你好,我是黄佳。
今天,我们来探索大语言模型在另一个传统自然语言处理应用场景中的突破,就是长文档的总结和评估,这也是大语言模型的一个重要应用方向。我们将探讨如何利用大语言模型的强大能力,实现高质量的文档总结,并对总结结果进行全面评估。
新一代大模型出现之前的文档总结
文档总结是一个经典课题。传统的文档总结方法通常基于统计学和信息检索理论,如提取关键词、句子排序等。这些方法虽然简单高效,但在处理长文档、复杂语义时往往力不从心。
老一代的大模型文档总结通常采用两种范式:文本抽取式(Extractive)和摘要生成式(Abstractive)。
- 抽取式方法是从原文中选取关键句作为摘要。比如基于BERT的文档总结就常常使用这个范式。
- 生成式方法则根据对原文的理解,生成新的摘要文本。比如基于初代GPT、T5、BART等生成式模型的文档总结就基于这个范式。
下面,让我带着你用一个经典“老”NLP模型 T5,来做一个论文的摘要总结。论文我们随便选择一个就可以了,这里,我选择的是 Tiny Llama 这篇论文,先看看它主要说了什么。
这篇论文介绍的TinyLlama是一个1.1B参数的小型语言模型,在约1万亿Token上预训练了3个Epoch。它采用了Llama 2的架构和分词器,并利用了开源社区贡献的各种进展(如FlashAttention)以提高计算效率。尽管规模相对较小,但TinyLlama在一系列下游任务中表现出色,优于具有相似规模的现有开源语言模型。
首先,导入PyPDF2包,打开论文文件,读取PDF文件内容。
1 | # 导入PyPDF2包 |
然后,导入T5模型和分词器, 定义函数来加载模型和分词器。
1 | # 导入T5模型和分词器 |
最后,就可以通过T5模型来做文档总结啦!
1 | # 定义函数进行文本总结 |
程序输出如下:
1 | TinyLlama is a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. despite its relatively small size, it significantly outperforms existing open-source language models with compara-ble sizes. |
结果看起来不错,对吗?其实不然。
首先,T5的总结结果其实更像是论文开头部分的照搬照抄。另外,你在程序中应该注意到max_length=512这个参数,其实传统的“大”语言模型,如BERT、T5,一般情况下,只能够接受512,最多1024个Token,可不像新一代的模型动不动就可以接受几万、几十万的Token作为上下文。
因此,我们所看到的Summary结果,只不过是对整个论文第一段话的总结。😁
对于老一代模型来说,针对文档总结任务对大模型进行微调(Fine-tune),也可以进一步提升它们的摘要质量。微调使模型更加适应特定领域的文本,学习总结的格式和风格。在一些研究中还提出了复杂的Prompt设计,引导模型生成满足特定需求的摘要。
当然,现在有了真正的大模型,这种微调也已经是昨日黄花了。
用新一代的大模型做文档总结
ChatGPT等新一代大语言模型的出现,为文档总结带来了新的突破。这些模型在海量文本数据上进行预训练,学习到了丰富的语言知识和通用表示。它们能够深入理解文本的语义、结构、样式等各个方面,生成连贯、通顺的摘要。
好啦,话不多说,我们现在利用强大的Claude-3 Opus,来生成真正高效的PDF论文总结。
首先,导入PyPDF2包,打开论文文件,读取PDF文件内容。这个步骤和代码前面已介绍。
然后,导入anthropic库,并设置API密钥。
1 | from dotenv import load_dotenv |
接下来,我们构造一个名为generate_summary的函数,用于利用Claude模型生成研究论文的摘要。这个函数接受一个参数text,即要总结的论文全文,然后会返回全文的总结。
1 | def generate_summary(text): |
我们创建了一个Anthropic客户端对象,用于与Claude模型进行交互。在系统提示中,我们告诉Claude它是一个用于总结研究论文的AI助手。
接下来,我们构造了一个消息列表,其中包含一条用户消息,并在消息的内部中通过 {text} 变量嵌入了要总结的论文全文。我们还在消息中提供了一些指示,要求Claude关注论文的关键发现、方法和结论,并生成一个大约150字的简洁摘要。
client.messages.create方法会将所构造的消息列表、系统提示以及其他参数传递给Claude。Claude会根据这些信息生成论文的摘要,并返回结果。
最后,使用Claude生成总结并保存。
1 | # 使用Claude生成总结 |
运行程序后,得到的总结文字如下:

1 | Summary: |
翻译成中文:
TinyLlama是一个开源的11亿参数语言模型,在大约1万亿个标记上预训练了3个周期。它利用了开源社区的进展来实现更好的计算效率。尽管其规模较小,但TinyLlama在衡量常识推理和解决问题能力的各种下游任务上显著优于现有的相似规模的开源语言模型。作者在预训练期间跟踪了TinyLlama在基准测试中的表现,发现其准确性通常随着计算量的增加而提高,超过了Pythia-1.4B。TinyLlama的预训练代码、中间检查点和数据处理细节已经公开发布。作者认为,TinyLlama的紧凑尺寸和强大性能使其成为研究人员测试与语言模型相关的创新想法的有吸引力的平台。他们计划根据从这个开放研究项目中获得的经验,开发具有增强功能的TinyLlama的未来版本。
这个总结非常非常优秀。它并不是像刚才 T5 模型那样,只是对头几行文字的简单copy,而是详实地介绍出了TinyLlama这篇论文的主要工作、意义和创新点,以及作者的评述及未来计划。
评估文档总结的优劣
不过,口说无凭,我们需要想一些办法来量化这个总结的优质程度。这不仅可以帮助我们了解总结的效果,还可以为进一步优化模型提供依据。
所以,下面我们的目标就是通过不同的方法来量化文档总结的优质程度。
基于真值的评估
在文档总结领域,基于真值的评估是常见的方法。文档总结的真值并不是那么容易获得的,好在对于论文来说,我们可以使用论文摘要作为真值,然后通过计算生成的总结与真值之间的相似度来评估质量。
有了真值之后,常用的经典评估指标包括 ROUGE 和 BERTScore。
ROUGE 评估
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一组用于自动化评估机器翻译和自动摘要系统性能的指标,要衡量生成摘要与参考摘要之间的重叠情况,特别关注回忆率(Recall)。
ROUGE主要有三种变体:ROUGE-N、ROUGE-L和ROUGE-S,从不同的角度评估摘要的质量。
1. ROUGE-N
ROUGE-N是基于N-gram的匹配来评估生成摘要与参考摘要之间的相似度。N-gram可以是单个词(unigram)、双词(bigram)、三词(trigram)等。常见的ROUGE-N指标包括ROUGE-1和ROUGE-2,分别表示基于unigram和bigram的匹配情况。
- ROUGE-1:计算生成摘要和参考摘要之间的unigram匹配。
- ROUGE-2:计算生成摘要和参考摘要之间的bigram匹配。
ROUGE-N的计算公式如下:
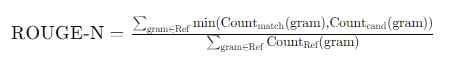
其中,Countmatch(gram) 表示生成摘要中 N-gram 的匹配次数,CountRef(gram) 则表示参考摘要中N-gram的总次数。
2. ROUGE-L
ROUGE-L基于最长公共子序列(Longest Common Subsequence, LCS)来评估生成摘要和参考摘要之间的相似度。通过计算生成摘要和参考摘要之间的最长公共子序列匹配情况,LCS能够捕捉到全局序列信息,而不仅仅是局部的N-gram匹配。
ROUGE-L的计算公式如下:
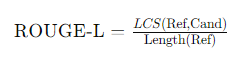
其中,LCS(Ref,Cand) 表示生成摘要和参考摘要之间的最长公共子序列的长度,Length(Ref)表示参考摘要的长度。
3. ROUGE-S
ROUGE-S(Skip-Bigram)基于跳跃双词(skip-bigram)来评估生成摘要和参考摘要之间的相似度。通过计算生成摘要和参考摘要之间的跳跃双词匹配情况,跳跃双词允许在不改变词序的情况下跳过一些词,这样可以更灵活地捕捉摘要中的词对关系。
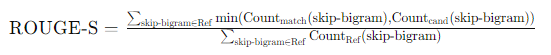
因此,ROUGE评估指标能够从不同的角度评估生成摘要和参考摘要之间的相似度,涵盖了局部N-gram匹配(ROUGE-N)、全局序列信息(ROUGE-L)和灵活词对关系(ROUGE-S)。结合这些指标,我们就可以全面衡量生成摘要的质量。
下面是使用ROUGE评估生成摘要的示例代码。
1 | # 读取摘要文件 |
输出如下:
1 | ROUGE Scores: |
这样,就可以计算生成摘要和参考摘要的ROUGE分数,并从精确率(Precision)、召回率(Recall)和F1分数(F1-Score)三个方面进行分析。如果仅从ROUGE指标看,T5竟然比Claude这种大模型总结得还要好?真的如此吗?我们继续看其他指标。
BERTScore 评估
BERTScore则是另一种评估方法,它通过计算生成的摘要和参考摘要的BERT嵌入表示之间的相似度来评估摘要的质量。
相比于ROUGE,BERTScore利用了词向量的思想,因此就能够更好地捕捉语义上的相似度。
1 | from bert_score import BERTScorer |
输出如下:
1 | T5 Summary BERTScore F1: 0.9143788814544678 |
我们得到生成摘要和参考摘要的BERTScore分数,以此来衡量它们的语义相似度。从这个指标来看,T5和大模型总结得分很相似。
使用 Claude 进行评估
除了使用传统的评估指标,我们还可以利用Claude/GPT-4这样的新一代大模型来进行更全面的评估。大模型不仅能够生成高质量的文档总结,还能够根据你自己定制的评估标准对总结进行评分。
我们可以定义几个关键的评估标准,包括相关性、准确性、简洁性、连贯性、一致性、流畅性等。
每个标准都会有它具体的评分规则,我们这里选择几个。
- 相关性:评估摘要是否涵盖了原文中最重要和核心的信息。
- 准确性:评估摘要中的信息是否准确反映了原文的内容,是否存在误导或错误信息。
- 简洁性:评估摘要是否在简明扼要的基础上传达了主要信息,而不是冗长或重复。
以下是使用Claude(你可以选择GPT或者其他国内大模型,对Claude的总结进行交叉评估)进行评估的示例代码。
1 | # Claude评估函数 |
Claude基于对原文和摘要的深度理解,从多个角度对摘要质量做出了判断。
1 | Claude Evaluation Scores: |
此时,终于,Claude这种新一代大模型的总结能力,在评估指标上超越了T5。可见,这种全方位的评估更接近于我们人类的评估水准,这就有助于我们优化摘要模型,生成更高质量的摘要。
以上,就是几种常用的文档总结评估方式。这些评估方法,对其他NLP任务,比如机器翻译、句子配对等等,亦有启发。综合利用这些评估方法,我们可以更好地了解文档总结的效果,并进一步优化我们的模型。
总结时刻
今天,我们探讨了如何利用大语言模型实现智能化的文档总结与评估。我介绍了大模型文档总结的理论基础,展示了使用Claude生成和评估摘要的实战示例,如果你没有Claude API,你当然也可以用其他大模型来尝试做相同的工作。可以看到,无论是生成摘要,还是评估摘要,Prompt设计在引导模型完成特定任务中至关重要。
得益于大模型强大的语言理解和生成能力,我们可以实现高质量的摘要生成,并对摘要进行全面、客观的评估。传统的基于真值的评估方法(如ROUGE和BERTScore)可以提供一定的量化指标,而新一代的大模型(如Claude)则可以提供更丰富和深入的评估信息。
未来,随着大语言模型的进一步发展,其在文档总结领域的应用将更加广泛和深入。结合知识图谱、多模态等技术,能实现更加智能、个性化的摘要服务。同时,对话式摘要、增量式摘要等新型交互和优化范式值得关注和探索。
思考题
- 新一代大模型的总结比旧的语言模型总结能力强,这是毫无疑问的,那么为什么在我们的评估结果中,似乎是T5总结得更好? 从ROUGE上看,尤其如此。这其实是有原因的,你能找出关键原因么?
- 如何拓展大语言模型摘要评估的维度? 比如,你可以结合专家知识,设计出更加全面、更细粒度的评估指标和评估提示词。
- 除了学术论文,大语言模型Claude当然还可以应用于多种文档总结任务,如新闻、财报、医疗病历,请你基于手头的业务数据尝试一下!尤其是思考真值如何获取。
期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!