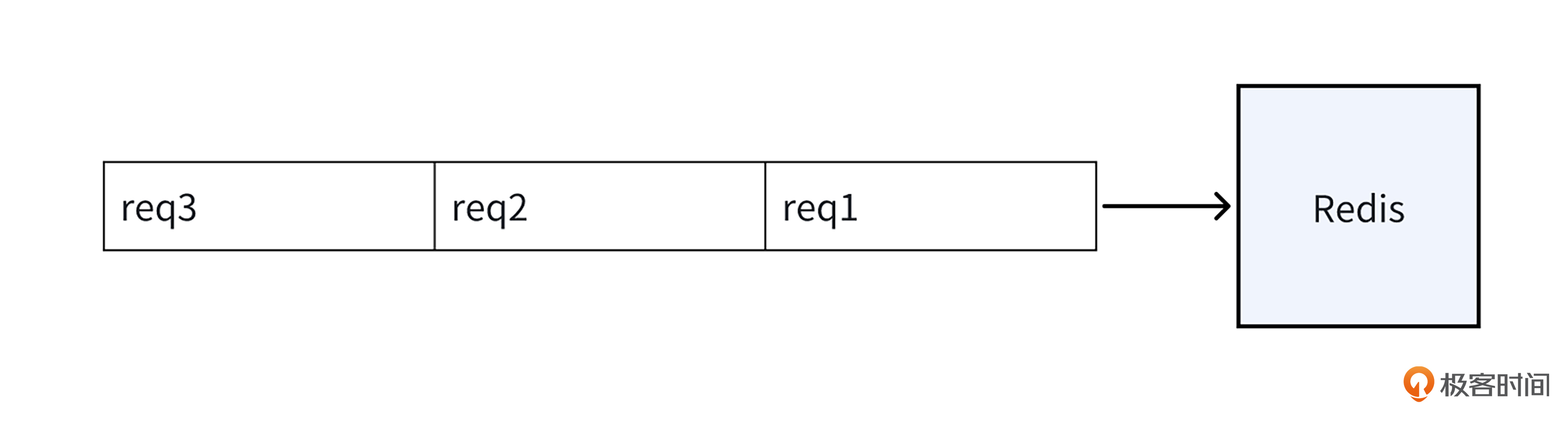
在请求处理过程中,若涉及的键(Key)或键关联的值(Value)数据量过大,Redis 针对这个请求的 I/O 操作耗时以及整体处理时间都将显著增加。
倘若这种情况频繁发生,不仅Redis的吞吐会下降,而且大量后续请求都会因长时间得不到响应,而导致延迟上涨,甚至引发超时。在实际应用场景中,这种现象被定义为 “大 Key 问题”,而那些数据量过大的键(Key)与值(Value)则被称为 “大 Key”。
当然,要判断什么是“大Key”,我们得综合考虑两个因素:Key的大小和Key中包含的成员数量。
不过,对于 Key 究竟要达到多大规模或者包含的成员数量具体为多少才能够被认定为大 Key,实际上并没有一个统一的标准,这个标准得根据你的Redis配置来定。接下来,我给你分享一些阿里云提供的关于大Key的参考标准,这些标准可以作为你判断和处理大Key问题的参考。
- 从Key的数据量来说,一个String类型的Key,如果它的数据量达到5MB,我们就可以认为它是一个“大Key”。
- 从Key成员数量来看,一个ZSET类型的Key,如果它包含的成员数量超过了10,000个,这也符合“大Key”的定义。
- 从Key的成员数据量来看,一个Hash类型的Key,即使它的成员数量只有2,000个,但如果这些成员的Value(值)加起来总大小超过了100MB,那它同样可以被视为“大Key”。
在深入了解了大Key问题之后,我们来探讨一个实际问题:如果在实际应用中,我们不得不将超过大Key标准的数据存储到Redis中,我们应该如何进行优化以规避大Key问题呢?
在实际操作中,我们主要有两种方案可供选择。
- 第一个是数据压缩方案,通过压缩技术减少数据的体积,使其符合大Key的标准,从而减少对Redis性能的影响。
- 第二个是大Key拆分方案,将一个大型的Key拆分成多个小型的Key,这样可以分散单个Key对Redis性能的负担。
这两种思路都能在不同程度上帮助我们减轻大Key问题带来的挑战。接下来,我们就来看看每种方案的具体实施方法。
数据压缩方案
在实际的应用场景中,我们经常需要将数据以JSON字符串的形式存储到Redis中。对于这类数据,如果能在存储前去除JSON中多余的数据,比如JSON里面的Key,那么存储到Redis的数据量就会相应减少。
因此,我们可以利用 Protocol Buffers(PB)等序列化工具对数据进行预处理,然后再存储到Redis中。这样做可以显著减少存储在Redis中的数据大小,降低出现大Key问题的风险。
以下面代码中的JSON字符串为例,如果我们直接将其存储到Redis中,所占的字节大小为94字节。
1 | func main() { |
而如果我们使用下面的PB文件格式,情况就有所不同了。
1 | syntax = "proto3"; |
按下面的代码进行序列化,存储到Redis的数据将显著减少,变成了41字节。和直接存入JSON字符串相比,数据大小降低了50%以上。
1 | func main() { |
尽管我们可以通过PB序列化来减少存储到Redis的数据大小,但如果PB序列化后的数据仍然较大,或者不适合使用PB序列化的情况,比如Value不是JSON形式,我们又该怎么办呢?
大Key拆分方案
这个时候,我们就可以采用大Key拆分方案。所谓大Key拆分,是指将一个Key的数据,拆分成多个小块,每个小块存入不同的Redis Server里,从而避免单个Redis Server处理大Key的压力。你可以参考后面的示意图来理解。
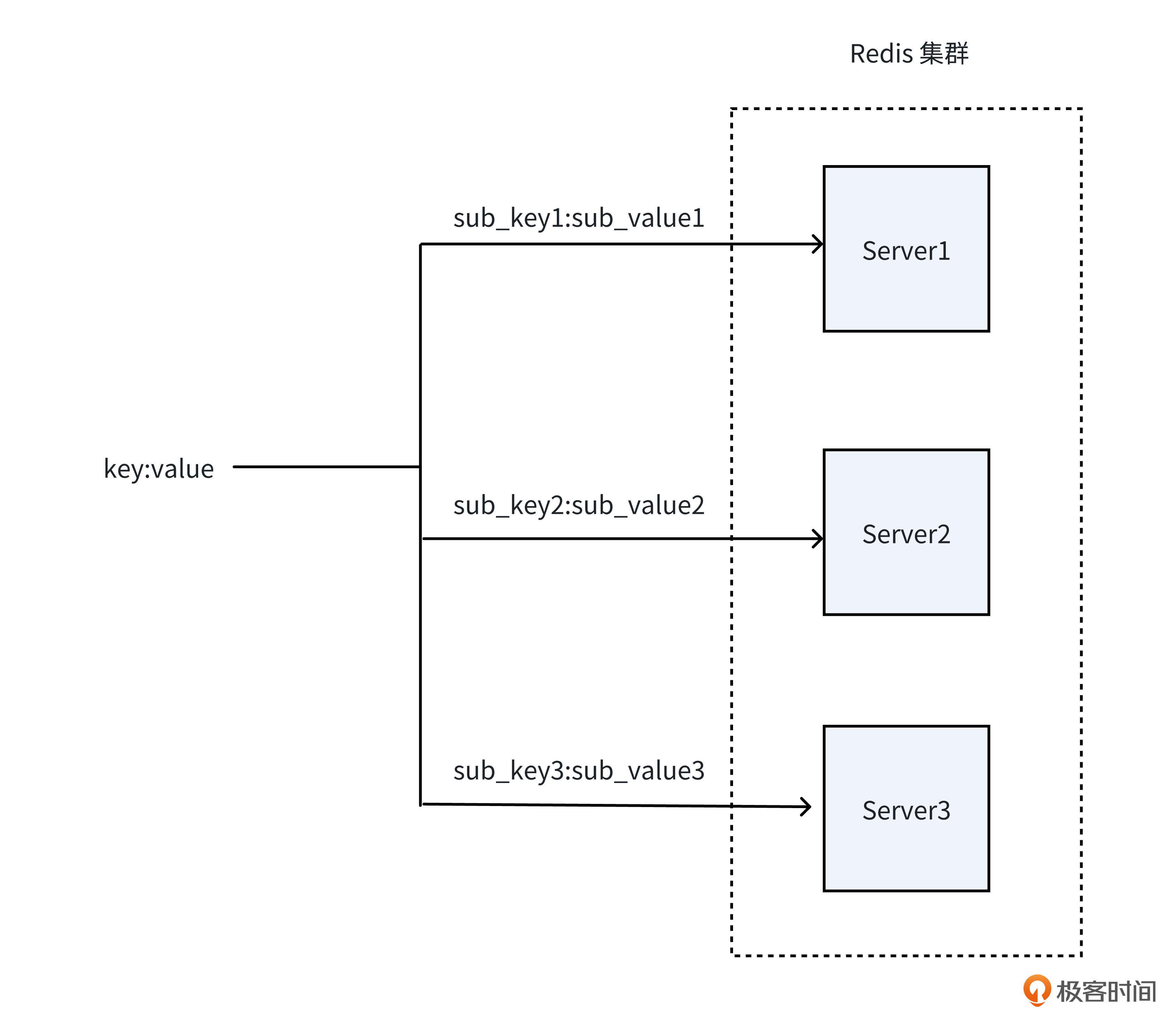
对于大Key的拆分,不同团队可能会有不同的实现思路。然而,这些方案都存在一个核心难点,即如何有效规避脏读现象。
举例来说,正如下方的图里呈现的那样,当新数据写入sub_key1,但尚未更新sub_key2 时,如果有读Redis的请求,就有可能读取到旧的sub_key2 数据与新的sub_key1数据,进而拼接出一个在实际中并不存在的数据,这会给数据的准确性和可靠性带来极大的负面影响。
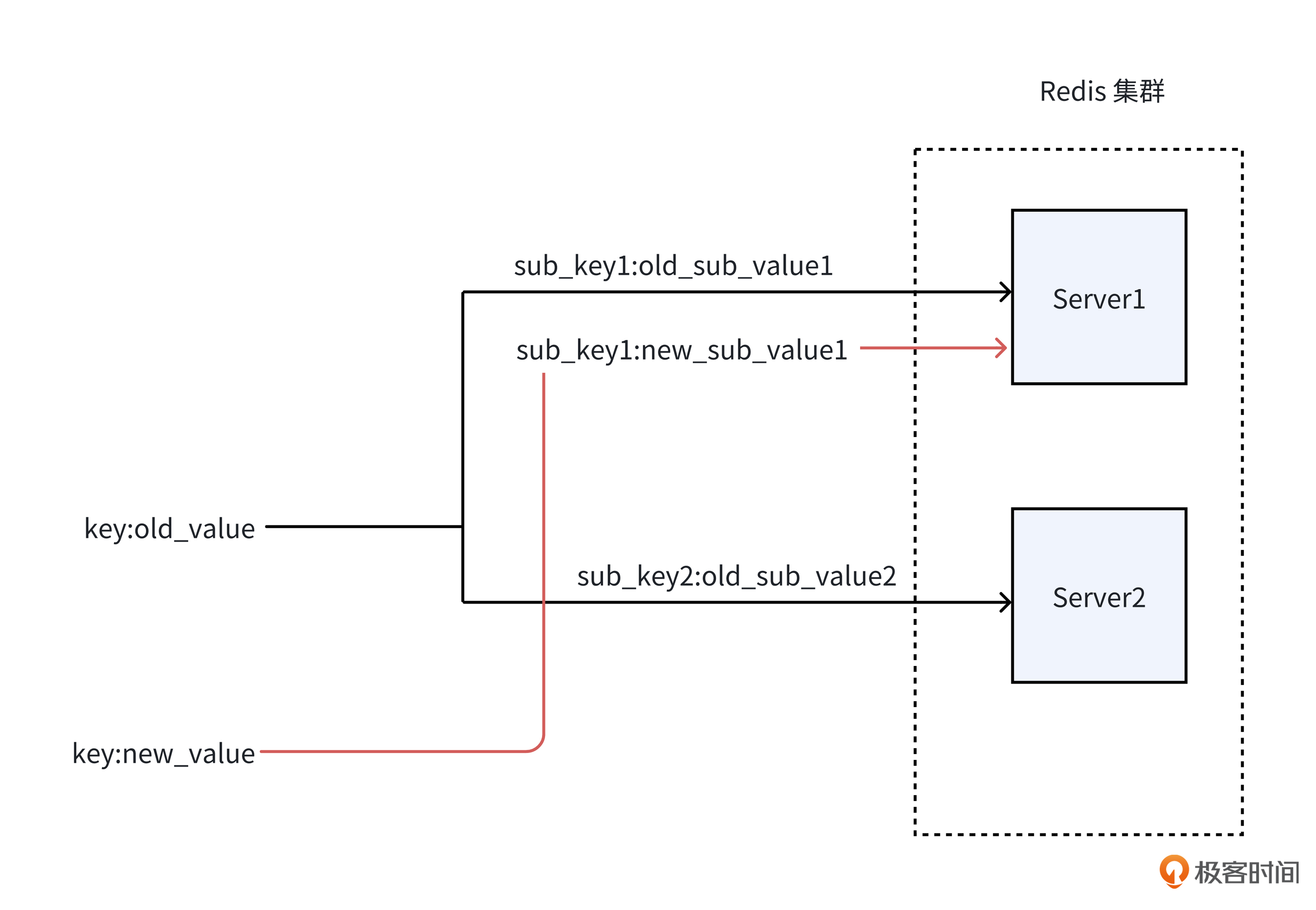
那我们该如何拆分大Key才能防止脏读呢?
这里我们来学习一种在实际应用中较为通用的大 Key 拆分方案。它的核心设计理念在于巧妙借助版本号这一机制,而非采用直接覆盖原始数据的做法,从而达成有效防止脏读的目的。
就像下面的代码展示的一样,这个方案对大Key进行拆分,并写入Redis的关键流程如下。
- 首先,对于大Key,我们需要对数据进行 MD5 运算,并提取运算结果的后 6 位作为本次数据的特定版本号。
- 接着,我们按字节大小做拆分,子Key拼接上版本号,避免直接覆盖之前的数据,导致脏读。
- 然后,我们更新Key的元数据信息,元数据信息里记录了子Key信息,从而使线上生效。
- 最后,我们需要给旧子Key设置过期时间,而不是直接删除,避免有Client正在读旧子Key数据。
1 | // 数据元信息 |
看完大Key写入,现在让我们看看大Key读取的关键流程。
- 首先,我们需要根据查询的Key,从Redis获取包含子Key的元数据信息。
- 接着,我们需要根据子Key,获取各个子Key的数据。
- 最后,把获取的子Key数据拼接起来,就得到了我们需要的完整大Key数据。
下面是读取的代码,供你参考。
1 | // 从Redis获取数据 |
小结
今天这节课,我们讨论了大Key问题,并提出了两种有效的解决方案。现在,让我们一起回顾下这两个方案。
首先是基于PB序列化的数据压缩方案。在将数据存储到Redis时,我们很多时候会使用JSON格式。通过改用PB序列化,我们可以避免不必要的数据写入,从而有效减少数据体积,预防大Key问题的发生。
其次是基于版本号机制的大Key拆分方案。在数据经过压缩后,如果它的大小仍然超出了大Key的标准,我们就可以采用这一方案。通过将数据拆分成多个部分,并为每个部分添加版本号作为子Key,我们可以有效避免因拆分操作而可能引发的脏读问题。
希望你好好体会这两个方案。在未来遇到大Key问题时,不妨考虑运用这些方案来有效解决问题。
思考题
在实践中,面对大Key问题,你还有哪些解决方式呢?
欢迎你把你的答案分享在评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!