你好,我是黄佳。
大语言模型不仅可以生成文本摘要,还可以读取数据、做出直观的可视化,并生成有意义的见解。这种见解,是任何传统计算机程序所无法给出的,在大语言模型出现之前,也只有人类能够做出。
今天,我们要探索如何利用OpenAI的大语言模型完成一个有趣的商业案例:分析畅销歌曲数据,生成行业报告并创建PPT。我们将经历从原始数据到精美PPT的全过程,体验大语言模型的强大能力。
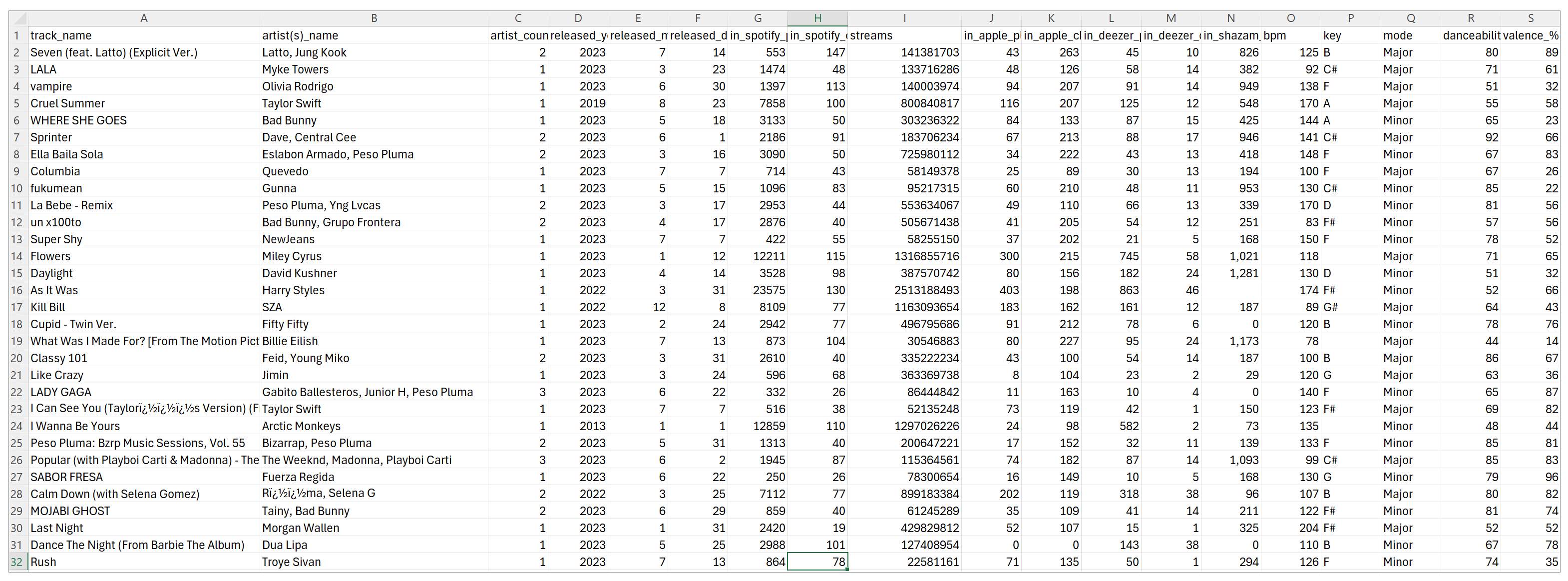
项目目标:流行音乐趋势分析 先来看看这份从Spotify App中搜集来的,播放量最多的流行音乐数据表。
这些属性从多个角度刻画了流行音乐的特点,包括其发行时间、在各大平台的表现、音乐特性等。
假设我们是一家名为“鸟语乐境”的流行音乐分享平台,我们需要通过分析这些数据来洞察当下流行音乐的趋势,了解大众的音乐品味。同时,这些信息对于音乐制作人、歌手和音乐平台也有重要的参考价值,有助于他们创作和推荐符合市场需求的音乐作品。
我们将让AI来帮我们梳理数据,生成图片,以及基于数据生成观点和简介,最后自动创建生成较为靠谱的PPT。
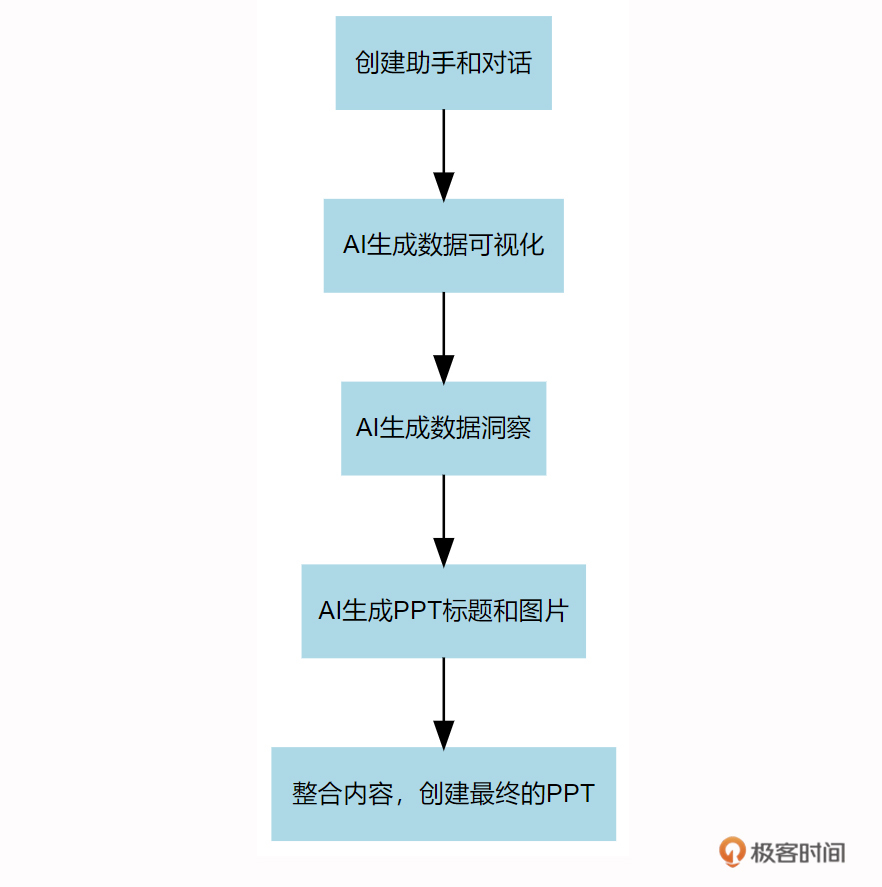
项目整体流程 这个数据分享项目的整体流程如下图所示,在这个过程中,最主要的环节,都将由AI完成。
这个项目的核心环节是OpenAI的Assistant替我们生成数据可视化,以及在数据中寻找和挖掘趋势和洞见。整个过程,我们只需要通过提示词来对Assistant进行一些小小的引导和启发即可。
接下来,让我们期待一下,Assistant是如何对这些数据进行更深入的探索!
步骤 1:创建助手和对话 首先,还是导入必要的库并创建OpenAI客户端。
1 2 3 4 5 # 导入OpenAI库,并创建OpenAI客户端 from dotenv import load_dotenv load_dotenv() from openai import OpenAI client = OpenAI()
然后,导入这个包含2023年Spotify最畅销歌曲数据的CSV文件。
1 2 3 4 5 # 导入数据文件 import pandas as pd file_path = 'Spotify_Songs.csv' sales_data = pd.read_csv(file_path, nrows=20) sales_data.head()
数据集包含了曲目名称、艺术家、发布年份、流媒体播放量等有价值的信息。
为了让OpenAI的大语言模型能够分析这些数据,我们需要将CSV文件上传到OpenAI,并创建一个数据科学助手。这个助手将负责编写代码、创建可视化并提取洞见。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 创建文件 file = client.files.create( file=open(file_path, "rb"), purpose='assistants', ) # 创建一个包含这个文件的助手 assistant = client.beta.assistants.create( instructions="作为一名数据科学助理,当给定数据和一个查询时,你能编写适当的代码并创建适当的可视化。", model="gpt-4-0125-preview", tools=[ {"type": "code_interpreter"} ], tool_resources={ "code_interpreter": { "file_ids": [file.id] # Here we add the file id } } ) print(assistant)
输出如下:
1 Assistant(id='asst_frwRB2Ugjj2XVUGnRy5f3no7', created_at=1717210909, description=None, instructions='作为一名数据科学助理,当给定数据和一个查询时,你能编写适当的代码并创建适当的可视化。', metadata={}, model='gpt-4-0125-preview', name=None, object='assistant', tools=[CodeInterpreterTool(type='code_interpreter')], tool_resources=ToolResou
步骤 2:AI 生成数据可视化 助手创建完成后,就可以与它进行对话了。我们将创建对话线程,同时在对话线程中添加要求Assistant进行数据分析的消息,并运行线程。
先创建对话线程。这里要请求助手,根据数据创建一个能展示畅销音乐特点和趋势的可视化图表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 创建对话线程 thread = client.beta.threads.create( messages=[ { "role": "user", "content": "根据数据集的内容,选择最有代表性的字段,根据畅销音乐的特点和趋势做一张可视化表格,每个音乐家用不同的颜色表示。", "attachments": [ { "file_id": file.id, "tools": [ { "type": "code_interpreter" } ] } ] } ] ) print(thread)
输出如下:
1 Thread(id='thread_iIvaQeLDBTSUa6Zacil8KQ80', created_at=1717223262, metadata={}, object='thread', tool_resources=ToolResources(code_interpreter=ToolResourcesCodeInterpreter(file_ids=['file-TgNxU9yP74IectmQt2ScOYhY']), file_search=None))
下面创建Run。
1 2 3 4 5 6 # 创建Run来运行和助手的对话 run = client.beta.threads.runs.create( thread_id=thread.id, assistant_id=assistant.id, ) print(run)
输出如下:
1 Run(id='run_EDjLmAUQ6PHRxgKHCUNkBk1h', assistant_id='asst_frwRB2Ugjj2XVUGnRy5f3no7', cancelled_at=None, completed_at=None, created_at=1717223264, expires_at=1717223864, failed_at=None, incomplete_details=None, instructions='作为一名数据科学助理,当给定数据和一个查询时,你能编写适当的代码并创建适当的可视化。', last_error=None, max_completion_tokens=None, max_prompt_tokens=None, metadata={}, model='gpt-4-0125-preview', object='thread.run', required_action=None, response_format='auto', started_at=None, status='queued', thread_id='thread_iIvaQeLDBTSUa6Zacil8KQ80', tool_choice='auto', tools=[CodeInterpreterTool(type='code_interpreter')], truncation_strategy=TruncationStrategy(type='auto', last_messages=None), usage=None, temperature=1.0, top_p=1.0, tool_resources={})
下面,运行对话,等待Assistant根据数据集内容来创建图表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 检查并等待可视化完成 import time while True: messages = client.beta.threads.messages.list(thread_id=thread.id) try: # 检查是否创建了图像 messages.data[0].content[0].image_file # 等待运行完成 time.sleep(5) print('图表已创建!') if messages.data and messages.data[0].content: print('当前Message:', messages.data[0].content[0]) break except: time.sleep(10) print('您的Assistant正在努力做图表呢...') if messages.data and messages.data[0].content: print('当前Message:', messages.data[0].content[0])
输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 您的Assistant正在努力做图表呢... 您的Assistant正在努力做图表呢... 您的Assistant正在努力做图表呢... 当前Message: TextContentBlock(text=Text(annotations=[], value='根据数据集的内容,我们有以下字段可以用来表示畅销音乐的特点和趀势:\n\n- `track_name`: 音轨名称\n- `artist(s)_name`: 艺术家名称\n- `artist_count`: 艺术家数量\n- `released_year`: 发布年份\n- `streams`: 流量\n- `bpm` (Beats Per Minute): 节拍速度\n- `key`: 调性\n- `mode`: 调式\n- `danceability_%`: 可跳舞性百分比\n- `valence_%`: 歌曲情感的积极性百分比\n- `energy_%`: 能量百分比\n- `acousticness_%`: 声学性百分比\n- `instrumentalness_%`: 乐器音乐性百分比\n- `liveness_%`: 现场感百分比\n- `speechiness_%`: 语音性百分比\n\n考虑到要根据畅销音乐的特点和趋势进行可视化,同时也要每个音乐家以不同的颜色表示,我们可以选择几个关键特征如`streams` (流量)、`danceability_%` (可跳舞性)和`energy_%`(能量)来进行可视化,并以`released_year`为X轴,以展现趋势。\n\n接下来,我将会创建一张图表,展示不同艺术家的歌曲流量、可跳舞性和能量随时间的变化趋势。由于艺术家数量可能较多,为了可视化的清晰度,我们可能需要限制显示的艺术家数量。现在让我们先检查一下有多少位不同的艺术家,并确定一个合理的显示方法。'), type='text') 您的Assistant正在努力做图表呢... 当前Message: TextContentBlock(text=Text(annotations=[], value='数据集包含645位不同的艺术家,这意呩着如果我们尝试将所有艺术家的数据都展示在一张图表上,图表可能会非常混乱且难以阅读。因此,为了创建一个清晰且易于解读的可视化,我们将选择几位流量最高的艺术家进行展示。\n\n具体步骤如下:\n1. 确定流量最高的几位艺术家。\n2. 对这些艺术家的数据进行可视化,使用不同的颜色区分不同的艺术家,并展示随时间变化的趋势。\n\n现在,让我们先确定前10位流量最高的艺术家。'), type='text') 您的Assistant正在努力做图表呢... 您的Assistant正在努力做图表呢... 您的Assistant正在努力做图表呢... 当前Message: TextContentBlock(text=Text(annotations=[], value='选择了流量最高的10首歌曲进行分析和可视化时,我们注意到一首歌曲"Love Grows (Where My Rosemary Goes)"的流量数据似乎受到了异常值的影响,并且它的发布年份为1970,这可能是一个占位或错误的值。因此,在接下来的可视化中,我们将排除这首歌曲。\n\n我们将基于以下字段进行可视化:\n- `track_name`:歌曲名称\n- `artist(s)_name`:艺术家名称\n- `released_year`:发布年份\n- `streams`:流量\n- `danceability_%`:可跳舞性百分比\n- `energy_%`:能量百分比\n\n每首歌曲将使用一个不同的颜色表示。由于原始数据的一些问题,我们需要进行适当的调整和清理。现在,我将进行这些步骤,并创建一张展示这些畅销歌曲随发布年份变化的可跳舞性和能量的趋势图。'), type='text') 您的Assistant正在努力做图表呢... 当前Message: TextContentBlock(text=Text(annotations=[], value='似乎在尝试清理数据和准备可视化时出现了一个语法错误。我会立即更正这个问题并重新尝试绘制图表。'), type='text') 您的Assistant正在努力做图表呢... 您的Assistant正在努力做图表呢... 当前Message: TextContentBlock(text=Text(annotations=[], value='我在尝试运行可视化代码时未能成功导入必要的可视化库`matplotlib`和`seaborn`。我会立即纠正这个问题并重试创建图表。让我们重新导入这些库,并绘制关于畅销歌曲的跳舞性随发布年份的变化图表。'), type='text') 您的Assistant正在努力做图表呢... 当前Message: TextContentBlock(text=Text(annotations=[], value='我在尝试运行可视化代码时未能成功导入必要的可视化库`matplotlib`和`seaborn`。我会立即纠正这个问题并重试创建图表。让我们重新导入这些库,并绘制关于畅销歌曲的跳舞性随发布年份的变化图表。'), type='text') 图表已创建! 当前Message: ImageFileContentBlock(image_file=ImageFile(file_id='file-03gX6k5HtwwlBQg6M75cRLe2'), type='image_file')
上面的输出内容非常值得细品。
可以看出,Assistant会自己发现错误,进行一系列的尝试,纠正问题所在,然后再不断地尝试,包括分析数据、选择合适的艺术家、清理数据等。它逐步深入地进行分析和思考,最终,它创建了一张展示了几首最畅销歌曲随时间变化的可跳舞性和能量的趋势图!
我们下载这张图片并进行展示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 转换输出文件为PNG格式 def convert_file_to_png(file_id, write_path): data = client.files.content(file_id) data_bytes = data.read() with open(write_path, "wb") as file: file.write(data_bytes) plot_file_id = messages.data[0].content[0].image_file.file_id image_path = "音乐趋势图.png" convert_file_to_png(plot_file_id,image_path) # 上传图表 plot_file = client.files.create( file=open(image_path, "rb"), purpose='assistants' )
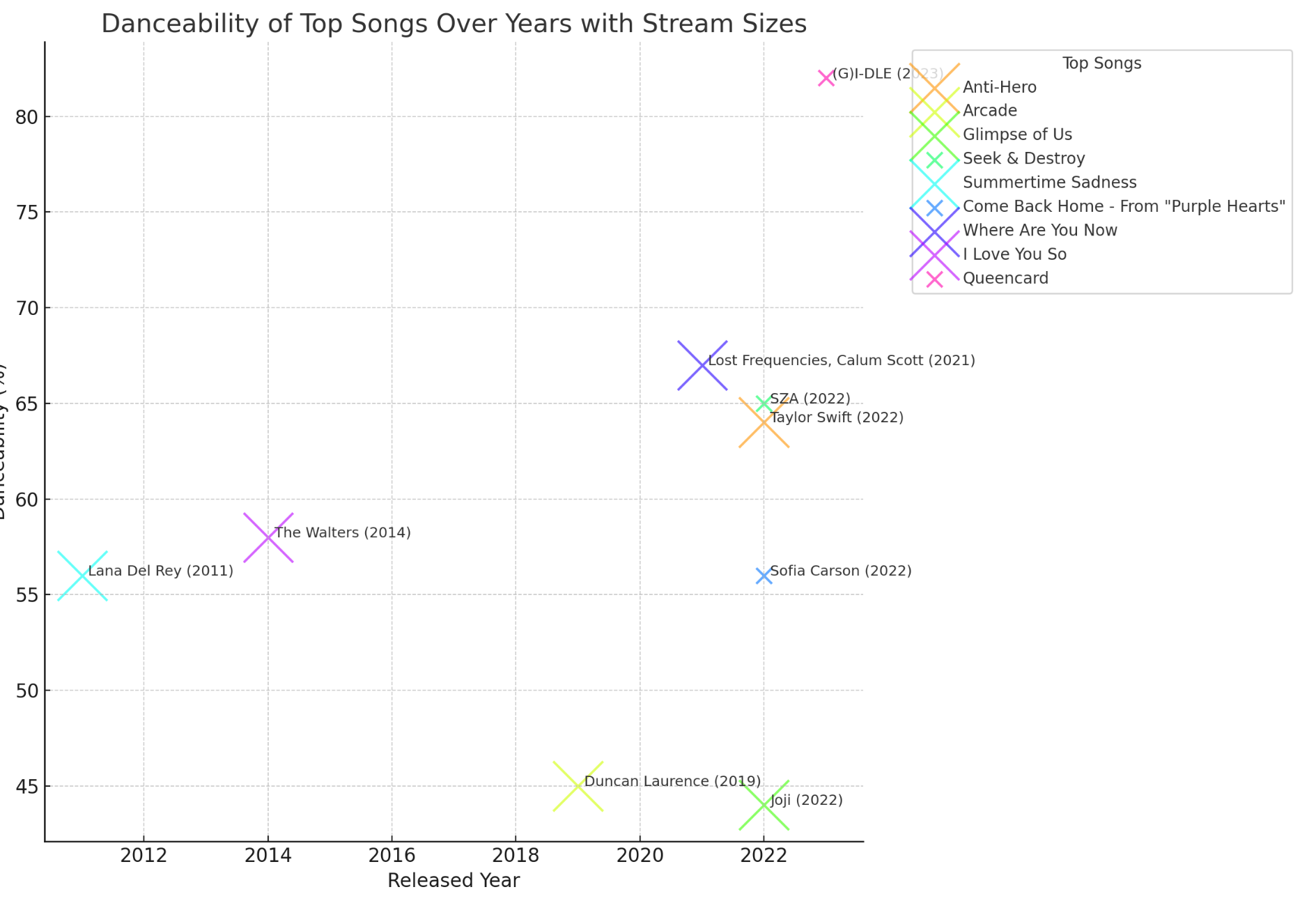
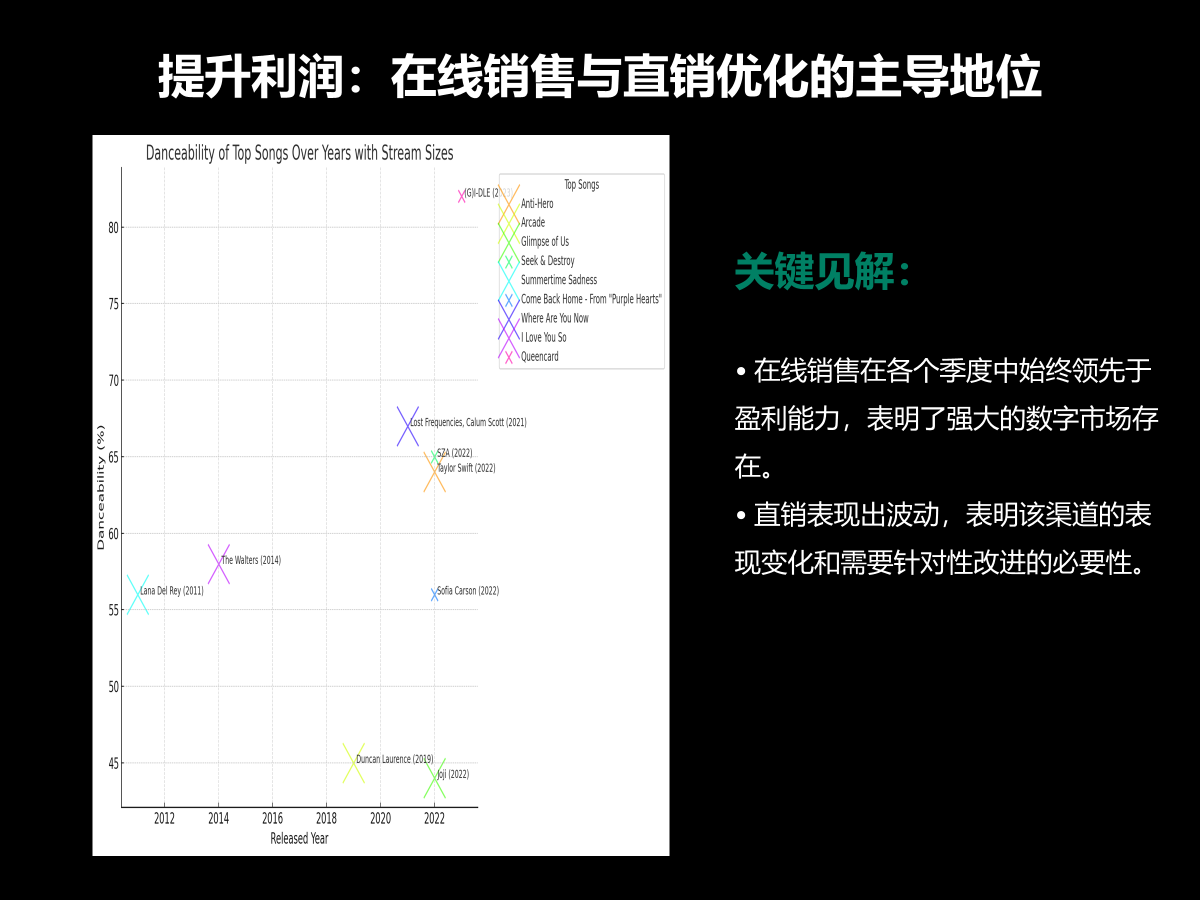
这张图展示了不同年份的热门歌曲的可跳舞性与流媒体播放量的关系。
横轴(X轴) :表示歌曲的发行年份,从2012年到2023年。纵轴(Y轴) :表示歌曲的可跳舞性百分比(Danceability%),范围从45%到85%。标记大小 :表示歌曲在流媒体平台上的播放量(Stream Sizes)。标记越大,表示该歌曲的播放量越大。标记颜色和形状 :不同颜色和形状表示不同的歌曲,每首歌都有唯一的标记。图中主要观察点如下:
高可跳舞性歌曲 :如图中右上角的 (G)I-DLE 的歌曲,显示了较高的可跳舞性(接近80%)。热门年份 :2022年和2023年发布了多首高可跳舞性且播放量高的歌曲,如Taylor Swift和SZA的歌曲。长期趋势 :图中可以看到从2012年到2023年,热门歌曲的可跳舞性总体上有上升的趋势,表明近年来流行音乐的风格越来越适合跳舞。显著标记 :一些标记特别大,代表这些歌曲在流媒体平台上有非常高的播放量,如Taylor Swift和Duncan Laurence的歌曲。总结来看,这张图是展示了热门歌曲的可跳舞性随时间的变化,以及这些歌曲在流媒体平台上的受欢迎程度。
下面,看看助手整个的思维和行动过程。
1 2 3 # 看看助手整个的思维和行动过程 messages = client.beta.threads.messages.list(thread_id=thread.id) [message.content[0] for message in messages.data]
输出如下:
1 2 3 4 5 6 7 8 9 [ImageFileContentBlock(image_file=ImageFile(file_id='file-03gX6k5HtwwlBQg6M75cRLe2'), type='image_file'), TextContentBlock(text=Text(annotations=[], value='我在尝试运行可视化代码时未能成功导入必要的可视化库`matplotlib`和`seaborn`。我会立即纠正这个问题并重试创建图表。让我们重新导入这些库,并绘制关于畅销歌曲的跳舞性随发布年份的变化图表。'), type='text'), TextContentBlock(text=Text(annotations=[], value='似乎在尝试清理数据和准备可视化时出现了一个语法错误。我会立即更正这个问题并重新尝试绘制图表。'), type='text'), TextContentBlock(text=Text(annotations=[], value='选择了流量最高的10首歌曲进行分析和可视化时,我们注意到一首歌曲"Love Grows (Where My Rosemary Goes)"的流量数据似乎受到了异常值的影响,并且它的发布年份为1970,这可能是一个占位或错误的值。因此,在接下来的可视化中,我们将排除这首歌曲。\n\n我们将基于以下字段进行可视化:\n- `track_name`:歌曲名称\n- `artist(s)_name`:艺术家名称\n- `released_year`:发布年份\n- `streams`:流量\n- `danceability_%`:可跳舞性百分比\n- `energy_%`:能量百分比\n\n每首歌曲将使用一个不同的颜色表示。由于原始数据的一些问题,我们需要进行适当的调整和清理。现在,我将进行这些步骤,并创建一张展示这些畅销歌曲随发布年份变化的可跳舞性和能量的趋势图。'), type='text'), TextContentBlock(text=Text(annotations=[], value='在选择前10位流量最高的艺术家时,出现了一些意外的结果,这可能是由于原始数据或处理过程中的错误。似乎有一些艺术家的名称被错误地整合成了其歌曲的特征描述或串连了多个数值,从而导致了异常的艺术家名称。\n\n为了绕过这个问题,我们可以改变策略:选择数据中流量(streams)最高的几首歌曲来可视化,而不是基于艺术家。这样,我们便可以避开艺术家名称可能引起的错误,并专注于展现畅销音乐的特点和趋势。\n\n我将首先确定流量最高的10首歌曲,然后对这些歌曲的流量、可跳舞性(`danceability_%`)和能量(`energy_%`)随发布年份的变化趋势进行可视化,每首歌曲将使用不同的颜色表示。让我们开始这个新的策略。'), type='text'), TextContentBlock(text=Text(annotations=[], value='数据集包含645位不同的艺术家,这意呩着如果我们尝试将所有艺术家的数据都展示在一张图表上,图表可能会非常混乱且难以阅读。因此,为了创建一个清晰且易于解读的可视化,我们将选择几位流量最高的艺术家进行展示。\n\n具体步骤如下:\n1. 确定流量最高的几位艺术家。\n2. 对这些艺术家的数据进行可视化,使用不同的颜色区分不同的艺术家,并展示随时间变化的趋势。\n\n现在,让我们先确定前10位流量最高的艺术家。'), type='text'), TextContentBlock(text=Text(annotations=[], value='根据数据集的内容,我们有以下字段可以用来表示畅销音乐的特点和趀势:\n\n- `track_name`: 音轨名称\n- `artist(s)_name`: 艺术家名称\n- `artist_count`: 艺术家数量\n- `released_year`: 发布年份\n- `streams`: 流量\n- `bpm` (Beats Per Minute): 节拍速度\n- `key`: 调性\n- `mode`: 调式\n- `danceability_%`: 可跳舞性百分比\n- `valence_%`: 歌曲情感的积极性百分比\n- `energy_%`: 能量百分比\n- `acousticness_%`: 声学性百分比\n- `instrumentalness_%`: 乐器音乐性百分比\n- `liveness_%`: 现场感百分比\n- `speechiness_%`: 语音性百分比\n\n考虑到要根据畅销音乐的特点和趋势进行可视化,同时也要每个音乐家以不同的颜色表示,我们可以选择几个关键特征如`streams` (流量)、`danceability_%` (可跳舞性)和`energy_%`(能量)来进行可视化,并以`released_year`为X轴,以展现趋势。\n\n接下来,我将会创建一张图表,展示不同艺术家的歌曲流量、可跳舞性和能量随时间的变化趋势。由于艺术家数量可能较多,为了可视化的清晰度,我们可能需要限制显示的艺术家数量。现在让我们先检查一下有多少位不同的艺术家,并确定一个合理的显示方法。'), type='text'), TextContentBlock(text=Text(annotations=[], value='首先,我将打开和检查上传的文件,以了解其内容和结构。这将帮助我明确哪些字段可以最好地代表畅销音乐的特点和趋势。接着,我将基于这些信息选择一个合适的可视化方法。让我们开始吧。'), type='text'), TextContentBlock(text=Text(annotations=[], value='根据数据集的内容,选择最有代表性的字段,根据畅销音乐的特点和趋势做一张可视化表格,每个音乐家用不同的颜色表示。'), type='text')]
其实,AI的思考过程更值得我们玩味,假设你把这份工作交给一个刚毕业的新手数据分析师,他其实并不一定能把自己的思考链条说得像AI这么清楚。
步骤 3:AI 生成数据洞察 下面,我们先定义一个提交用户的消息的函数。然后,使用submit_message函数,来发送请求,让助手生成数据洞察。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # 定义提交用户的消息的函数 def submit_message_wait_completion(assistant_id, thread, user_message, file_ids=None): # 检查并等待活跃的Run完成 for run in client.beta.threads.runs.list(thread_id=thread.id).data: if run.status == 'in_progress': print(f"等待Run {run.id} 完成...") while True: run_status = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id).status if run_status in ['succeeded', 'failed']: break time.sleep(5) # 等待5秒后再次检查状态 # 提交消息 params = { 'thread_id': thread.id, 'role': 'user', 'content': user_message, } # 设置attachments if file_ids: attachments = [{"file_id": file_id, "tools": [ {"type": "code_interpreter"}]} for file_id in file_ids] params['attachments'] = attachments client.beta.threads.messages.create(**params) # 创建Run run = client.beta.threads.runs.create(thread_id=thread.id, assistant_id=assistant_id) return run # 使用submit_message函数, 来发送请求,让助手生成洞察 submit_message_wait_completion(assistant.id, thread, "请根据你刚才创建的图表,给我两个约20字的句子,描述最重要的洞察。这将用于幻灯片展示,揭示出数据背后的'秘密'。")
输出如下:
1 Run(id='run_WdgdIFOyQXTM9ATigdrKgham', assistant_id='asst_frwRB2Ugjj2XVUGnRy5f3no7', cancelled_at=None, completed_at=None, created_at=1717223943, expires_at=1717224543, failed_at=None, incomplete_details=None, instructions='作为一名数据科学助理,当给定数据和一个查询时,你能编写适当的代码并创建适当的可视化。', last_error=None, max_completion_tokens=None, max_prompt_tokens=None, metadata={}, model='gpt-4-0125-preview', object='thread.run', required_action=None, response_format='auto', started_at=None, status='queued', thread_id='thread_iIvaQeLDBTSUa6Zacil8KQ80', tool_choice='auto', tools=[CodeInterpreterTool(type='code_interpreter')], truncation_strategy=TruncationStrategy(type='auto', last_messages=None), usage=None, temperature=1.0, top_p=1.0, tool_resources={})
下面,读取AI生成的数据洞察。
1 2 3 4 5 6 7 8 9 # 获取对话线程的响应 def get_response(thread): return client.beta.threads.messages.list(thread_id=thread.id) # 等待响应并打印洞察 time.sleep(10) # 假设助理需要一些时间来生成洞察 response = get_response(thread) bullet_points = response.data[0].content[0].text.value print(bullet_points)
输出的数据洞察如下:
1 2 1. "2019至2023年间,畅销歌曲的跳舞性明显上升,展现了流行音乐向更加活跃风格的转变。" 2. "Taylor Swift和Duncan Laurence的歌曲以超高流量领跑,彰显了其在全球音乐市场的巨大影响力。"
这是非常漂亮的、有理有据的观察,也是商业分析的初步结果。其实我们可以顺着这个思路进一步让AI进行更深层的思考。当然,我们这个展示性质的Demo就到此为止,下面我们要根据这个洞察继续创建PPT了。
步骤 4:AI 生成 PPT 标题和图片 下面,我们根据上面的见解,也就是基于对数据的洞察,让AI顺着思考,为PPT生成一个标题。
1 2 3 # 根据见解生成标题 submit_message_wait_completion(assistant.id, thread, "根据你创建的情节和要 点,为幻灯片想一个非常简短的标题。它应该只反映你得出的主要见解。")
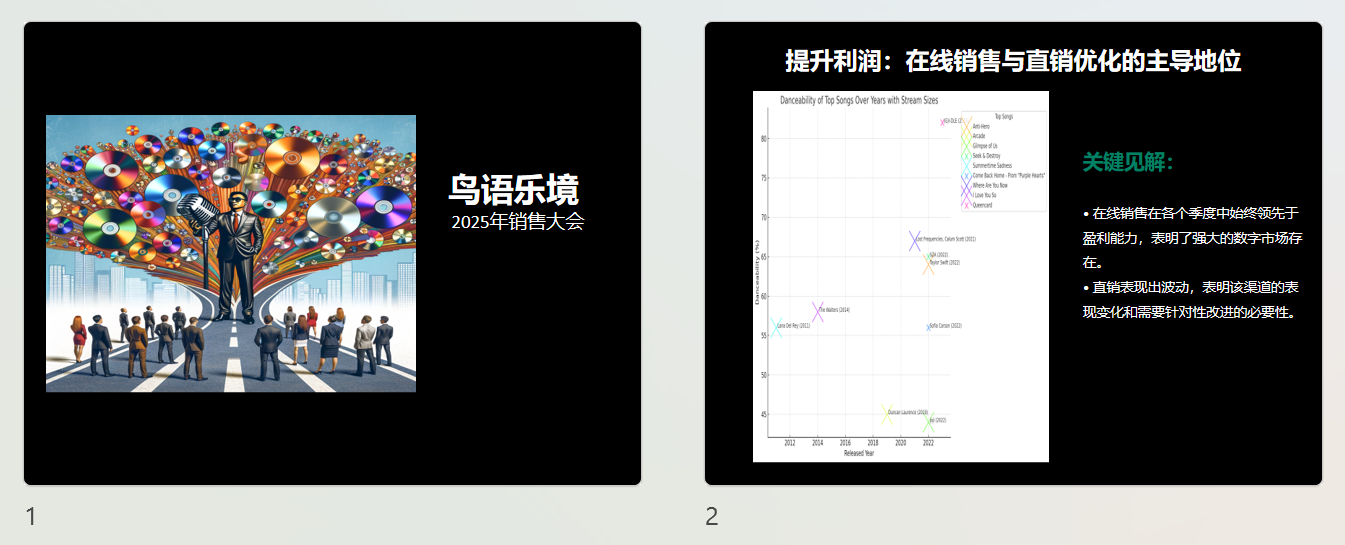
Assistant马上给出一个非常棒的标题,“流行音乐趋势:活跃风格与巨星影响力” 。
下面,我们让AI为这个PPT标题配图。
我们使用DALL-E的API来生成图片。这里提供公司简介作为提示,并指定生成高清大图。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 提供我们公司的说明 company_summary = "我们是CD批发商,但是我们董事长也是个流行歌手!" # 使用DALL-E 3生成图片 response = client.images.generate( model='dall-e-3', prompt=f"根据这个公司概述 {company_summary}, \ 创建一张展示成长和前进道路的启发性照片。这将用于季度销售规划会议", size="1024x1024", quality="hd", n=1 ) image_url = response.data[0].url # 获取DALL-E 3生成的图片 import requests dalle_img_path = '音乐趋势图.png' img = requests.get(image_url) # 将图片保存到本地 with open(dalle_img_path,'wb') as file: file.write(img.content) # 上传图片提供给助手做为PPT素材 dalle_file = client.files.create( file=open(dalle_img_path, "rb"), purpose='assistants' )
程序成功执行,并且创建了一张合适的PPT标题配图。DALL-E会返回生成图片的URL,可以下载这张图片并上传给之前创建的助手,作为之后生成PPT的素材。
步骤 5:创建最终的 PPT 终于到了生成PPT的最后阶段!我们已经准备好了所有素材:数据图表、洞察要点和创意图片。现在,我们使用预先定义的PPT模板(这个模板的设置参考自OpenAI的示例,你也可以自行调整格式),将这些内容填充进去。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 title_template = """ from pptx import Presentation from pptx.util import Inches, Pt from pptx.enum.text import PP_PARAGRAPH_ALIGNMENT from pptx.dml.color import RGBColor # 创建新的演示文稿对象 prs = Presentation() # 添加一个空白的幻灯片布局 blank_slide_layout = prs.slide_layouts[6] slide = prs.slides.add_slide(blank_slide_layout) # 将幻灯片的背景颜色设置为黑色 background = slide.background fill = background.fill fill.solid() fill.fore_color.rgb = RGBColor(0, 0, 0) # 在幻灯片左侧添加图片,上下留有边距 left = Inches(0) top = Inches(0) height = prs.slide_height width = prs.slide_width * 3/5 pic = slide.shapes.add_picture(image_path, left, top, width=width, height=height) # 在较高位置添加标题文本框 left = prs.slide_width * 3/5 top = Inches(2) width = prs.slide_width * 2/5 height = Inches(1) title_box = slide.shapes.add_textbox(left, top, width, height) title_frame = title_box.text_frame title_p = title_frame.add_paragraph() title_p.text = title_text title_p.font.bold = True title_p.font.size = Pt(38) title_p.font.color.rgb = RGBColor(255, 255, 255) title_p.alignment = PP_PARAGRAPH_ALIGNMENT.CENTER # 添加副标题文本框 left = prs.slide_width * 3/5 top = Inches(3) width = prs.slide_width * 2/5 height = Inches(1) subtitle_box = slide.shapes.add_textbox(left, top, width, height) subtitle_frame = subtitle_box.text_frame subtitle_p = subtitle_frame.add_paragraph() subtitle_p.text = subtitle_text subtitle_p.font.size = Pt(22) subtitle_p.font.color.rgb = RGBColor(255, 255, 255) subtitle_p.alignment = PP_PARAGRAPH_ALIGNMENT.CENTER """ data_vis_template = """ from pptx import Presentation from pptx.util import Inches, Pt from pptx.enum.text import PP_PARAGRAPH_ALIGNMENT from pptx.dml.color import RGBColor # 创建新的演示文稿对象 prs = Presentation() # 添加一个空白的幻灯片布局 blank_slide_layout = prs.slide_layouts[6] slide = prs.slides.add_slide(blank_slide_layout) # 将幻灯片的背景颜色设置为黑色 background = slide.background fill = background.fill fill.solid() fill.fore_color.rgb = RGBColor(0, 0, 0) # 定义占位符 image_path = data_vis_img title_text = "提升利润:在线销售与直销优化的主导地位" bullet_points = "• 在线销售在各个季度中始终领先于盈利能力,表明了强大的数字市场存在。\n• 直销表现出波动,表明该渠道的表现变化和需要针对性改进的必要性。" # 在幻灯片左侧添加图片占位符 left = Inches(0.2) top = Inches(1.8) height = prs.slide_height - Inches(3) width = prs.slide_width * 3/5 pic = slide.shapes.add_picture(image_path, left, top, width=width, height=height) # 添加覆盖整个宽度的标题文本 left = Inches(0) top = Inches(0) width = prs.slide_width height = Inches(1) title_box = slide.shapes.add_textbox(left, top, width, height) title_frame = title_box.text_frame title_frame.margin_top = Inches(0.1) title_p = title_frame.add_paragraph() title_p.text = title_text title_p.font.bold = True title_p.font.size = Pt(28) title_p.font.color.rgb = RGBColor(255, 255, 255) title_p.alignment = PP_PARAGRAPH_ALIGNMENT.CENTER # 添加硬编码的“关键见解”文本和项目符号列表 left = prs.slide_width * 2/3 top = Inches(1.5) width = prs.slide_width * 1/3 height = Inches(4.5) insights_box = slide.shapes.add_textbox(left, top, width, height) insights_frame = insights_box.text_frame insights_p = insights_frame.add_paragraph() insights_p.text = "关键见解:" insights_p.font.bold = True insights_p.font.size = Pt(24) insights_p.font.color.rgb = RGBColor(0, 128, 100) insights_p.alignment = PP_PARAGRAPH_ALIGNMENT.LEFT insights_frame.add_paragraph() bullet_p = insights_frame.add_paragraph() bullet_p.text = bullet_points bullet_p.font.size = Pt(12) bullet_p.font.color.rgb = RGBColor(255, 255, 255) bullet_p.line_spacing = 1.5 """ title_text = "鸟语乐境" subtitle_text = "2025年销售大会" submit_message_wait_completion(assistant.id,thread,f"使用包含的代码模板创建符合模板格式的PPTX幻灯片,但使用本消息中包含的图片、公司名称/标题和文件名/副标题:\ {title_template}。重要提示:在此第一张幻灯片中使用本消息中包含的图片文件作为image_path图像,并使用公司名称 {title_text} 作为title_text变量,\ 使用副标题文本 {subtitle_text} 作为subtitle_text变量。\ 接着,使用以下代码模板创建第二张幻灯片:{data_vis_template},创建符合模板格式的PPTX幻灯片,但使用公司名称/标题和文件名/副标题:\ {data_vis_template}。重要提示:使用您之前在本线程中创建的第二个附图(折线图)作为data_vis_img图像,并使用您之前创建的数据可视化标题作为title_text变量,\ 使用您之前创建的见解项目符号列表作为bullet_points变量。将这两张幻灯片输出为.pptx文件。确保输出为两张幻灯片,每张幻灯片都符合本消息中给出的相应模板。", file_ids=[dalle_file.id, plot_file.id] ) # 等待助手完成PPT创建任务 while True: try: response = get_response(thread) pptx_id = response.data[0].content[0].text.annotations[0].file_path.file_id print("成功检索到 pptx_id:", pptx_id) break except Exception as e: print("您的Assistant正在努力制作幻灯片...") time.sleep(10) import io pptx_id = response.data[0].content[0].text.annotations[0].file_path.file_id ppt_file= client.files.content(pptx_id) file_obj = io.BytesIO(ppt_file.read()) with open("宣传大会.pptx", "wb") as f: f.write(file_obj.getbuffer())
输出如下:
1 2 3 4 5 6 您的Assistant正在努力制作幻灯片... 您的Assistant正在努力制作幻灯片... 您的Assistant正在努力制作幻灯片... 您的Assistant正在努力制作幻灯片... 您的Assistant正在努力制作幻灯片... 成功检索到 pptx_id: file-c39pmCGSIhl2llr1835lTMgP
助手会按照我们的要求,生成一个两页的PPT。第一页使用了DALL-E生成的创意图片,第二页则是数据图表和洞察要点。最后,我们可以将生成的PPTX文件下载到本地。
下面,就是展示时刻!当当当当,两张漂亮的PPT映入眼帘。
AI,你真棒!
总结时刻 在今天的实操中,我们体验了如何利用OpenAI的大语言模型完成从数据分析到PPT生成的全流程。在这个过程中,大语言模型不仅展示了其在文本生成和语言理解上的卓越能力,还展现了其在数据分析和商业智能领域的巨大潜力。通过本次探索,我们深入体验了大语言模型在处理数据、生成可视化、提供有意义见解,以及为文字配图等方面的强大功能。
过程中有几个环节令我印象深刻,一是在数据可视化环节,AI通过不断尝试和纠错,最终呈现出一张直观的可视化图表。此外,AI不仅仅停留在数据展示层面,更能够深入挖掘数据背后的洞察。例如,通过分析图表,AI生成了关于流行音乐趋势的两个重要见解。
可以看到,借助大语言模型强大的数据分析、自然语言理解和多模态生成能力,我们可以大大简化和自动化商业报告的生成过程。想象一下,如果你的公司定期有类似的数据分析和报告任务,使用这套流程可以节省多少时间和人力!
在真实的商业场景中,数据可能更加复杂,分析的角度也更加多元。幸运的是,大语言模型的能力还远不止于此。你的场景越复杂,在你精心设计的 Prompts 和模板的引导下,AI能够发挥的威力可能也就越大。我们有理由相信,高级数据分析师和商业分析人员可以引导AI生成更加深入、专业、符合业务需求的分析报告,而大语言模型也必将在商业智能领域发挥出越来越重要的作用。
思考题 其实,畅销歌曲只是一个示例数据集,这节课所介绍的流程的价值在于,它可以切换到任意领域,任何行业的数据集(在我的新书《动手做AI Agent》,我就用同样的流程完成了一个咖哥图书销量的数据分析),你能想到还有哪些数据适合用类似的方法来分析和生成报告吗? 在课程的案例中,我们使用了一些预定义的PPT模板,你认为是否可以让AI自己生成各种风格的PPT模板呢? 如果要将课程案例扩展成一个自动化的商业分析报告生成平台,你认为还需要哪些额外的功能? 欢迎你也尝试一下!我相信通过大语言模型所带来的智能化浪潮,我们每个人都有机会成为更加高效和有创意的商业数据分析专家。