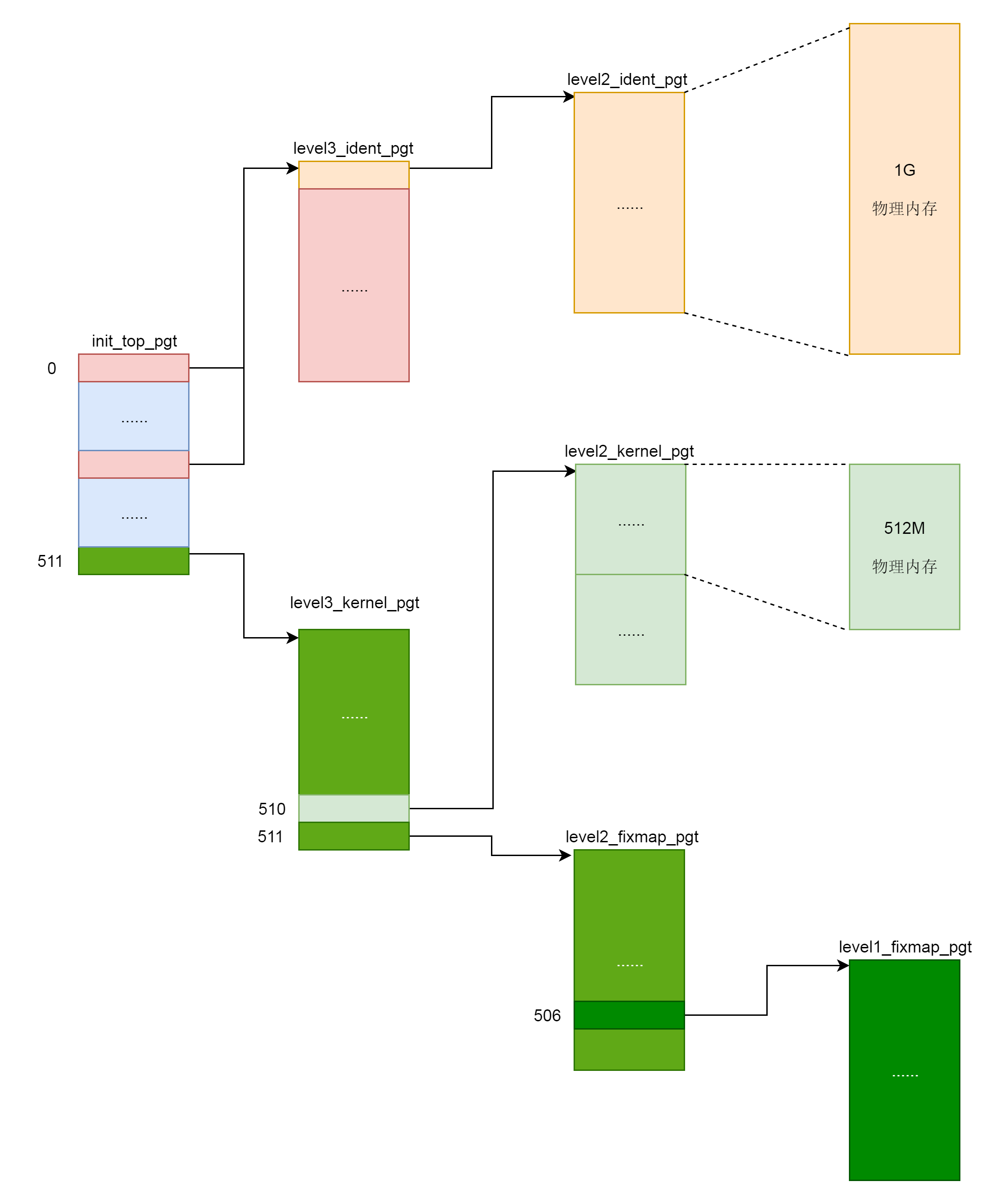
NEXT_PAGE(level3_ident_pgt) .quad level2_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE .fill 511, 8, 0 NEXT_PAGE(level2_ident_pgt) /* Since I easily can, map the first 1G. * Don't set NX because code runs from these pages. */ PMDS(0, __PAGE_KERNEL_IDENT_LARGE_EXEC, PTRS_PER_PMD)
NEXT_PAGE(level2_kernel_pgt) /* * 512 MB kernel mapping. We spend a full page on this pagetable * anyway. * * The kernel code+data+bss must not be bigger than that. * * (NOTE: at +512MB starts the module area, see MODULES_VADDR. * If you want to increase this then increase MODULES_VADDR * too.) */ PMDS(0, __PAGE_KERNEL_LARGE_EXEC, KERNEL_IMAGE_SIZE/PMD_SIZE)
void __init setup_arch(char **cmdline_p) { /* * copy kernel address range established so far and switch * to the proper swapper page table */ clone_pgd_range(swapper_pg_dir + KERNEL_PGD_BOUNDARY, initial_page_table + KERNEL_PGD_BOUNDARY, KERNEL_PGD_PTRS);
/* * Create page table mapping for the physical memory for specific physical * addresses. The virtual and physical addresses have to be aligned on PMD level * down. It returns the last physical address mapped. */ unsigned long __meminit kernel_physical_mapping_init(unsigned long paddr_start, unsigned long paddr_end, unsigned long page_size_mask) { unsigned long vaddr, vaddr_start, vaddr_end, vaddr_next, paddr_last;
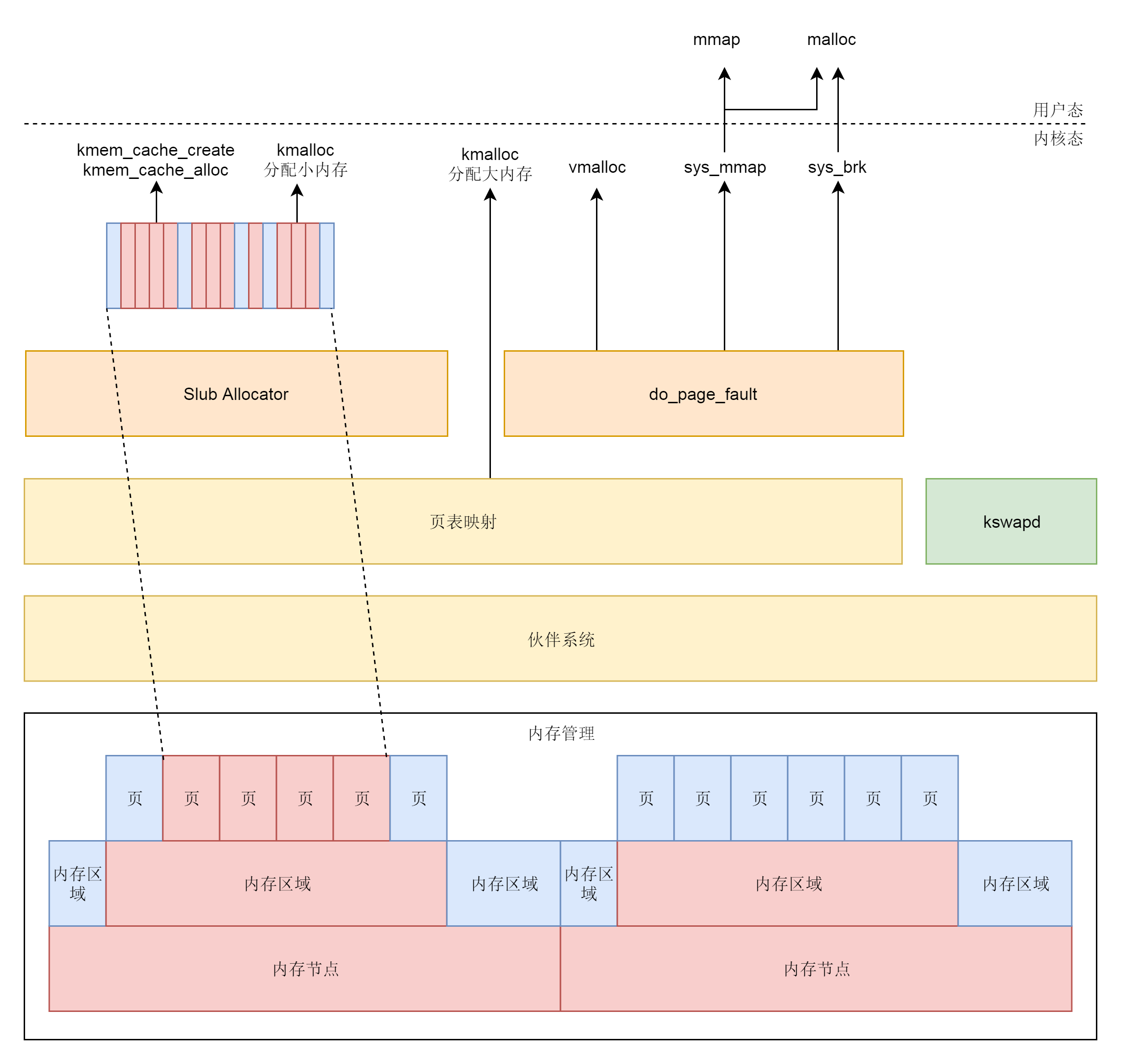
/** * vmalloc - allocate virtually contiguous memory * @size: allocation size * Allocate enough pages to cover @size from the page level * allocator and map them into contiguous kernel virtual space. * * For tight control over page level allocator and protection flags * use __vmalloc() instead. */ void *vmalloc(unsigned long size) { return __vmalloc_node_flags(size, NUMA_NO_NODE, GFP_KERNEL); }
static void *__vmalloc_node(unsigned long size, unsigned long align, gfp_t gfp_mask, pgprot_t prot, int node, const void *caller) { return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END, gfp_mask, prot, 0, node, caller); }
/* * 32-bit: * * Handle a fault on the vmalloc or module mapping area */ static noinline int vmalloc_fault(unsigned long address) { unsigned long pgd_paddr; pmd_t *pmd_k; pte_t *pte_k;
/* Make sure we are in vmalloc area: */ if (!(address >= VMALLOC_START && address < VMALLOC_END)) return -1;
/* * Synchronize this task's top level page-table * with the 'reference' page table. * * Do _not_ use "current" here. We might be inside * an interrupt in the middle of a task switch.. */ pgd_paddr = read_cr3_pa(); pmd_k = vmalloc_sync_one(__va(pgd_paddr), address); if (!pmd_k) return -1;
pte_k = pte_offset_kernel(pmd_k, address); if (!pte_present(*pte_k)) return -1;