你好,我是Tyler。
前几节课中,我们学习了如何让大语言模型高效地利用外部记忆,来增强自己的能力。今天这节课,我们重点来学习一下如何高效地存储和检索这些外部记忆。
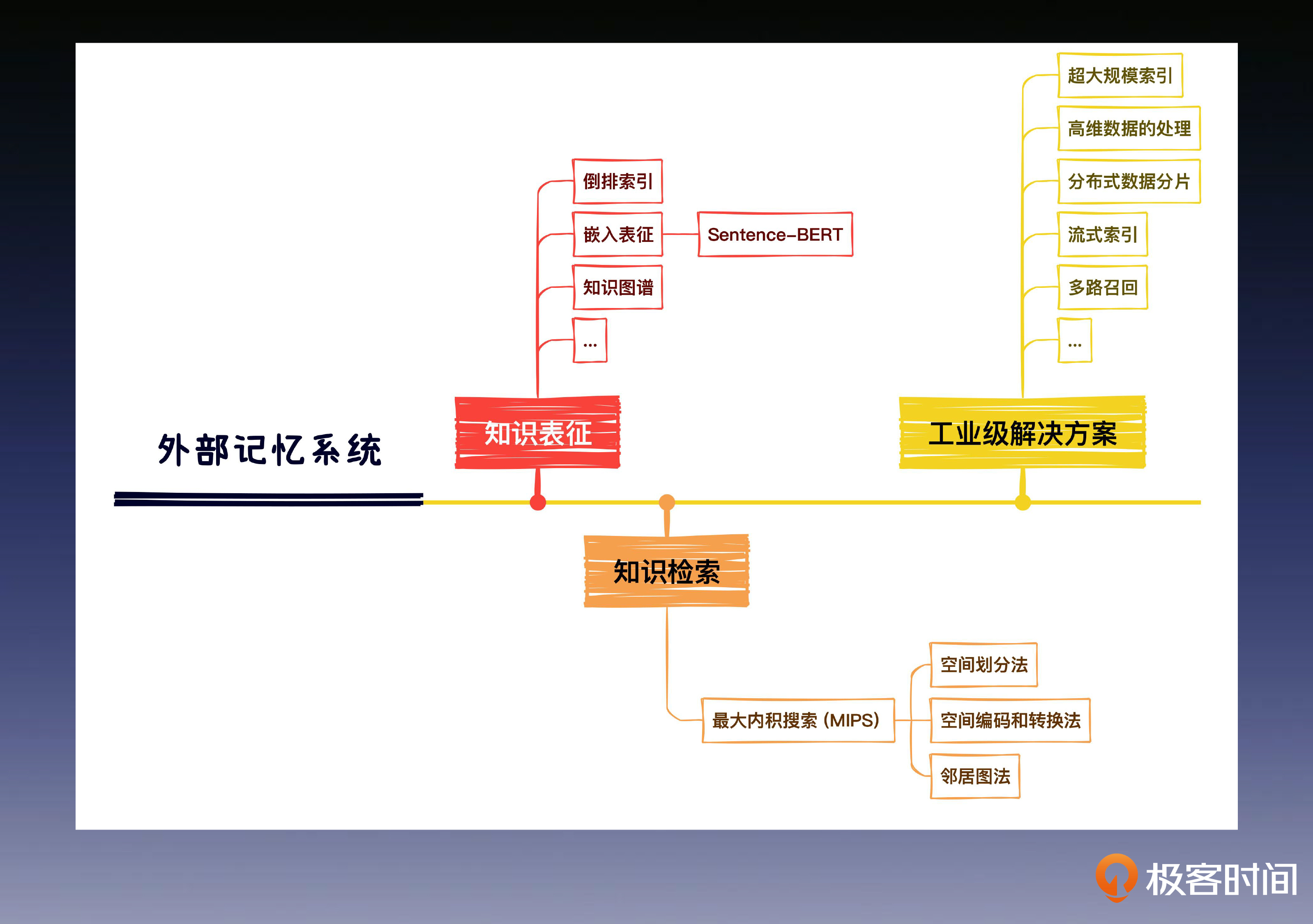
这其中有两个很重要的问题需要解决。第一是如何表示这些知识,也就是知识表征,只有对知识库中的文档进行合适的表达,才能最精准地检索出我们想要的信息。还有第二个重要问题,完成知识表征以后,我们还需要一个高效的检索方法,在海量的外部记忆信息中检索出我们想要的内容。
这两个问题的解决方案,学完今天的内容你就能掌握。但是真实工业环境中的真实情况往往更加复杂,为了让你能够持续学习,不断应对新的挑战,我还会带你领略工业级外部记忆系统的风采,学习一下阿里巴巴开源的 HA3 这个外部记忆引擎如何应用。
知识表征技术
首先,我们来聊聊知识表征,知识表征中常见的方法有很多,这里我列出了一些主流方法,其中很多内容我们之前已经学习过了。在这节课呢,我来带你梳理总结一下你所学过的这几个方法的区别,为了方便你查看,我特意梳理成了表格的形式。

首先是倒排索引,这是知识表征技术中最经典的技术之一,直接通过文档中的字面关键词,作为文档的特征表示。
接下来是嵌入表征,它是利用知识在高维空间的映射,来表示知识的语义信息。
最后是知识图谱,知识图谱则可以将知识的内容进一步结构化,并且通过图神经网络的方式,把知识转化为富含结构语义的高维特征信息。
这里需要你重点掌握的是,我们在外部记忆中所说的嵌入表征方法,和我们前面学过的Work2Vec,BERT 以及各类的图神经网络算法等等没有区别。只不过 BERT 模型在计算两个句子的语义相似度时,需要将它们同时按下面的形式输入到模型。这种方式叫做 Cross-Encoder。
[CLS] sentence 1 [SEP] sentence 2 [SEP]
不过这种两两比对的推理开销,在真实的业务环境中几乎是不能接受的。因此,在外部记忆表征检索中用到的嵌入表征方法通常是指 sentence-bert(SBERT) 这类投影表征方法。SBERT 本质上也是通过我们学过的对比学习方法,用相似句子的表征向量之间的距离更近这个原则,来微调 BERT 模型。
我们可以看到,每种单一的表征方法都会有自己的局限性。所以在真实的应用场景中,为了发挥各类表征能力的优点,补足其他方法的不足,通常会使用多路召回的方式进行表征。
每种不同的表征方法也对应了不同的存储和检索策略,上述方法中倒排索引的存储逻辑我们已经很熟悉了,其中 ElasticSearch 是当仁不让的开源顶流,这里重点介绍一下向量检索引擎。
最大内积搜索 (MIPS)
顾名思义,向量索引是一个可以用于快速检索相似向量的存储引擎,其中最有名的当属早期工业界广泛使用的 Faiss,它早在 2017 年就已开源了。前面的课程我们也学习过,该引擎早已广泛应用在 AIRC 领域,并不是一项新技术。
虽然我们经常听说或者使用向量数据库,但大多数人并不知道其中的原理。不过从系统性学习技术的角度来说,理解原理,能够帮你理解这项技术的落地挑战,接下来我们就为你把它层层剥开,娓娓道来。
向量检索的根本目标是找到与查询向量最相似的 K 个向量(KNN),或者找到距离查询量小于某个距离阈值的所有向量(RNN)。但工业场景中数据量往往很大,如果采用精确最近邻算法,会导致检索效率太低。所以我们通常选择牺牲一定准确性来提高速度,采用近似最近邻算法(ANN)。
不同的检索算法都有自己的优缺点,选择合适的检索算法可以提高检索效率。
常用的检索算法包括后面这三类。
- **空间划分法:**将数据空间划分为多个子空间,然后在子空间内进行检索。常见的空间划分方法有 KD-Tree、聚类检索等。
- **空间编码和转换法:**将高维数据映射到低维空间进行检索。常见的空间编码和转换方法有 p-Stable LSH、PQ 等。
- 邻居图法:构建数据之间的邻居关系,然后在邻居图上进行检索。常见的邻居图法有 HNSW、SPTAG、ONNG 等。
下面我们以最常使用的 Faiss 为例聊一下实现思路。
在 Faiss 中就使用了 PQ 算法,PQ 算法是一种近似最近邻算法,它将高维数据映射到低维空间进行检索。PQ 算法的基本思想是将原始向量空间分解为多个低维向量空间的笛卡尔积,然后对每个低维向量空间进行量化。这样,每个原始向量就可以由多个低维量化编码表示。
向量检索数据库
理解了原理后,你是不是发现向量数据库没什么神秘的了,只不过是通过ANN的方法在检索数据库的一些相似向量而已。基于对这部分知识的理解,我们很容易推测出向量数据库在应用中的挑战有哪些。
**其中一个挑战是超大规模索引的精度和效率问题。**随着数据量的不断增加,在亿级、甚至十亿级时,向量索引的构建和检索成本也会随之增加,这可能会影响向量检索的性能和准确性。
**另一个挑战是高维数据的处理问题。**随着维度的增加,向量检索的计算复杂度也会呈指数级增长,这可能会导致查询效率下降、存储成本升高。
此外,向量检索还面临分布式数据分片构建和快速合并检索、流式索引的在线更新、多路召回等等挑战。
为了应对这些工业环境的真实挑战,就需要用到工业级的外部记忆引擎。我会和你一起探索,如何用阿里巴巴开源的 HA3 ,实现一个工业级知识系统。之所以使用 HA3 来带你学习,是为了让你深入学习其中外部记忆的存储和检索能力,它是阿里巴巴 AI 在线架构 AI·OS 的最重要的组成部分之一,而且现在它已经开源了,我们可以在自己的场景进行使用。
多路召回环境搭建
首先,我们要获取项目代码,通过 docker 启动 HA3 服务。注意,这里大部分人都是使用单机模式,所以和 Hadoop 的单机分布式实验一样,这里需要确保本机的免密 SSH 登录,具体方法你可以参考这篇文章 Why Do We Need Hadoop Passwordless SSH 。
1 | $ git clone https://github.com/alibaba/havenask.git |
之后,我们为实验准备一个单独的 conda 环境。
1 | conda create --name havenask_llm python=3.10 |
然后,我们进入 HA3 项目的 llm 文件夹,从名字可以看出来,阿里已经将自己兼容大语言模型的方法暴露了出来,我们按要求安装 python 依赖包即可。
1 | $ pip install -r requirements.txt |
接下来,我们来配置大语言模型相关的内容,这里我们以 ChatGLM-6B 为例。
1 | LLM_NAME=ChatGLM |
下面我们开始正式构建索引,这里就以 HA3 的技术文档为例,构建它的知识库的索引。
1 | $ git clone https://github.com/alibaba/havenask.wiki.git |
之后,将索引放在 HA3 的指定文件夹下。
1 | $ cp ./llm.data ../hape/example/data/llm.data |
然后,通过脚本将数据写入引擎。我们先进入 hape 文件夹安装相关的依赖,注意这里使用的是 Python2.7 版本。
1 | $ cd ../hape |
接下来回到 llm 文件夹,运行测试脚本,你可以试着让它回答你一些关于 HA3 文档的问题。
1 | $ python api_demo.py |
当然,官方也提供了由 Gradio 搭建的简易网页,方便我们和它对话。

可以看出 HA3 正在拥抱大语言模型,它不但支持 chatglm 的配置,还支持 openAI API 的方式调用,你也可以实现自己的 adapter 来兼容更多的 LLM。
总结
我们来做个总结吧。
这节课我们串联了之前学过的向量表征技术,并且着重学习了 SBERT 和 MIPS 这些在 AIGC 领域出现频率更高的技术。
学到这里,你会意识到 AIRC(AI Recommended Content) 和 AIGC (AI Generated Content)天然的连贯性,以及向量数据库被作为外部知识库这种形式被大众广泛接受的原因。
这节课不是结束,而是一个开始,希望你能够深入探寻工业级 AIGC 记忆存储引擎的乐趣,HA3 的向量检索能力深度融合了达摩院的 Proxima 能力,除此之外它还支持了各类的检索能力,我在课后为你准备了不少习题,希望你能继续探索,认真完成。
下节课开始,我们将进入大模型训练部分的学习,敬请期待!
思考题
在学完这节课之后,你会发现目前所有的外部记忆使用方法都逃不出这个框架,而且大多数标榜自己能力的检索方法也还在使用极为基础的方法。
今天我给你留的思考题比较多,但建议你认真作答,积极参与思考有助于你更好地掌握大模型技术。第一道题目比较简单,后面三道更有挑战性。如果你暂时没有能力实现代码,也可以先聊聊你的思路。
- 结合我们课程里学过的知识,谈一下你对大语言模型外部记忆作用的理解。
- 结合 HA3 为你的知识库增加倒排索引的能力。
- 结合 HA3 为你的知识库增加多路召回的能力。
- 如何通过 HA3 来存储人工智能小镇智能体的记忆流?
恭喜完成我们第 24 次打卡学习,期待你在留言区和我交流互动。如果你觉得有收获,也欢迎你分享给你身边的朋友,邀 TA 一起讨论。