你好,我是独行。
上节课我们一起学习了Word2Vec,Word2Vec的主要能力是把词汇放在多维的空间里,相似的词汇会被放在邻近的位置。这节课我们将进入Seq2Seq的领域,了解这种更为复杂且功能强大的模型,它不仅能理解词汇,还能把这些词汇串联成完整的句子。
Seq2Seq
Seq2Seq(Sequence-to-Sequence),顾名思义是从一个序列到另一个序列的转换。它不仅仅能理解单词之间的关系,而且还能把整个句子的意思打包,并解压成另一种形式的表达。如果说Word2Vec是让我们的机器学会了理解词汇的话,那Seq2Seq则是教会了机器如何理解句子并进行相应地转化。
在这个过程中,我们会遇到两个核心的角色:编码器(Encoder)和解码器(Decoder)。编码器的任务是理解和压缩信息,就像是把一封长信函整理成一个精简的摘要;而解码器则需要将这个摘要展开,翻译成另一种语言或形式的完整信息。这个过程有一定的挑战,比如如何确保信息在这次转换中不丢失精髓,而是以新的面貌精准地呈现出来,这就是我们接下来要探索的内容之一。
基本概念
Seq2Seq也是一种神经网络架构,模型的核心由两部分组成:编码器(Encoder)和解码器(Decoder)。你可以看一下这个架构的示意图。
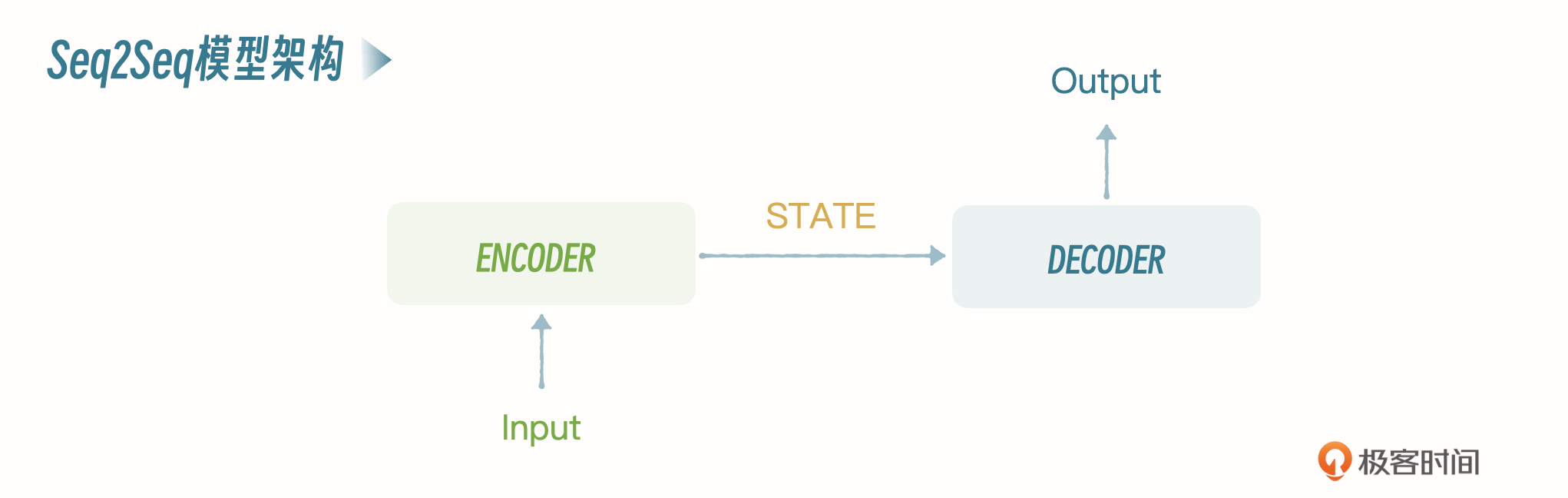
编码器
编码器的任务是读取并理解输入序列,然后把它转换为一个固定长度的上下文向量,也叫作状态向量。这个向量是输入序列的一种内部表示,捕捉了序列的关键信息。编码器通常是一个循环神经网络(RNN)或其变体,比如长短期记忆网络(LSTM)或门控循环单元(GRU),它们能够处理不同长度的输入序列,并且记住序列中的长期依赖关系。
解码器
解码器的任务是接收编码器生成的上下文向量,并基于这个向量生成目标序列。解码过程是一步步进行的,每一步生成目标序列中的一个元素,比如一个词或字符,直到生成特殊的结束符号,表示输出序列的结束。解码器通常也是一个RNN、LSTM或GRU,它不仅依赖于编码器的上下文向量,还可能依赖于自己之前的输出,来生成下一个输出元素。
注意力机制(可选)
在编码器和解码器之间,可能还会有一个注意力机制(Attention Mechanism)。注意力机制使解码器能够在生成每个输出元素时“关注”输入序列中的不同部分,从而提高模型处理长序列和捕捉复杂依赖关系的能力。编码器、解码器、注意力机制之间是怎样协作的呢?你可以看一下我给出的示意图。
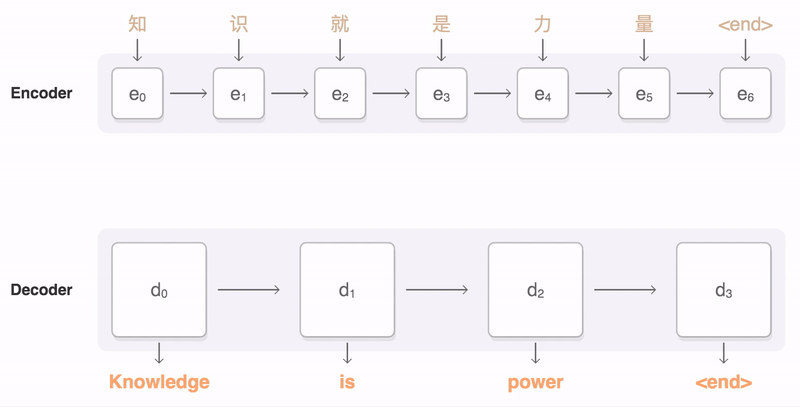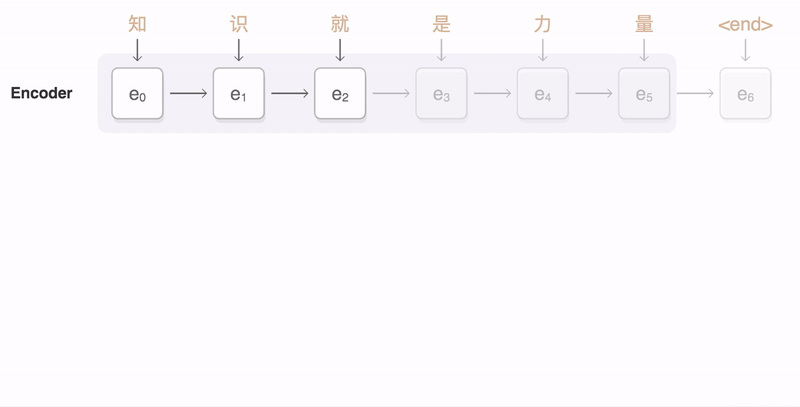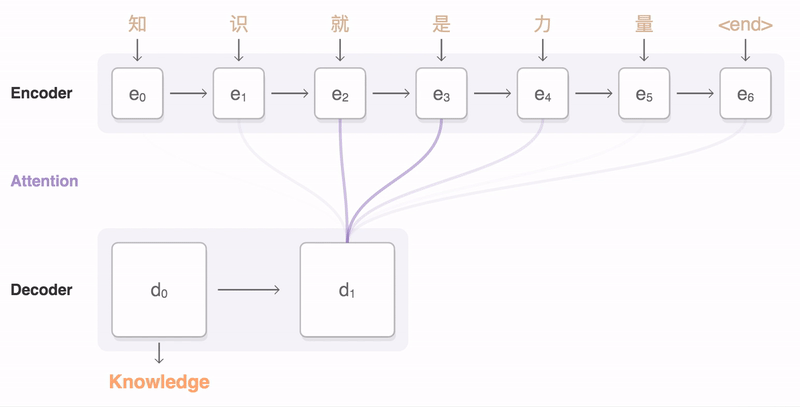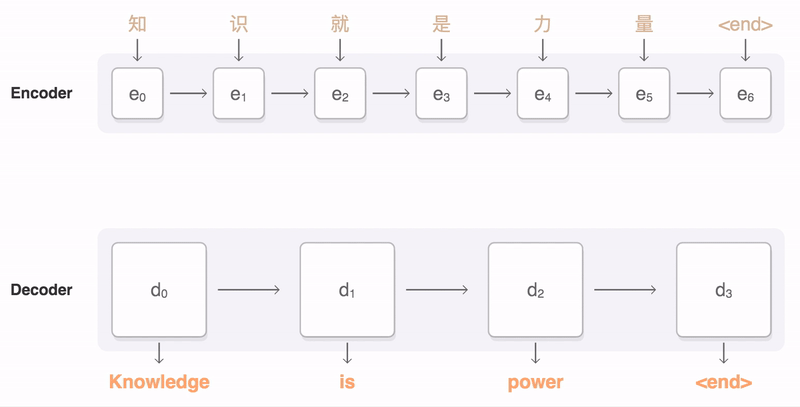
下面我通过一个翻译的例子,来说明Seq2Seq的工作原理。
工作原理
我们先从模型的训练开始,Seq2Seq的训练和Word2Vec不太一样,因为我们讲解的是中英文翻译场景,所以训练的时候,训练数据是中英文数据对。Seq2Seq的训练会比Word2Vec更加复杂一些。上节课的Word2Vec,我们使用的是gensim库提供的基础模型,直接进行训练,这节课我们完全从头写起,训练一个Seq2Seq模型。
模型训练
我们先准备训练数据,可以在网上找公开的翻译数据集,我们用的是 AIchallenger 2017,这个数据集有1000万对中英文数据,不过因为电脑配置问题,我直接从里面中文和英文的部分各取了10000条进行训练。数据集名称是train_1w.zh和train_1w.en。
1 | cn_sentences = [] |
接下来,基于训练数据集构建中文和英文的词汇表,将每个词映射到一个唯一的索引(integer)。
1 | # cn_sentences 和 en_sentences 分别包含了所有的中文和英文句子 |
我们再来看 biild_vocab的源码。
1 | def build_vocab(sentences, tokenizer, max_size, min_freq): |
思路就是把所有的句子读进去,循环分词,放入字典,放的时候要判断一下是否大于等于min_freq,用来过滤掉出现频率较低的词汇,最后构建出来的词汇表如下:
1 | vocab = { |
我们来看一下里面比较重要的几个部分。
<unk>:未知单词,表示在训练数据中没有出现过的单词。当模型在处理输入文本时遇到未知单词时,会用这个标记来表示。<pad>:填充单词,用于将不同长度的序列填充到相同的长度。在处理批次数据时,由于不同序列的长度可能不同,因此需要用这个标记把短序列填充到与最长序列相同的长度,以便进行批次处理。<sos>:句子起始标记,表示句子的开始位置。在Seq2Seq模型中,通常会在目标句子的开头添加这个标记,以指示解码器开始生成输出。<eos>:句子结束标记,表示句子的结束位置。在Seq2Seq模型中,通常会在目标句子的末尾添加该标记,以指示解码器生成结束。
创建训练数据集,将数据处理成方便训练的格式:语言序列,比如 [1,2,3,4]。
1 | dataset = TranslationDataset(cn_sentences, en_sentences, cn_vocab, en_vocab, tokenize_cn, tokenize_en) |
然后检测是否有显卡:
1 | # 检查是否有可用的GPU,如果没有,则使用CPU |
创建模型,参数的解释可以参考代码注释。
1 |
|
开始训练:
1 | num_epochs = 10 # 训练轮数 |
我拿下面的素材举例,简单解释一下训练过程。
1 | 我 喜欢 学习 机器 学习。 |
在开始训练之前,先把原文本转化成在对应词语表里的语言序列,比如在中文词汇表中,我 喜欢 学习 机器 学习 分别对应的是 1,2,3,4,5,那么转化成的语言序列就是 [1,2,3,4,5],也就是前面讲的train_loader里的格式。
编码器接收到语言序列,经过神经网络GRU单元处理后,生成一个上下文向量,这个上下文向量会作为解码器的初始状态。
解码器接收上下文向量作为输入,并根据当前上下文以及已生成的部分目标语言序列,计算目标词汇表中每个单词的概率分布。例如,在第一个时间步,解码器可能计算出目标词汇表中每个单词的概率分布,如 "I": 0.3, "like": 0.1, "studying": 0.5, "machine": 0.05, "learning": 0.05,根据解码器生成的概率分布,选择概率最高的词studying作为当前时间步的输出。
模型将解码器生成的输出词汇与目标语言句子(“I like studying machine learning.”)中当前时间步对应的词汇进行对比。这里解码器输出的 "studying" 与目标语言句子中的 "I" 进行对比,发现它们之间的差别较大。
根据解码器输出 "studying" 和目标语言句子中的真实词汇 "I" 计算损失,并通过反向传播算法计算梯度。损失值是一个衡量模型预测输出与真实目标之间差异的指标。然后,根据损失值更新模型参数,使模型能够更准确地预测下一个词汇。
重复以上步骤,直到模型达到指定的训练轮数或者满足其他停止训练的条件。在每次训练迭代中,模型都在尝试调整自己的参数,以使其预测输出更接近真实的目标语言序列,从而提高翻译质量。
所以这里就能看出,训练轮数就非常关键,不能太少,也不能太多。
模型验证
1 | def translate_sentence(sentence, src_vocab, trg_vocab, model, device, max_len=50): |
程序输出如下:
1 | Chinese: 我喜欢学习机器学习。 |
看上去只翻译成功了“我”这个字,其他都没出来,大概率是因为训练数据太少的原因。
推理过程和训练过程很像,区别在于,训练过程中模型会记住参数,推理的时候直接根据这些参数计算下一个词的概率即可。
结尾放一下完整的代码:
1 | import torch |
小结
这节课我们自己动手训练了一个Seq2Seq模型,Seq2Seq可以算是一种高级的神经网络模型了,除了做语言翻译外,甚至可以做基本的问答系统了。但是,Seq2Seq缺点也比较明显,首先Seq2Seq使用固定上下文长度,所以长距离依赖能力较弱。此外,Seq2Seq训练和推理通常需要逐步处理输入和输出序列,所以处理长序列可能会有限制。最后Seq2Seq参数量通常较少,所以面对复杂场景,模型性能可能会受限。
带着这些问题,下一节课我将会向你介绍终极大boss:Transformer,我们学习了这么多基础概念,就是为学习Transformer做铺垫,从ML->NLP->Word2Vec->Seq2Seq->Transformer一步一步递进。
注:en_core_web_sm、train_1w.zh、train_1w.en 链接: https://pan.baidu.com/s/1_GG3bIAjqpPGLGugHEI5Dg?pwd=fm8j 提取码: fm8j
思考题
我刚刚讲过,推理的时候模型会使用训练过程中记住的参数来进行概率预测,你可以思考一下,模型的参数到底是什么?欢迎在评论区留言,我们一起讨论学习,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给需要的朋友,邀TA一起学习,我们下节课再见!