你好,我是独行。
前面我们学习了机器学习的基本概念,了解了几个常见的经典算法,这节课我们继续为了解大语言模型的基本原理做准备,学习自然语言处理(NLP)的基本概念。
大语言模型的爆发,从技术层面讲应该是机器学习和自然语言处理技术的双重突破,所以我们会花一节课的时间,来讲解NLP相关的知识。
NLP基础
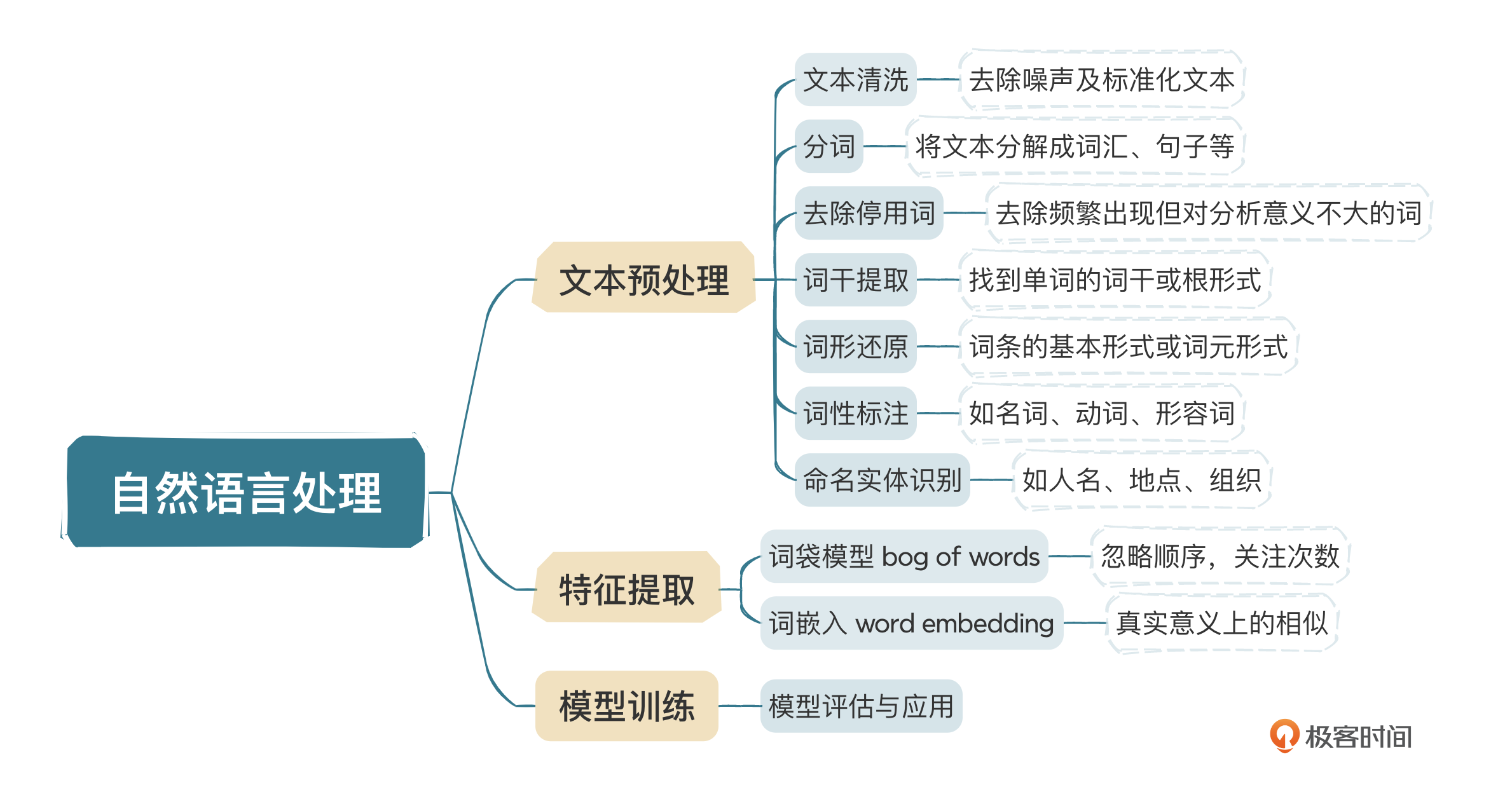
NLP是人工智能的一个重要分支,研究的目的是让计算机能够理解、解释和生成人类语言。NLP结合了计算机、人工智能和语言学等多个学科的方法,尽可能缩小人类语言与计算机理解之间的差距。一般来说,包含四个步骤。
- 文本预处理:将原始文本转换成易于机器理解的格式。包括分词(将文本分解成单词或短语)、去除停用词、词干提取、词性标注等。
- 特征提取:从处理过的文本中提取特征,以便用于机器学习模型。这通常涉及将文本转换为数值形式,如词袋模型或词嵌入Word Embedding,也就是向量化。
- 模型训练:使用提取的特征和相应的机器学习算法来训练模型,可能是分类器、回归模型、聚类算法等。
- 评估与应用:评估模型的性能,并在实际应用中使用模型来解释、生成或翻译文本。
NLP的应用场景非常广泛,搜索引擎、语音转换、文本翻译、系统问答等几乎覆盖我们生活的方方面面。下面我们一步一步去学习一下相关的技术,首先就是文本预处理。
文本预处理
文本预处理是NLP中的一项基础且关键的步骤,目的是将原始文本转换成易于机器理解和处理的格式。这一步骤通常涉及多个不同的任务,具体包括以下几个步骤。
文本清洗
文本清洗主要包括去除噪声及标准化文本等。去除噪声是指清除文本中对分析无关紧要的部分,比如HTML标签、标点符号、特殊字符等。你可以参考我给出的示例代码。
1 | import re |
输出:
1 | Hello World Heres a link |
分词
将文本分解成词汇、句子等。
1 | from nltk.tokenize import word_tokenize |
输出:
1 | ['Natural', 'language', 'processing', '(', 'NLP', ')', 'is', 'a', 'field', 'of', 'computer', 'science', '.'] |
去除停用词
停用词是文本中频繁出现但对分析意义不大的词,如is、and等。去除它们可以提高处理效率和分析效果,同时还可以使数据集变小。
1 | from nltk.corpus import stopwords |
输出:
1 | {"you'd", 'just', 'shouldn', 'here', 'as', 'mightn', "wasn't", 'him', 'have', 'you', 'an', 'not', 'mustn', 'ma', 'o', 'myself', 'what', 'was', "shouldn't", 'during', 'wouldn', 'no', "mightn't", 'weren', "don't", 'those', 'having', 'off', "hasn't", 'that', 'did', 'very', 'now', 'couldn', 'shan', 'the', 'hasn', 'if', 'do', "weren't", 'on', 'after', "you've", "she's", 'i', 'y', 'didn', 'at', 'it', 'too', 'until', 'or', 'his', 'we', 'wasn', 'about', 'same', 'won', 'd', "isn't", 'below', 'our', 'for', 'while', 'its', "couldn't", 'isn', 'ours', 'between', 'which', 'aren', 'my', 'once', 'of', 'from', 'each', "should've", 'so', "aren't", 'and', "didn't", 'haven', "you're", 'needn', 'is', 'll', 'will', 'these', 'again', 've', 'be', 'over', 'nor', 'why', 'are', 'then', 't', 'm', 'where', 'other', "needn't", 'theirs', "mustn't", 'ain', 'more', 'to', 's', 'can', 'through', 'than', 'both', 'above', 'were', "shan't", 'any', 'their', 'such', 'don', 'into', 'themselves', 'there', 'some', 'with', 'himself', 'hers', 'me', 'them', 'who', 'am', 'only', 'out', 'yourselves', "that'll", 'when', 'down', 'further', 'herself', 'but', "doesn't", 'does', "hadn't", "won't", 'her', 'whom', 'has', 'in', 'doesn', "haven't", 'before', "wouldn't", 'should', 'yourself', 'a', 'yours', 'itself', 'because', 'he', 'been', "you'll", 'she', 'few', 'by', 'being', 'hadn', 'they', 'how', 'own', "it's", 'up', 'ourselves', 'doing', 'against', 'most', 'your', 'all', 'had', 'under', 're', 'this'} |
稍微解释一下,第11行 stop_words = set(stopwords.words('english')),就是从停用词库取出英文相关的停用词,放到set集合中,之后就是对原始文本降噪、标准化,最后通过和停用词库比较,把标准化后文本中的停用词去掉。
词干提取
词干提取是去除单词的词缀(如前缀和后缀),以便找到单词的“词干”或“根形式”。这个过程是启发式的,可能不会返回一个真实的单词,而是返回单词的一个截断形式。例如,running、runs和runner经过词干提取后可能都会被简化为run。词干提取可以减少词形变化的影响,使相关的单词能够在分析时被归纳为相同的形式,有助于简化文本数据,并提高文本处理任务的性能。我们看一个简单的示例。
1 | import nltk |
运行结果如下:
1 | 原始文本: |
词形还原
词形还原是将单词还原到它的词典形式,也就是词条的基本形式或词元形式。与词干提取相比,词形还原考虑了单词的词性,并尝试进行更加精确地转换,返回的是一个真实的单词。例如,am、are和is经过词形还原都会变为be。词形还原能够准确地将单词还原到其标准形式,有助于保持语义的准确性。这在需要精确理解和分析文本意义的场合特别有用,如在语义分析或深入的文本理解任务中。
1 | from nltk.stem import WordNetLemmatizer |
程序运行结果:
1 | 原始文本: |
词性标注
词性标注是指将文本中的每个单词或符号标注为相应的词性如名词、动词、形容词等。这一过程可以揭示单词在句子或语言结构中的作用和意义。
命名实体识别
命名实体识别是识别文本中具有特定意义的实体,如人名、地点、组织、日期、时间、货币数额等,旨在识别出文本中的实体,并将它们归类为预定义的类别。
我们通过一个代码示例看一下。
1 | import spacy |
程序运行结果如下:
1 | ('Apple', 'PROPN') |
实际上文本预处理有很多种任务,要根据实际情况决定。这取决于我们拿到的文本和希望处理成什么样,比如去除数字、去除特殊符号等,上面讲的这几种是比较常见,且比较通用的。当文本预处理完成后,我们一般就要进行特征提取了。
特征提取
特征提取是NLP中的一个重要步骤,它涉及将原始文本转换成可以被机器学习模型理解和处理的数值形式。在文本数据中,特征提取是挑选出反映文本特性的信息,将其转化为一种结构化的数值表示。这一步骤对于提高模型性能至关重要,因为机器学习算法通常无法直接处理原始文本数据。简单而言,机器学习算法没办法直接处理原始文本,只能先挑出来主要信息,然后将主要信息用计算机能懂的方式进行表达,比如向量化。下面我来介绍两种常见的方式。
词袋模型(Bag of Words,BoW)
词袋模型比较简单,忽略了文本中单词的顺序,仅仅关注每个单词出现的次数。在这个模型中,每个文档被转换成一个长向量,向量的长度等于词汇表中单词的数量,每个单词分配一个固定的索引。向量中的每个元素是该单词在文档中出现的次数。举一个例子:
1 | from sklearn.feature_extraction.text import CountVectorizer |
程序运行结果如下:
1 | ['analysis' 'data' 'for' 'fun' 'great' 'is' 'python' 'science' 'text' |
第一行输出表示所有文档中至少出现过一次的唯一单词。CountVectorizer按照字母顺序排列这些单词,并为每个单词分配了一个特定的索引位置。第二部分是文档的向量表示,它是一个4x10的矩阵,因为我们有4个文档和10个唯一单词。每一行代表一个文档,每一列代表词汇表中的一个单词。
第一行对应第一个文档 "Text analysis is fun",analysis出现1次,text出现1次,is出现1次,fun出现1次,其他单词在该文档中没有出现。这种表示方法比较简单,因为单词没有顺序,所以就会部分失真,对原文语义的理解不足,而词嵌入进一步解决了这个问题。
词嵌入(Word Embeddings)
我们在之前的课程里介绍过词嵌入,你回想一下。当时我说,男人和男孩,男人和国王,在某些属性上有很强的相似度,所以基于词嵌入产生的检索是真实意义上的相似。词嵌入是文本的一种表现方式,将词汇映射到实际向量空间中,同时可以捕获语义关系,我们通过下面这个例子来看一下。
1 | from gensim.models import Word2Vec |
程序运行结果如下:
1 | [['the', 'cat', 'sat', 'on', 'the', 'mat', '.'], ['dogs', 'and', 'cats', 'are', 'enemies', '.'], ['the', 'dog', 'chased', 'the', 'cat', '.']] |
这是通过gensim库训练出来的一个Word2Vec模型,设置了100维向量,单词cat最终通过一个100维的向量来表示,怎么理解这个100维度呢?可以有两种解释。
- 数学角度:一维二维三维我们容易理解,比如一个变量H在三维空间中的表示就是(x,y,z),x表示在一维空间变量H的坐标值,y、z分别表示在二维、三维空间变量H的坐标值,同理,cat的向量就是在100维空间的表示方式。那这些值分别代表什么呢?让我们来看第二种解释。
- 语义特征:我们可以理解为cat有很多个属性,我们这里强制使用100个属性来描述cat,比如性别、体重、头的大小、四肢长度、毛色等等,相信这样的属性可以列举无数个。假设第一个属性表示性别,第二个属性表示体重,依次类推,就可以分别表示这100个属性的值。当我们进行相似度比较的时候,如果有其他动物有很多属性都和cat差不多,那我们就可以认为它们很相似。这里你先理解一下大致的概念,后面我会用专门的一节课来讲解Word2Vec,到时候我们再深入学习。
看到这里你可能就要问了,NLP到底和机器学习有什么关系呢?简单来说,NLP就像是教会计算机理解和使用人类语言的学问,而机器学习则是让计算机通过查看大量的例子自己学习如何完成任务的方法。把两者结合起来,就是用机器学习的技术来让计算机学习如何处理和理解语言。这样,计算机就可以帮我们做一些翻译语言、回答问题或者理解文本情感的任务了。
模型训练
模型训练类似于教孩子学会解决问题的过程。
首先,我们丢给计算机大量的例子,也就是数据集,这些例子包含了正确的答案。计算机开始通过这些例子去尝试学习,就像孩子通过做数学题来理解加减法一样。一开始,计算机可能会犯很多错误,但随着不断地尝试和学习,它开始识别数据中的模式和规律。
我们会用一些没有见过的新例子来检测计算机学到了多少,这就像是给孩子一个新的数学测验。如果计算机在这些新例子上也能做得很好,这意味着它已经学会了如何解决问题。整个过程中,我们通过调整计算机学习的方式,也就是算法的参数,帮助它更好地理解和解决问题。
最后,当计算机能够准确快速地解决我们给它的问题时,就说明模型已经被训练好了。这个训练过程是机器学习的核心,使计算机能够自动并有效地处理和分析大量数据。
评估与应用
当模型训练好后,需要进行测试及评估,评估的目的是衡量模型的性能和准确性,确保它能够可靠地完成既定任务。一般通过将模型的预测结果与实际结果进行比较来实现。有不同的性能指标来评估模型,包括准确率、精确率、召回率、F1分数等,具体取决于任务的性质(分类、回归等)。如果模型经过评估满足标准,就可以放到实际应用中去解决问题了。
在模型部署后,我们依然需要持续监控其性能,确保随着时间推移和数据变化,模型依然有效。必要时,模型需要基于新数据或反馈进行重新训练和更新。
整个过程是一个迭代的循环:从理解问题,到数据准备,模型训练,还有评估,最后是应用。实践当中,模型可能需要多次的迭代训练与评估,这样可以优化它的性能和适应性。评估和应用的阶段,是确保模型能解决现实世界问题的关键所在,直接关系着项目是否成功。
关于模型的训练和评估,我们在Word2Vec部分会继续深入讲解。
小结
这节课我们主要学习了自然语言处理(NLP)相关的基本概念,结合之前学习的机器学习的基本概念,可以算是入门了,如果拿学习Java来举例的话,我们应该是把类、变量、数据类型、接口等概念看完了,后面就是实操了。最后我们通过一张脑图回顾一下这节课学到的知识。
后面我们会进入实操部分,学习Word2Vec这个模型,深入理解自然语言处理的原理。
思考题
假设你手上有一个文本库,是某个明星近10年发的微博的集合,你需要通过NLP方法,识别出哪些博文包含“打车”?你打算怎么设计?欢迎你在评论区留言讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见。