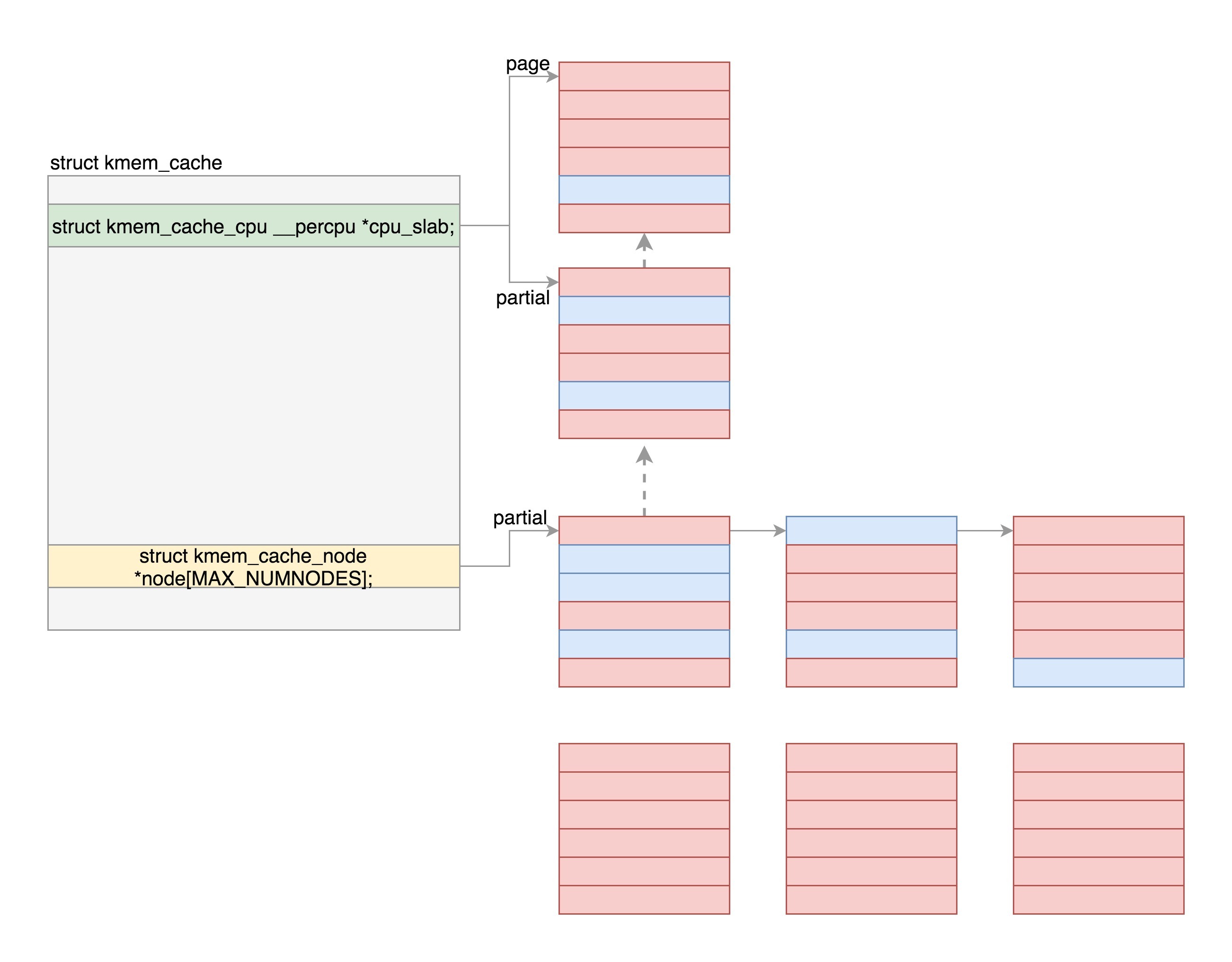
struct kmem_cache { struct kmem_cache_cpu __percpu *cpu_slab; /* Used for retriving partial slabs etc */ unsigned long flags; unsigned long min_partial; int size; /* The size of an object including meta data */ int object_size; /* The size of an object without meta data */ int offset; /* Free pointer offset. */ #ifdef CONFIG_SLUB_CPU_PARTIAL int cpu_partial; /* Number of per cpu partial objects to keep around */ #endif struct kmem_cache_order_objects oo; /* Allocation and freeing of slabs */ struct kmem_cache_order_objects max; struct kmem_cache_order_objects min; gfp_t allocflags; /* gfp flags to use on each alloc */ int refcount; /* Refcount for slab cache destroy */ void (*ctor)(void *); ...... const char *name; /* Name (only for display!) */ struct list_head list; /* List of slab caches */ ...... struct kmem_cache_node *node[MAX_NUMNODES]; };
struct kmem_cache_cpu { void **freelist; /* Pointer to next available object */ unsigned long tid; /* Globally unique transaction id */ struct page *page; /* The slab from which we are allocating */ #ifdef CONFIG_SLUB_CPU_PARTIAL struct page *partial; /* Partially allocated frozen slabs */ #endif ...... };
/* * Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc) * have the fastpath folded into their functions. So no function call * overhead for requests that can be satisfied on the fastpath. * * The fastpath works by first checking if the lockless freelist can be used. * If not then __slab_alloc is called for slow processing. * * Otherwise we can simply pick the next object from the lockless free list. */ static __always_inline void *slab_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node, unsigned long addr) { void *object; struct kmem_cache_cpu *c; struct page *page; unsigned long tid; ...... tid = this_cpu_read(s->cpu_slab->tid); c = raw_cpu_ptr(s->cpu_slab); ...... object = c->freelist; page = c->page; if (unlikely(!object || !node_match(page, node))) { object = __slab_alloc(s, gfpflags, node, addr, c); stat(s, ALLOC_SLOWPATH); } ...... return object; }
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, unsigned long addr, struct kmem_cache_cpu *c) { void *freelist; struct page *page; ...... redo: ...... /* must check again c->freelist in case of cpu migration or IRQ */ freelist = c->freelist; if (freelist) goto load_freelist;
/* * The background pageout daemon, started as a kernel thread * from the init process. * * This basically trickles out pages so that we have _some_ * free memory available even if there is no other activity * that frees anything up. This is needed for things like routing * etc, where we otherwise might have all activity going on in * asynchronous contexts that cannot page things out. * * If there are applications that are active memory-allocators * (most normal use), this basically shouldn't matter. */ static int kswapd(void *p) { unsigned int alloc_order, reclaim_order; unsigned int classzone_idx = MAX_NR_ZONES - 1; pg_data_t *pgdat = (pg_data_t*)p; struct task_struct *tsk = current;
/* * This is a basic per-node page freer. Used by both kswapd and direct reclaim. */ static void shrink_node_memcg(struct pglist_data *pgdat, struct mem_cgroup *memcg, struct scan_control *sc, unsigned long *lru_pages) { ...... unsigned long nr[NR_LRU_LISTS]; enum lru_list lru; ...... while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] || nr[LRU_INACTIVE_FILE]) { unsigned long nr_anon, nr_file, percentage; unsigned long nr_scanned;