你好,我是俊达。
数据复制技术是构建MySQL高可用环境的基础,但无论是异步复制,还是半同步复制,在理论上都无法保证极端情况下数据完全一致。MySQL 8.0中的组复制技术(MGR,MySQL Group Replication),使用了基于Paxos 协议的分布式一致性算法,能保证事务在集群中的一致性复制。
这一讲,我们来聊一聊怎么搭建一个MySQL组复制集群,以及组复制中一些常见问题的处理方法。
MySQL数据复制回顾
我们先来回顾下几种复制架构,这里使用了官方文档中的几个架构图。
- 异步复制
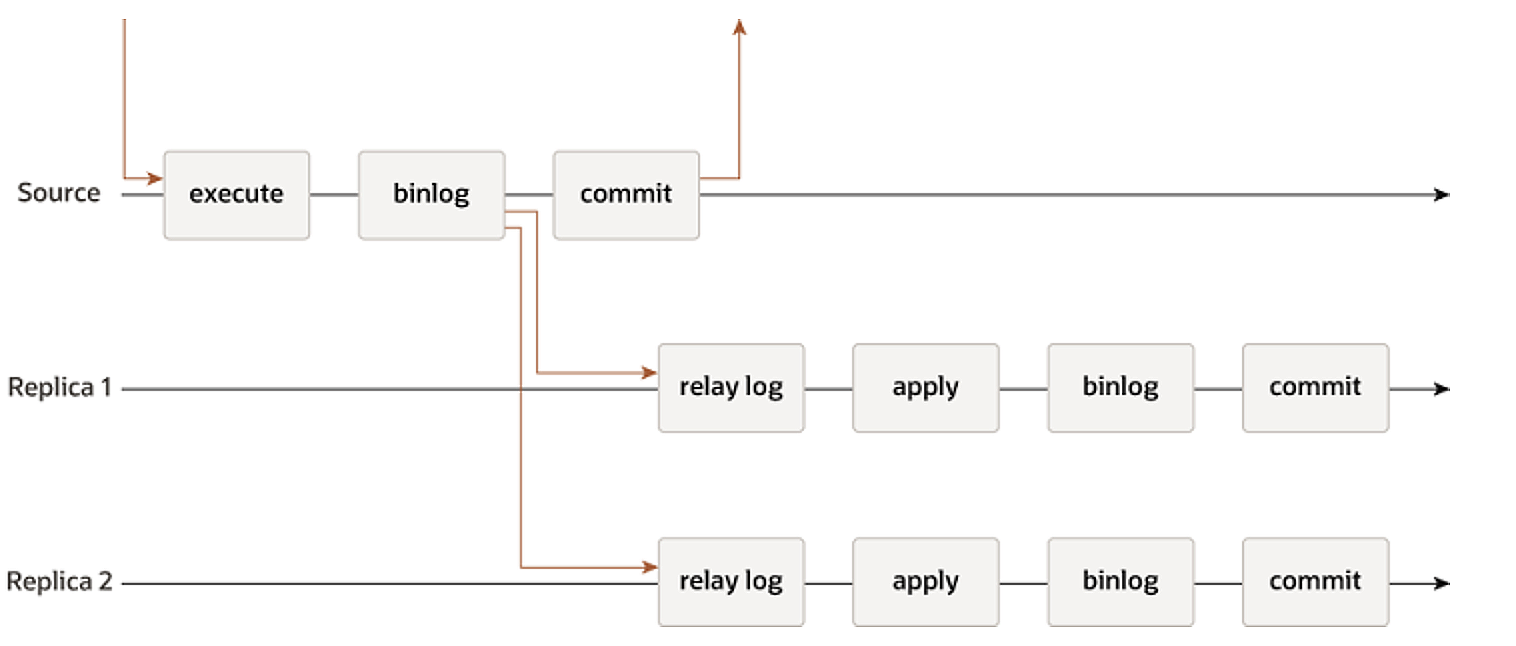
使用默认的异步复制时,主库上的事务提交时,Binlog会异步发送到备库上。由于是异步发送Binlog,因此在主库故障切换时,无法保证备库的数据和主库是完全一致的。
- 半同步复制
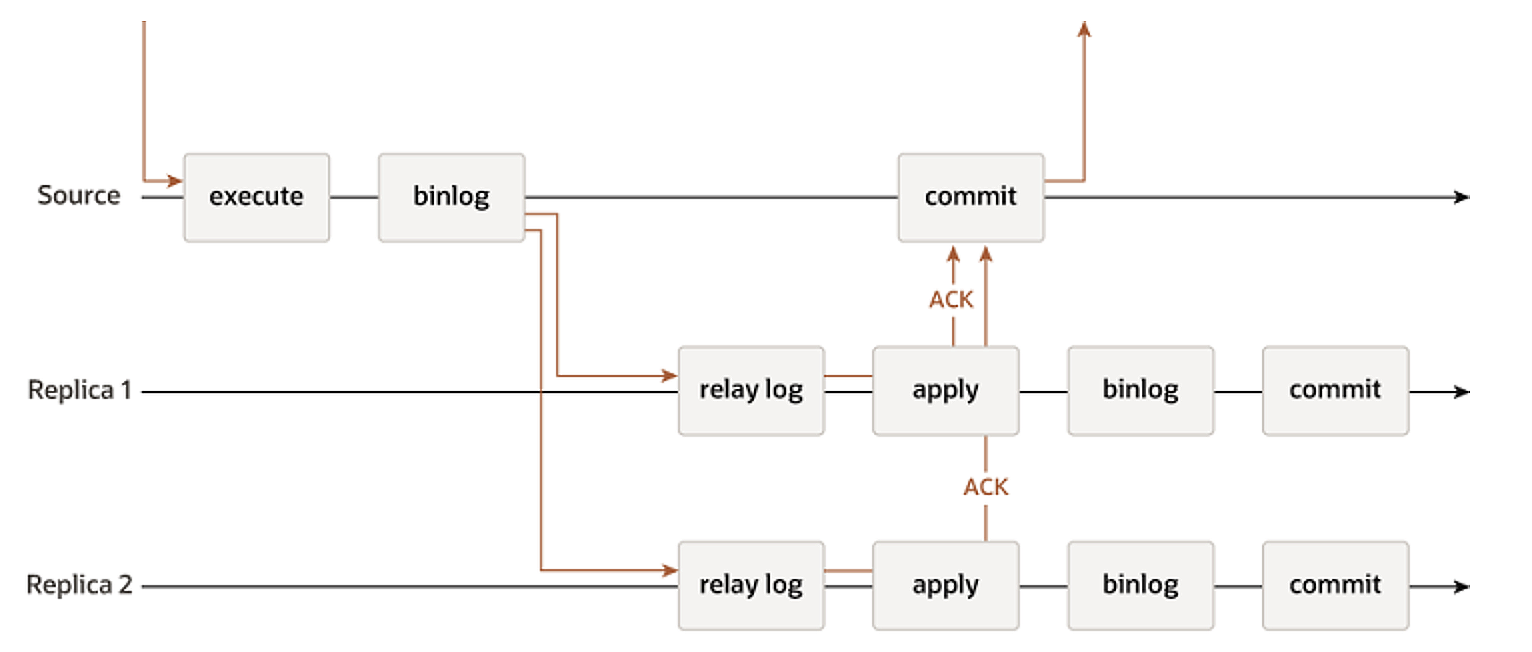
使用半同步复制时,主库提交事务时,会先等待Binlog发送给备库。但是这里等待可能会超时,半同步复制会退化成异步复制。
- 组复制(Group Replication)
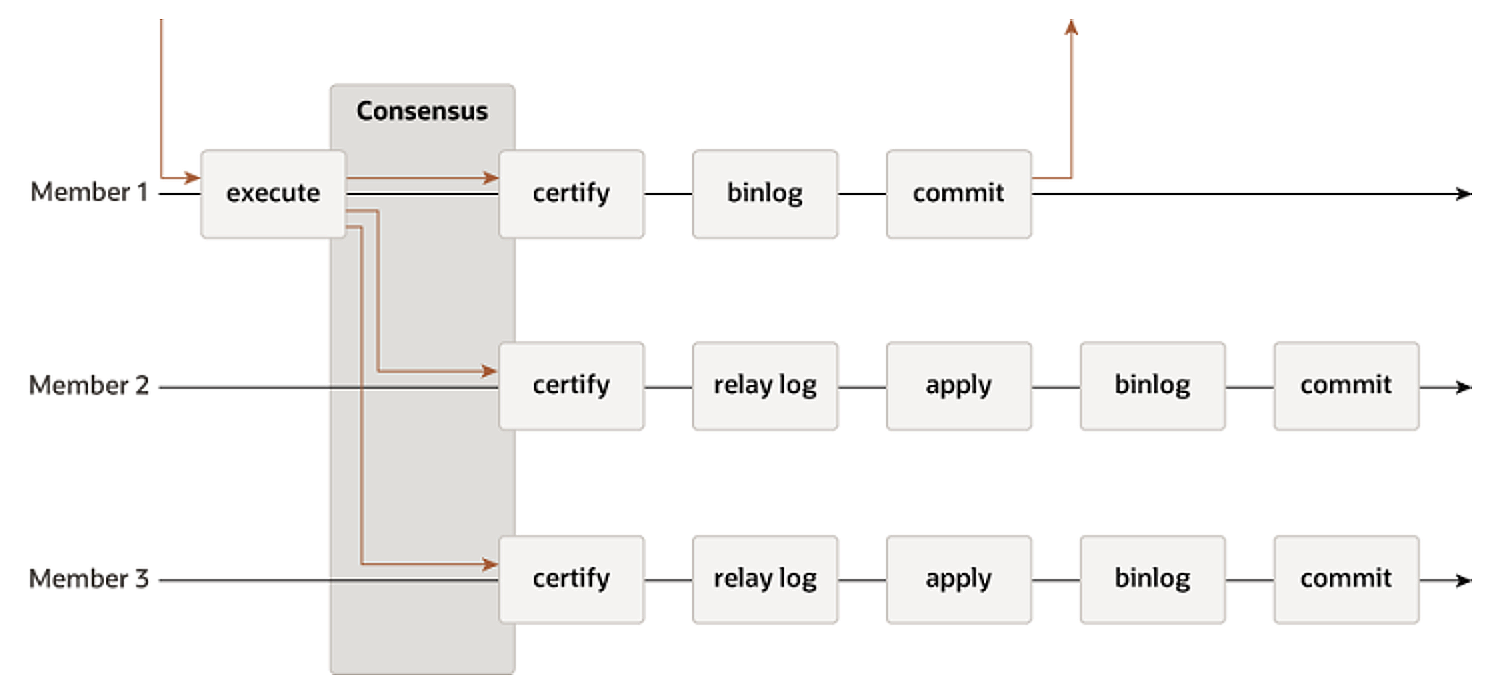
使用组复制时,主库的事务在提交之前,要先将Binlog发送到集群中的每个成员。由于使用了Paxos 协议,各个成员节点看到的事务提交消息的顺序是一致的。MGR支持多主,每个成员都可以独立提交事务。不同节点发起的事务可能会有冲突(比如修改了同一行数据),节点成员需要对事务消息进行冲突检测(certification),没有冲突的事务才能提交,如果事务有冲突,会回滚后执行的事务。
创建MRG集群
创建一个MGR集群主要包含下面这几个步骤。
- 配置第一个节点。
- 启动第一节点。
- 创建分布式恢复账号和通道。
- 配置其他节点.
- 将其他节点加入到MGR集群。
配置MGR节点参数
MGR集群中的节点,使用Binlog来将事务中修改的数据发送给其他节点。必须使用ROW格式的Binlog,而且要开启GTID。
下面这个表格里总结了MGR需要的一些参数。

下面这个样例配置文件中,提供了组复制需要的基础参数,你可以看一下。
1 | server_id=3307234 |
启动集群第一个节点
启动第一个节点时,需要将参数group_replication_bootstrap_group设置为ON。这个参数建议不要设置到参数文件中。
1 | set global group_replication_bootstrap_group=ON; |
启动后查看组复制状态。
1 | mysql> select * from performance_schema.replication_group_members\G |
创建分布式恢复账号和通道
分布式恢复是指一个节点加入MGR Group时,从其它节点获取数据、应用数据的过程。分布式恢复可分为全量恢复和增量恢复。全量恢复是指使用Clone机制,从集群中的一个节点全量备份和恢复数据。增量恢复是指通过获取binlog事件的方式来获取数据。
创建复制账号
复制账号可以只在第一个节点创建,其它节点从第一个节点复制数据时,创建账号的语句也会复制过去。也可以在每一个节点分别创建复制账号,这个时候需要先把sql_log_bin设置为OFF。
1 | CREATE USER rpl_user@'%' IDENTIFIED BY 'password'; |
账号需要REPLICATION SLAVE权限,用于订阅binlog。CONNECTION_ADMIN权限用于管理Group replication的连接。如果要使用clone机制进行全量数据同步,账号还需要BACKUP_ADMIN权限。如果集群节点内部通信使用MySQL协议(通信协议由group_replication_communication_stack参数指定),账号还需要GROUP_REPLICATION_STREAM权限。
配置复制通道
通道名称固定为group_replication_recovery。这里只需要设置用于分布式恢复的账号和密码,不需要指定IP和端口等信息,MGR会根据集群各节点的情况自动确定从哪个节点获取数据。
1 | -- MySQL 8.0.23之前的版本 |
每个节点上都需要配置复制通道,因为节点的角色在运行过程中可能会发生变化。
配置其他节点
my.cnf配置参数和第一个节点的配置基本一样,server_id需要设置成不一样的,group_replication_local_address根据节点IP设置。
1 | server_id=3307236 |
将其他节点加入集群
其他节点加入集群时,参数group_replication_bootstrap_group需要设置为OFF。执行语句start group_replication,把节点加入MGR集群。
1 | start group_replication; |
1 | mysql> select * from performance_schema.replication_group_members\G |
节点加入集群失败的常见原因
节点加入MGR集群时,如果有报错,或者加入集群后,节点的状态一直处于RECOVERING状态,就需要检查错误日志和其他报错信息,分析原因,进行处理。接下来我分别介绍常见的一些出错情况和解决方法。
- 节点上运行了异步复制
单主模式下,新加入集群的节点上如果还运行了异步复制,就会报下面这样的错。
1 | [ERROR] [MY-011638] [Repl] Plugin group_replication reported: 'Can't start group replication on secondary member with single-primary mode while asynchronous replication channels are running.' |
解决方法是停止异步复制,我建议你清理掉复制信息后再加入MGR集群。
1 | stop replica; |
- 节点上存在MGR集群中不存在的GTID
如果本地节点的gtid_executed中,有集群中不存在的GTID,也无法加入集群。
1 | [ERROR] [MY-011526] [Repl] Plugin group_replication reported: 'This member has more executed transactions than those present in the group. Local transactions: 0511eeb3-fad6-11ed-9a0f-fab81f64ee00:1-26:1000007-1000012, ad92133c-b33d-11ed-b947-fab81f64ee00:1-21 > Group transactions: 0511eeb3-fad6-11ed-9a0f-fab81f64ee00:1-26:1000007-1000014:2000009-2000029' |
解决方法是先清空节点的数据,重置gtid_executed,再加入集群。
1 | reset master; |
执行reset master命令后,本节点的gtid_executed也会被清空,此时再启动group replication时,会依赖MGR的分布式恢复机制,从其他节点获取全量或增量数据。
- 无法连接种子节点
如果节点无法和种子节点通信,或者在启动集群的第一个节点时,没有设置参数group_replication_bootstrap_group,会报下面这样的错。
1 | 2023-08-03T07:14:25.654388Z 0 [ERROR] [MY-011735] [Repl] Plugin group_replication reported: '[GCS] Error connecting to all peers. Member join failed. Local port: 33061' |
如果是启动第一个节点,先设置参数group_replication_bootstrap_group=ON,再开启group replication。如果集群已经启动,检查参数group_replication_group_seeds是否包含了已经启动的节点,并确认当前节点和种子节点之间可以正常通信。
- 恢复数据时认证失败
如果没有给复制通道设置正确的用户和密码,节点将无法连接到集群中的其他节点获取Binlog。
1 | [ERROR] [MY-013117] [Repl] Replica I/O for channel 'group_replication_recovery': Fatal error: Invalid (empty) username when attempting to connect to the source server. Connection attempt terminated. Error_code: MY-013117 |
检查复制通道是否配置正确。
1 | select user_name, user_password from mysql.slave_master_info |
并正确地配置复制通道。
1 |
|
使用caching_sha2_password认证插件时,可能会遇到下面这个报错。
1 | show slave status for channel 'group_replication_recovery'\G |
将参数group_replication_recovery_get_public_key设置为ON,建议将参数group_replication_recovery_get_public_key加入到配置文件中。
1 | set global group_replication_recovery_get_public_key=ON; |
- 未安装clone插件
如果本地节点和集群中节点的数据存在差异,需要做全量数据恢复,但是未启用clone插件时,会报这样的错。
1 | 2023-08-04T03:21:02.820332Z 0 [ERROR] [MY-013464] [Repl] Plugin group_replication reported: 'There was an issue when configuring the remote cloning process: The clone plugin is not present or active in this server.' |
你可以先将备份恢复到本地节点后,再加入集群。或者安装Clone插件后再加入集群。
1 | install plugin clone soname 'mysql_clone.so'; |
克隆完成后会重启实例,如果参数group_replication_start_on_boot没有设置为ON,那么当实例完成克隆并重启后,要手动执行start group_replication命令加入集群。
1 | start group_replication; |
- 节点数据不一致
如果节点数据不一致,Slave SQL线程应用Binlog时出错,会导致节点退出MGR集群。
1 | 2023-08-04T03:42:30.367578Z 15 [ERROR] [MY-010584] [Repl] Slave SQL for channel 'group_replication_applier': Worker 1 failed executing transaction '0511eeb3-fad6-11ed-9a0f-fab81f64ee00:1000018'; Could not execute Delete_rows event on table rep.test; Can't find record in 'test', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND, Error_code: MY-001032 |
这种情况下,要么重新同步全量数据,要么先修复不一致的数据,然后再开启group replication。
- 节点参数不一致
MGR要求某些参数在各个节点的设置必须保持一致。如果参数不一致,节点将无法加入集群。
1 | 2023-08-09T08:19:56.245265Z 0 [ERROR] [MY-011529] [Repl] Plugin group_replication reported: 'The member configuration is not compatible with the group configuration. Variables such as group_replication_single_primary_mode or group_replication_enforce_update_everywhere_checks must have the same value on every server in the group. (member configuration option: [group_replication_enforce_update_everywhere_checks], group configuration option: [group_replication_single_primary_mode]).' |
需要把参数和集群其他节点设置成一致后,再加入集群。下面这些参数需要保持一致。
1 | default_table_encryption |
- 老节点异常掉线后,无法加入集群
错误日志中有如下错误信息:Old incarnation found while trying to add node 172.16.121.234:33061 16917200391913458。
1 | [Warning] [MY-011735] [Repl] Plugin group_replication reported: '[GCS] Old incarnation found while trying to add node 172.16.121.234:33061 16917200391913458. Please stop the old node or wait for it to leave the group.' |
查看节点信息,异常节点的状态为UNREACHABLE。
1 | mysql> select * from performance_schema.replication_group_members; |
这是因为节点每次加入集群时,都会生成一串二进制数据(blob)来表示节点的身份,每次加入时,生成的blob都不一样。节点加入集群时,如果集群中还存在该节点上一次加入时的信息,就无法再次加入到集群中。这个例子中,blob就是上面错误日志中节点地址后那一串像时间戳的数字(16917200391913458)。
解决方法是重启整个集群。或者在集群中正常的节点上设置参数group_replication_force_members,强制剔除异常节点。
下面我演示一下如何用group_replication_force_members参数来解决这个问题。
1 | mysql> set global group_replication_force_members='172.16.121.236:33061'; |
然后再将其他节点加入集群。
1 | start group_replication; |
MGR集群维护
切换多主模式和单主模式
MGR集群可分为多主模式和单主模式两种设置。多主模式下,集群中的每个节点都可以发起写入操作。单主模式下,只有一个主节点,只有主节点才能发起写入操作,其它节点不能发起写入操作。
可通过参数group_replication_single_primary_mode查看集群的当前模式。单主模式下group_replication_single_primary_mode设置为ON,同时group_replication_enforce_update_everywhere_checks参数设置为OFF。相反的,在多主模式下group_replication_single_primary_mode设置为OFF,group_replication_enforce_update_everywhere_checks设置为ON。
多主模式和单主模式之间可以互相在线切换。我们用函数group_replication_switch_to_multi_primary_mode从单主模式切换成多主模式。
1 | mysql> select group_replication_switch_to_multi_primary_mode(); |
用函数group_replication_switch_to_single_primary_mode()从多主模式切换成单主模式。
1 | mysql> show variables like '%single_primary_mode%'; |
多主模式切换为单主模式时,如果函数不传参数,就会发起一次选举,确定新的主节点。如果传入了节点的UUID,会把对应的节点设置为主节点。
1 | mysql> select @@server_uuid; |
进行单主和多主模式切换后,会自动设置参数group_replication_single_primary_mode和group_replication_enforce_update_everywhere_checks。需要注意,新节点加入集群时,这2个参数的设置要和集群其它节点的设置一致,否则节点无法加入集群。
切换写节点
单主模式下,如果主节点发生异常,集群会发起选举,选择新的主节点。也可以通过函数group_replication_set_as_primary指定新的主节点。
1 | mysql> select member_id,member_host, member_state, member_role |
完全重启MGR集群
在一些情况下,可能会需要重启整个集群。比如机房停电,整个集群的所有服务器都重启了。或者修改某些MGR参数时(如group_replication_communication_stack),需要重启集群。
重启集群时,有几点需要注意。
- 重启集群时,要选一个种子节点,种子节点启动前要设置参数group_replication_bootstrap_group=ON。其他节点加入集群时,参数group_replication_bootstrap_group必须设置为OFF。
- 要选择数据最新的节点作为种子节点,也就是要选执行和认证完成的事务最多的那个节点。启动全新的MGR集群时,不需要做这一步。但重启老的集群时,这一步非常重要。如果不是用最新的节点来启动集群,会导致含有更新的数据的节点将无法加入集群,因为节点能加入集群的一个前提条件是该节点的gtid_executed是MGR集群的gtid集合的子集。
具体的执行步骤如下:
步骤1:停止组复制。
在集群的每一个节点上执行stop group_replication命令。
1 | stop group_replication; |
将参数group_replication_start_on_boot设置为OFF,重启MySQL实例。实例启动后,确认group replication没有启动。
1 | SELECT * FROM performance_schema.replication_group_members; |
确认MEMBER_STATE为OFFLINE。
获取并记录实例的gtid_executed变量和group_replication_applier通道中接收到的gitd集合。
1 | SELECT @@GLOBAL.GTID_EXECUTED; |
步骤2:对比步骤1收集到的gtid集合信息,选择gitd最多的那个节点作为种子节点。
步骤3:在步骤2选出来的种子节点上执行下面这些命令,启动集群。
1 | mysql> SET GLOBAL group_replication_bootstrap_group=ON; |
步骤4:在种子节点上检查集群启动状态。
1 | SELECT * FROM performance_schema.replication_group_members; |
检查上述查询的输出,确认MEMBER_STATE为ONLINE。
步骤5:在其他节点上执行start group_replication命令,将节点加入到集群中。
1 | mysql> start group_replication; |
步骤6:检查集群状态,确认所有节点已经加入集群,并且MEMBER_STATE都为ONLINE。
1 | mysql> SELECT * FROM performance_schema.replication_group_members; |
MGR监控
使用组复制时,会用到performance_schema中的一些表,来监控MGR集群的状态,包括集群中每个节点的状态是否正常,事务接收和事务执行是否有异常,事务是否有积压。
接下来我对这些表做一个简单的介绍,供你参考。
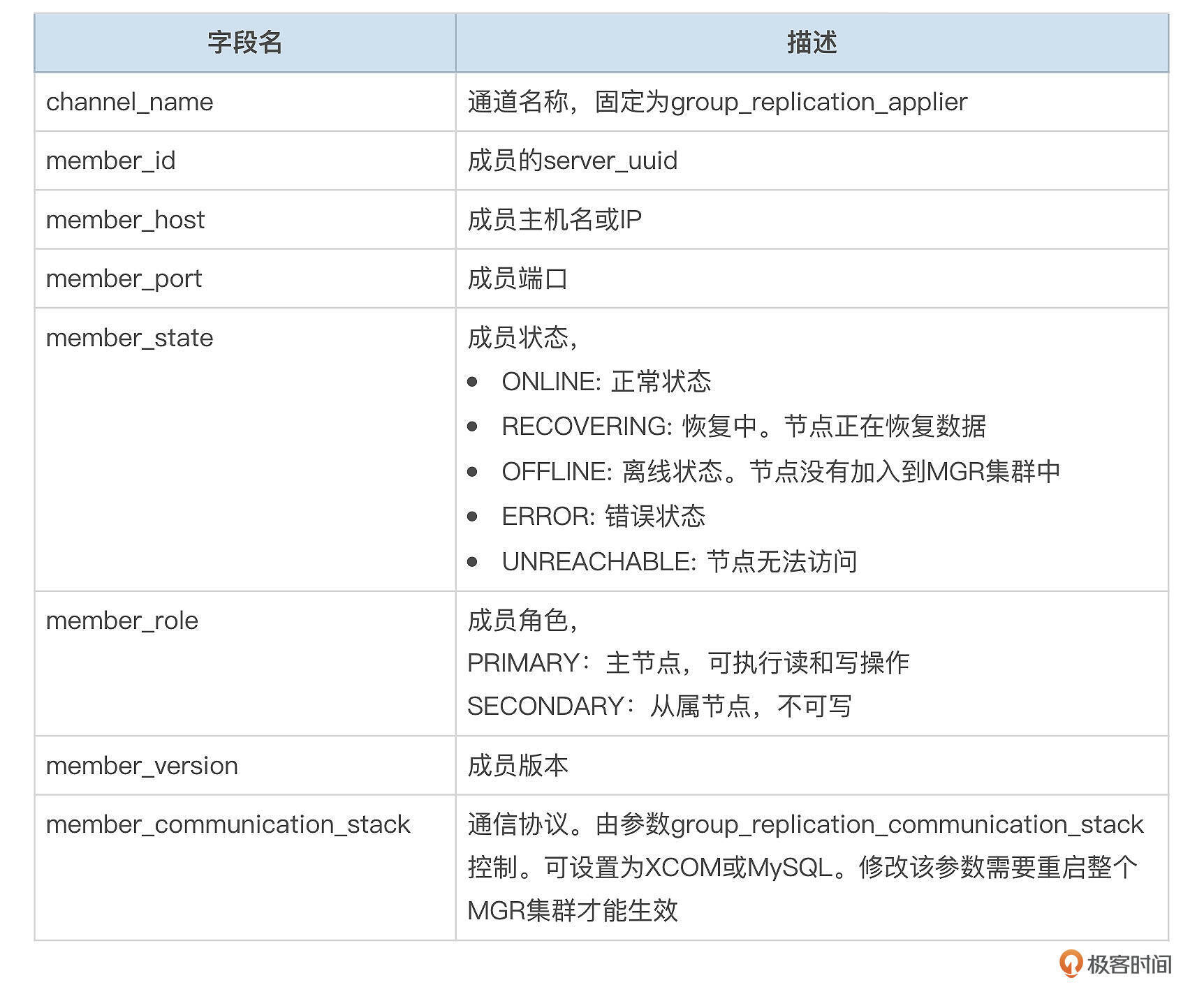
- replication_group_members表记录了MGR集群成员。
- replication_group_member_stats表记录集群中各个节点事务相关的统计信息,包括检查队列中的事务数、应用队列中的事务数等。
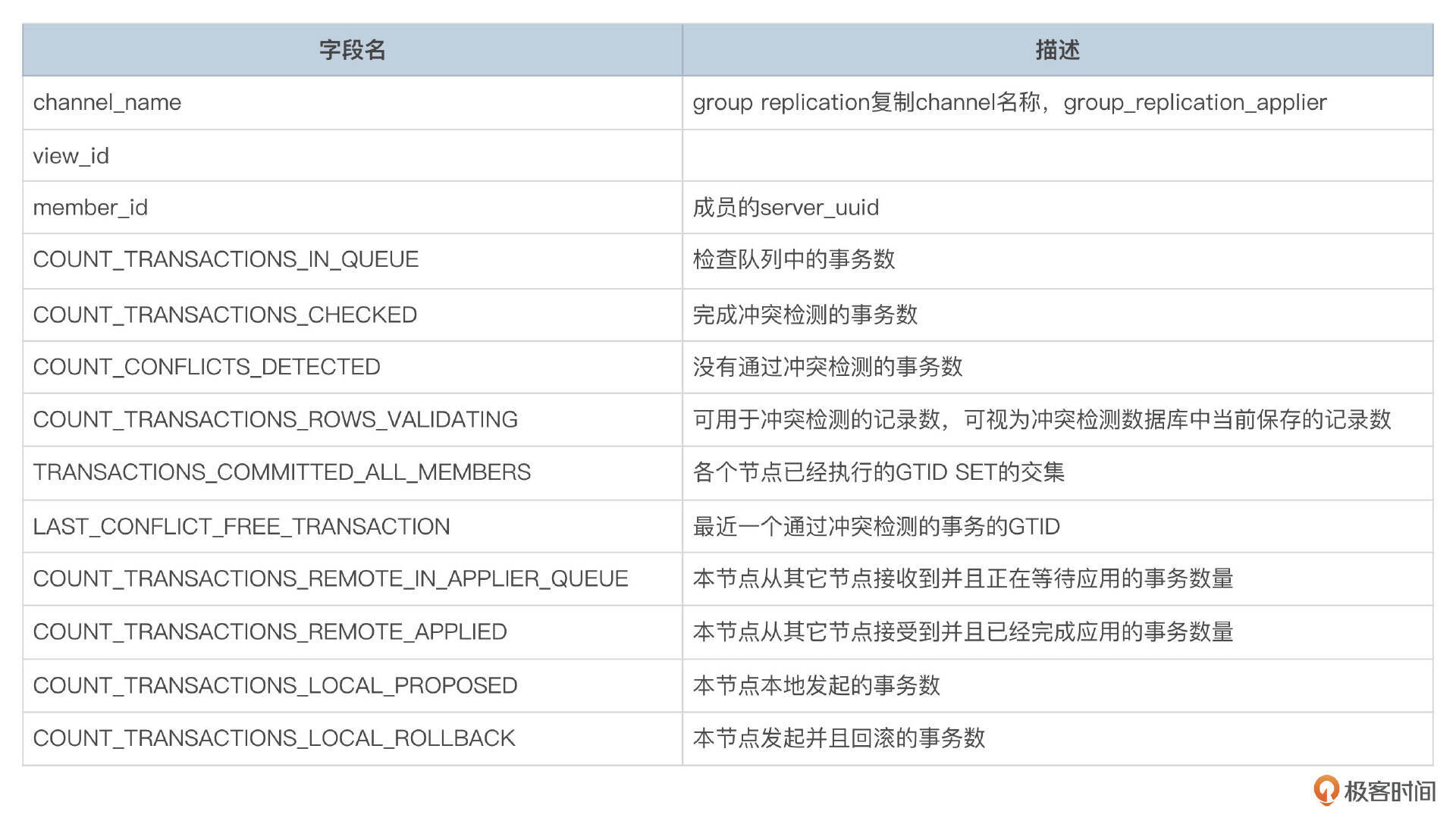
- replication_connection_status
replication_connection_status记录了复制通道的状态。MGR中会使用到group_replication_applier和group_replication_recovery这两个通道。
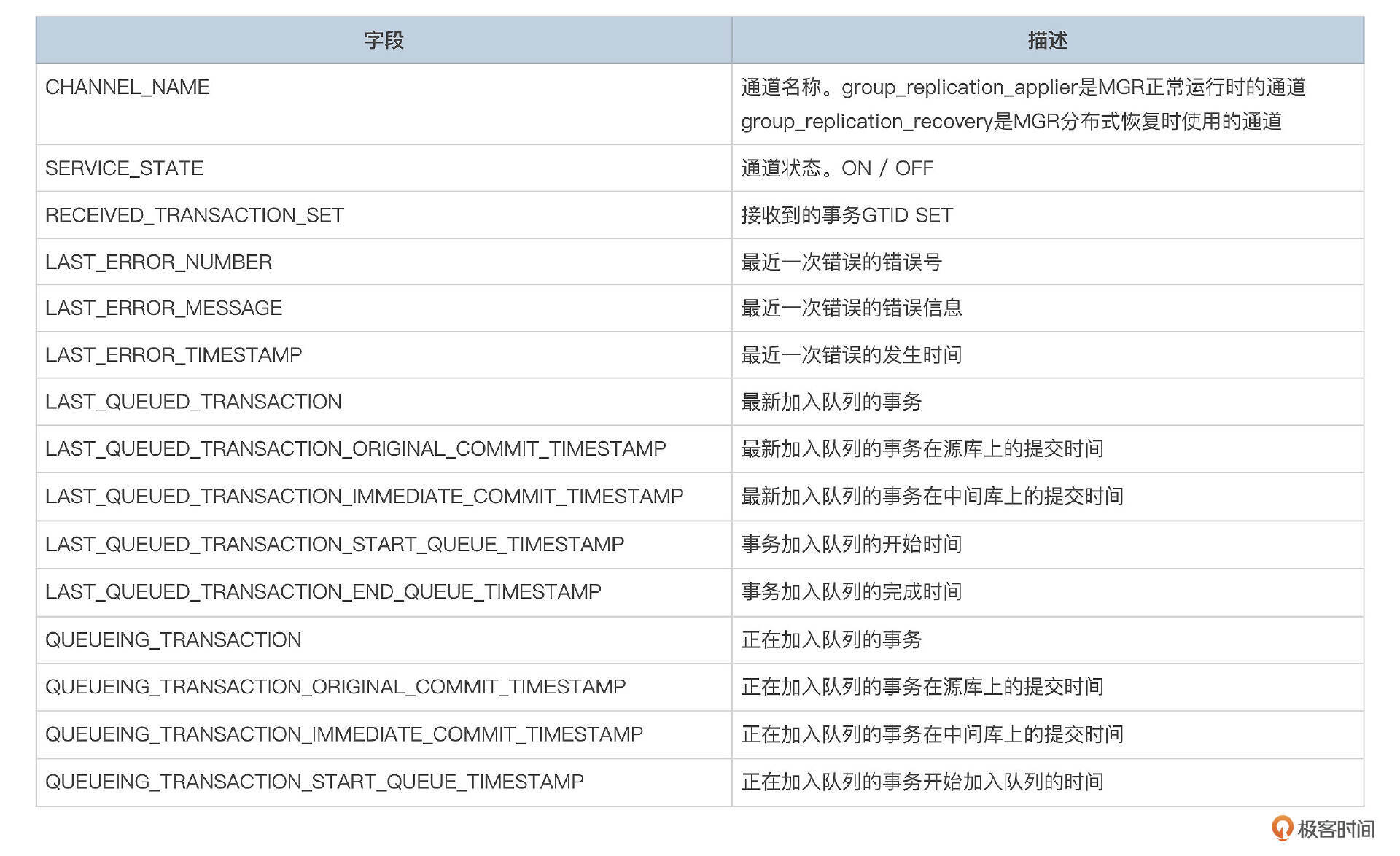
- replication_applier_status
- replication_applier_status_by_coordinator
- replication_applier_status_by_worker
节点上事务应用状态可以从replication_applier_status、replication_applier_status_by_coordinator、replication_applier_status_by_worker这几个表查看。
replication_applier_status_by_coordinator表记录了协调线程的状态。replication_applier_status_by_worker记录了每个工作线程的状态。如果事务应用报错了,可以查看这几个表。
总结
组复制是MySQL用来保证集群中各个节点数据完全一致的技术。使用组复制,在运维上会增加一定的复杂度,而且在性能上也会有一些开销。如果要使用组复制,要评估开启组复制后,性能是否能满足业务需求,特别是要评估当集群中有节点出现问题时,整个集群的性能。还要评估节点加入集群、退出集群对整体性能的影响。
虽然MGR支持多个主节点,但我个人建议使用单主模式。使用组复制,有一个好处,是主节点故障时,可以自动将主节点切换到其他节点上,配合使用一些数据库Proxy软件,可以实现业务的高可用。
思考题
我们说组复制能保证集群中各个节点的数据完全一致。但是在默认的设置下,只能说主库提交的事务,Binlog一定已经复制到了集群中的大多数节点上,但是其他节点在应用Binlog时,还是可能会存在延迟的。因此,应用程序连接到不同的节点读取数据时,有可能会读取到不一致的数据。对这个问题,可以怎么来解决呢?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见。