你好,我是黄佳。
上一课中,我们学习了如何基于Code Interpreter做自然语言驱动的数据分析。今天我们来看Assistant中的最后一个,也是超级强大的工具 —— File search(原名Retrieval,也就是文件检索,或者叫RAG)。通过File search,你的Assistant将获得从外部知识库中检索信息的能力,犹如装备了“千里眼”。
根据OpenAI的说法,目前新版本可以检索多至10000个文档,果真如此,则OpenAI Assistants实在是一个强大的智能助理。
什么是 File search(Retrieval) File search或Retrieval就是“检索”,是赋予Assistant查阅外部知识的能力。外部知识可以是你的企业内部文档、产品说明书、客户反馈等各种非结构化数据。有了这些额外的知识补充,Assistant可以更好地理解用户需求,给出更加准确、个性化的回复。
“检索”的实现原理并不复杂。当你上传一份文档后,OpenAI会自动对文档分块、创建索引,并使用向量搜索从中检索与用户查询最相关的内容。这一切都在File search工具内部自动完成,作为开发者的你并不需要关心其中的细节(当然,在后面的课程中,我也会带着你手动实现具体RAG步骤)。现在,你只管把数据“喂”给File search工具就可以啦。
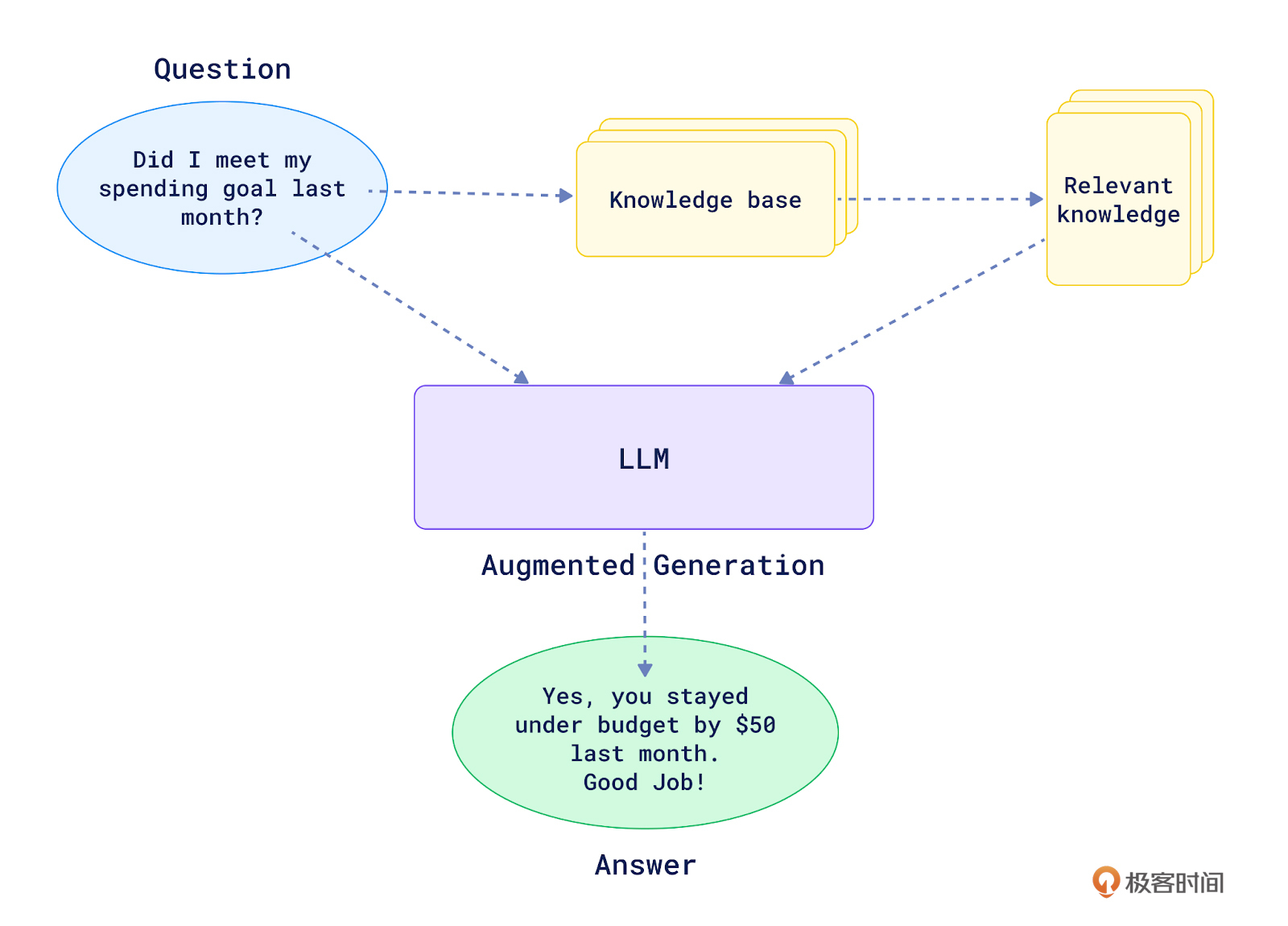
当我们把Retrieval和LLM结合在一起,也就是在信息检索的基础上加上了LLM的内容生成和对话功能,就诞生了RAG(Retrieval-Augmented Generation)。这个过程,正如下面这张图所展示的那样。
在这里:
用户先提出一个问题,如 “Did I meet my spending goal last month?”。 RAG系统从知识库中检索出与问题最相关的片段,比如上个月的支出数据报告。 然后系统将原始问题和检索到的相关知识一起输入到LLM中。 LLM根据问题和相关背景知识,生成最终的回答:“Yes, you stayed under budget by $50 last month. Good Job!” 可以看到,RAG赋予了LLM利用外部知识库进行问答的能力。关键就在于Retrieval首先过滤掉了大量无关信息,只提取最相关的少量片段给LLM。这一方面降低了对LLM记忆容量的要求,另一方面也提高了LLM输出内容的准确性和可解释性。
**Retrieval让LLM真正成为了一个“知识的容器”,而不仅仅是一个“语言的模仿者”。**通过给LLM灌输特定领域知识,我们可以打造出适用于各行各业的垂直助理,如客服、销售、法律、医疗等。这极大拓展了LLM的应用边界,为各行业的智能化升级赋能。
因此,很多人都认为,RAG系统,或者说RAG这个基于大语言模型的设计模式,点燃了最早一批AI大模型应用。实际情况也的确如此,我目前参与的很多项目,多多少少都有RAG的身影。
那么,OpenAI通过Assistants功能,就提供了一个开箱即用的File search工具,这实际上就是一个极简的RAG系统。开发者只需上传自己的知识文件,设置好Assistant的执行逻辑,就可以实现一个基于私有数据的智能问答系统,而无需自己搭建和训练复杂的 RAG模型。
使用 Playground 中的 File search 工具 我们还是先通过Playground中的File search来看看它的使用机理。
第一步,选择Create Assistant新建一个Assistant,并命名为RAG小能手(名字随意)。
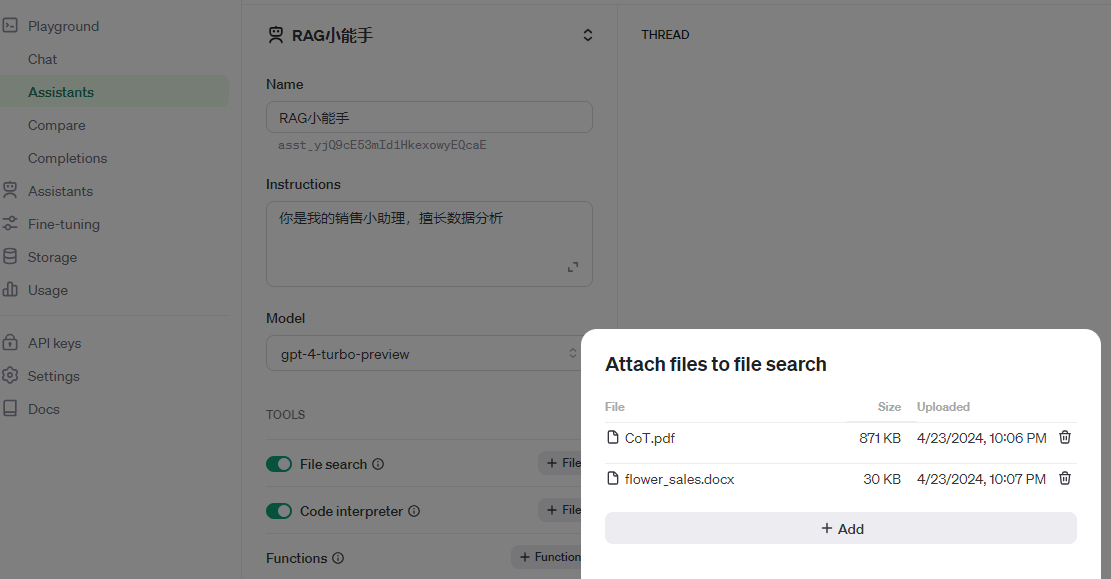
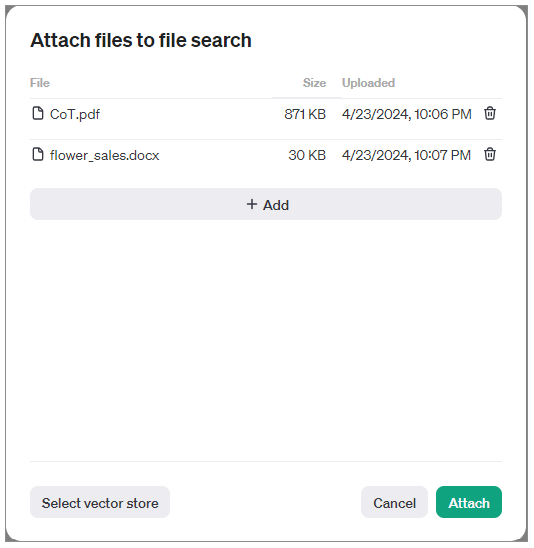
第二步,开启File search功能,并通过Add功能上传数据文件。此处,要注意的是,目前只有较新的模型,如gpt-4-turbo-preview有这个功能。
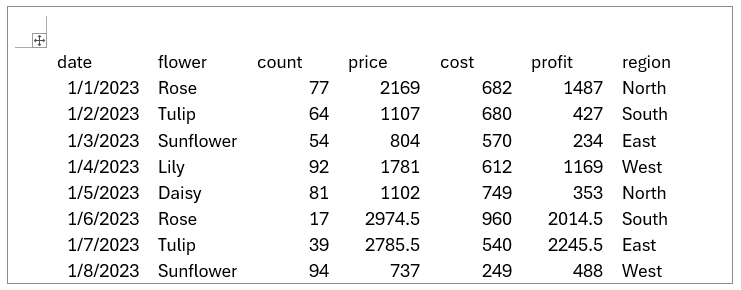
我上传了一篇PDF格式的论文,同时也上传了之前你已经见过的鲜花销售数据表。这里要注意的地方是,csv格式的文件目前还不被File search工具所支持,因此我是把相同的数据放进了word文档中。
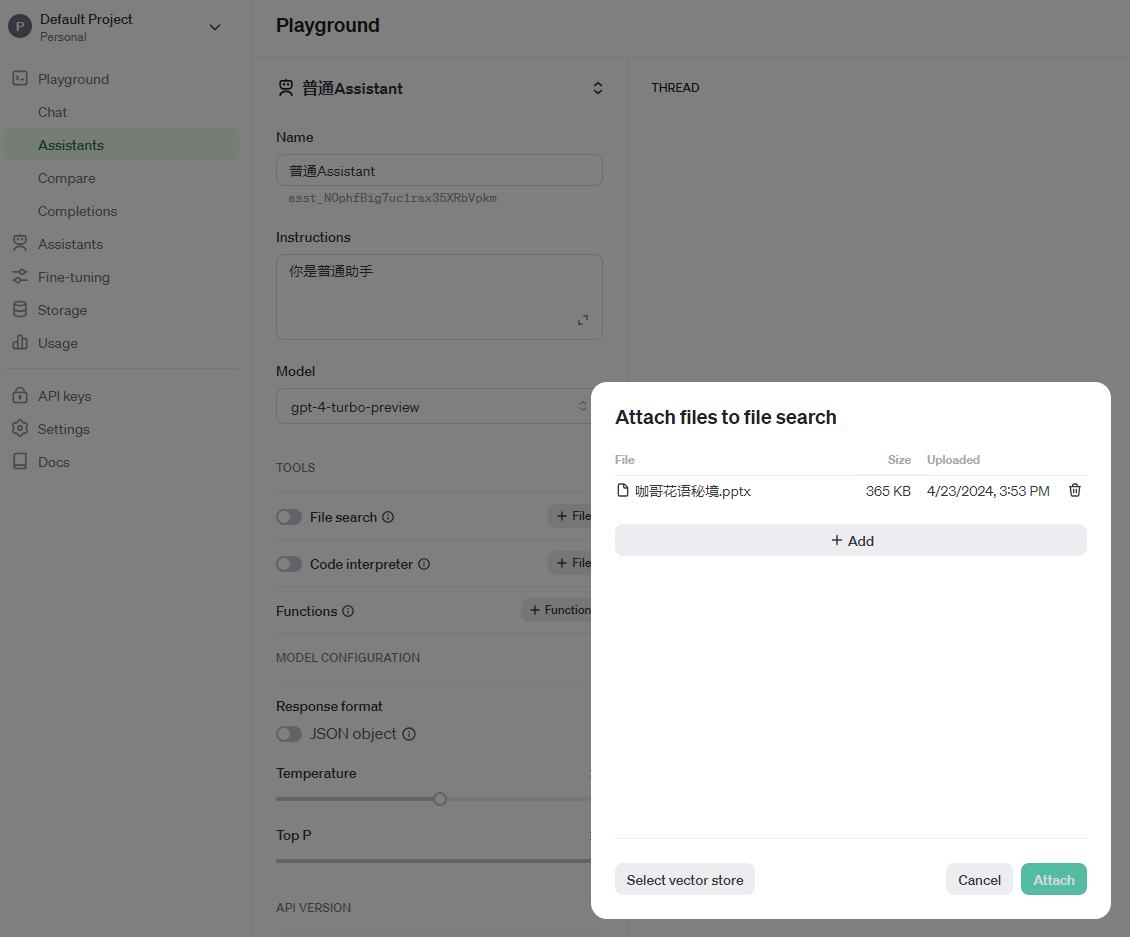
选择Attach之后,文件就被导入到File search工具。
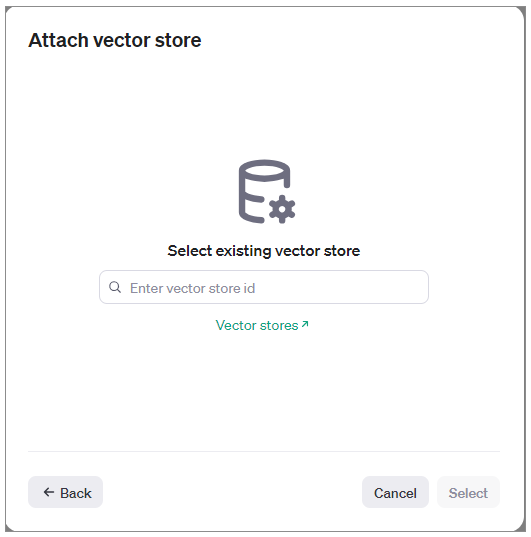
此处,如果选择Select vector store,那么,还有一个附加步骤,就是选择一个向量存储库来管理文件。
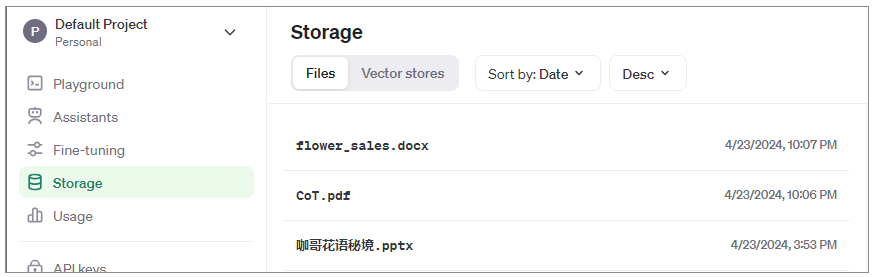
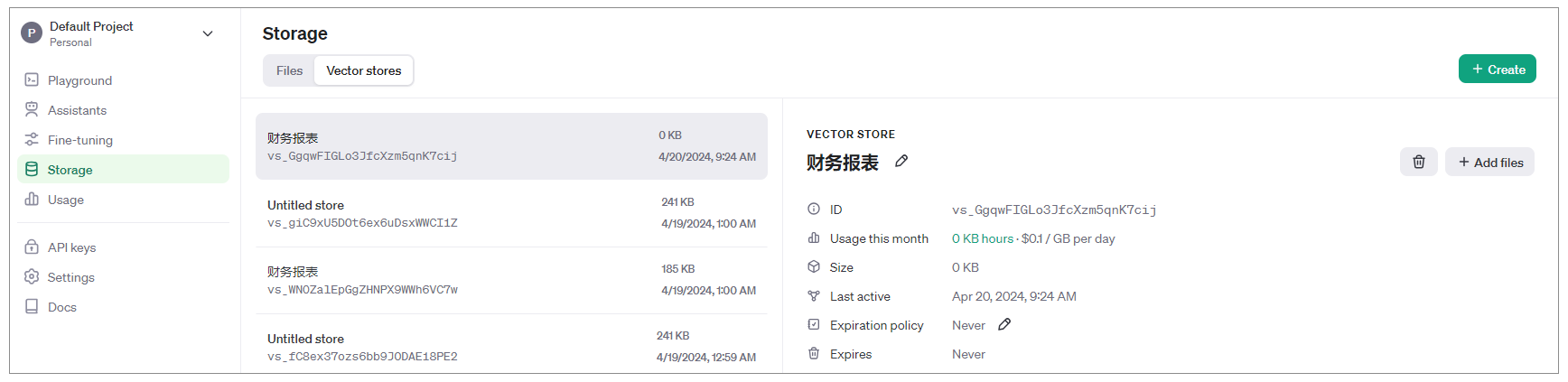
不过,如果我们不选择任何一个向量存储库(也就是Vector Stores)的ID,OpenAI也会把文件存储在Storage的Files中,而且会为这些文件自动创建一个向量存储库,如下图所示。
如果我们希望选择已经存在的向量存储库来管理文件,也可以,只需要在导入文件时选择Select vector store,并指定之前已经创建的向量存储库的ID。
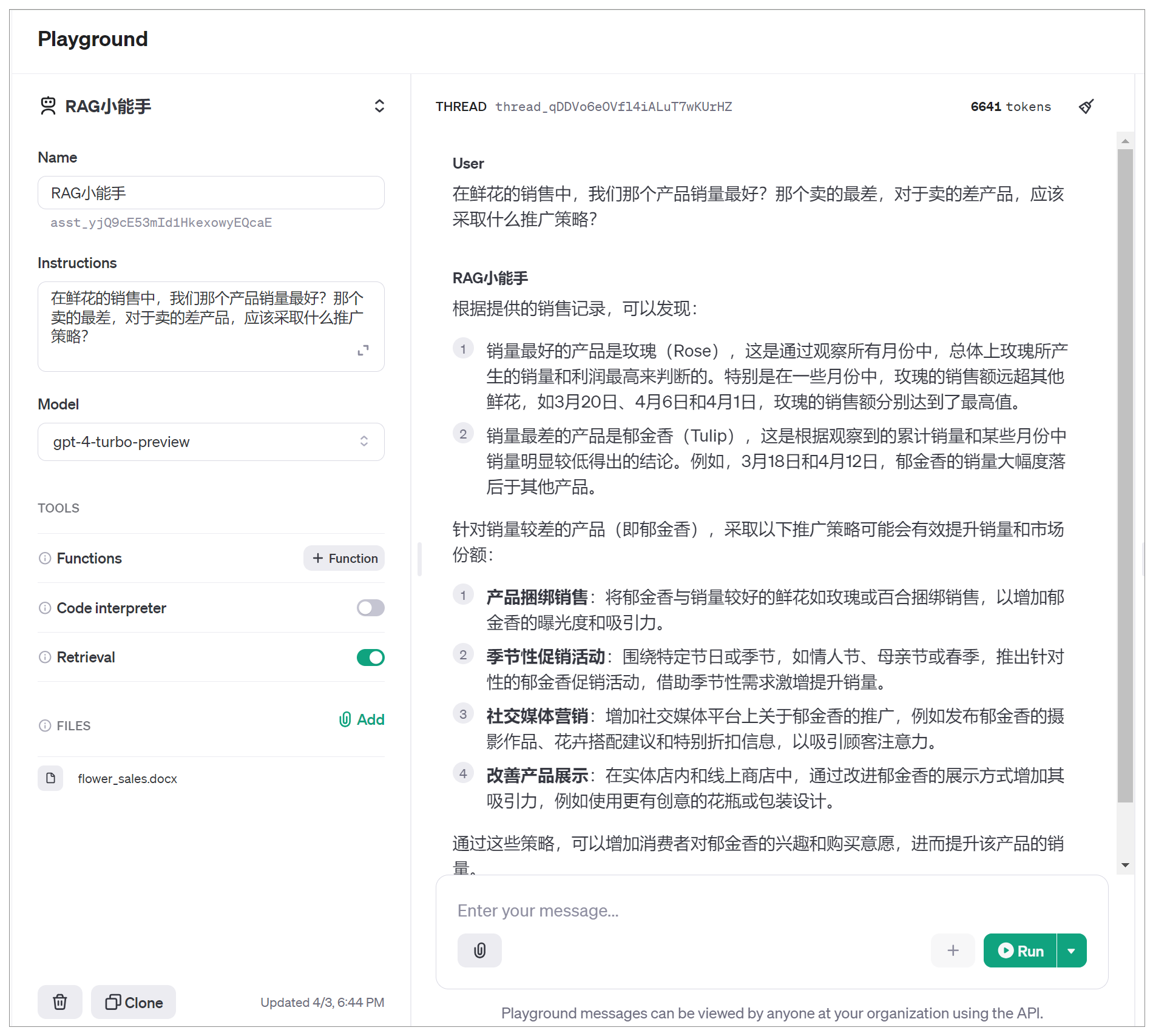
下一步,输入想要问的问题:“在鲜花的销售中,我们哪个产品销量最好?哪个卖得最差,对于卖得差的产品,应该采取什么推广策略?”
然后点击Run按钮,Retrival工具就开始工作了。
那么,假设没有Retrieval这个附加流程,那么,大模型给出的答案有两种可能:要么是直接说信息不足,无法回答问题;而弱一点的模型就可能会产生幻觉,以为自己“知道”,从而胡说一个答案。而有了Retrieval的加持,可以看出GPT-4-Turbo-Preview这个模型给出了精准的回答。
OpenAI 中的向量存储库 在LangChain实战课的 [RAG] 章节中,我曾经介绍过各种商用和开源的向量数据库(向量数据库也就是向量存储库,同一个意思),那么现在,随着OpenAI 的Assistant迭代到第二版,OpenAI也拥有了自己的向量存储解决方案。
向量存储库是一种专门的数据库,允许通过语义和关键字搜索文件内容,支持高级搜索功能,包括语义搜索和关键字搜索。OpenAI中的向量存储库通过解析、分块、嵌入和存储文件到向量数据库,使用工具如助手(Assistant)和线程(Thread)来直接实现高级文件搜索功能。这样,你就不必再去寻找其它商用的向量数据库和GPT模型进行配合啦。就像好用的数据分析工具(Code Interpreter)一样,OpenAI再次成功地为我们提供了一站式的RAG解决方案。
每个向量存储库可以包含多达10,000个文件,每个助手和每个线程最多可以附加一个向量存储库。向量存储库中的文件限制为512 MB和500万个令牌。
可以通过单个API调用添加文件到向量存储库,此操作是异步的。操作包括创建向量存储库、添加单个文件或批量添加文件(每批最多500个文件)。在文件检索之前,要确保文件在向量存储库中已经完全处理好。
OpenAI 的Assistant的文件搜索功能支持多种文件格式,如PDF、Markdown和DOCX,以适应不同的文档类型。File search工具所支持的具体文件类型,可以参考 OpenAI 文档 。
使用 OpenAI Assistant API 中的 File search 工具 使用OpenAI Assistant API中的File search工具的具体流程和使用Code Intepreter的流程非常类似。
我们仍然是导入所需的库,并创建一个OpenAI client。
1 2 3 4 5 6 7 8 9 10 # 导入所需的库 from dotenv import load_dotenv load_dotenv() # 创建Client from openai import OpenAI client = OpenAI() # 设置Logging机制 import logging logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__)
先创建一个Assistant,或者你也可以直接检索刚才在Playground中创建的Assistant。
1 2 3 4 5 6 7 8 9 10 11 12 13 def create_assistant(instructions): try: # 创建一个启用了file_search工具的Assistant assistant = client.beta.assistants.create( name="Sales Data Analyst", instructions=instructions, model="gpt-4-turbo", tools=[{"type": "file_search"}], ) return assistant except Exception as e: logger.error(f"创建Assistant失败: {e}") raise e
然后创建新的Vector Store,用于存储文档。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def create_vector_store(name, file_paths): try: # 创建一个新的Vector Store vector_store = client.beta.vector_stores.create(name=name) # 准备要上传到OpenAI的文件 file_streams = [open(path, "rb") for path in file_paths] # 使用SDK的上传和轮询辅助方法来上传文件,将它们添加到Vector Store中, # 并轮询文件批次的状态直到完成 file_batch = client.beta.vector_stores.file_batches.upload_and_poll( vector_store_id=vector_store.id, files=file_streams ) # 打印批次的状态和文件计数,查看此操作的结果 logger.info(f"文件批次状态: {file_batch.status}") logger.info(f"文件计数: {file_batch.file_counts}") return vector_store, file_batch except Exception as e: logger.error(f"创建Vector Store失败: {e}") raise e
下面,把Vector Store链接至刚刚创建的Assistant,这样我们就可以检索文件的内容。
1 2 3 4 5 6 7 8 9 10 11 def update_assistant_vector_store(assistant_id, vector_store_id): try: # 更新Assistant的tool_resources,使新的Vector Store可用 assistant = client.beta.assistants.update( assistant_id=assistant_id, tool_resources={"file_search": {"vector_store_ids": [vector_store_id]}}, ) return assistant except Exception as e: logger.error(f"更新Assistant的Vector Store失败: {e}") raise e
然后定义创建线程的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def create_thread(user_message, file_id): try: # 创建一个Thread并将文件ID附加到消息中 thread = client.beta.threads.create( messages=[ { "role": "user", "content": user_message, "attachments": [ { "file_id": file_id, "tools": [{"type": "file_search"}] } ], } ] ) logger.info(f"Thread的tool_resources: {thread.tool_resources}") return thread except Exception as e: logger.error(f"创建Thread失败: {e}") raise e
之后,创建运行Assistant的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def run_assistant(thread_id, assistant_id, instructions): try: # 使用create_and_poll SDK辅助方法创建run并轮询状态直到完成 run = client.beta.threads.runs.create_and_poll( thread_id=thread_id, assistant_id=assistant_id, instructions=instructions ) # 获取run生成的消息 messages = list(client.beta.threads.messages.list(thread_id=thread_id, run_id=run.id)) # 提取消息的文本内容 message_content = messages[0].content[0].text annotations = message_content.annotations citations = [] # 处理文件引用,将原文中的引用替换为[index]的形式 for index, annotation in enumerate(annotations): message_content.value = message_content.value.replace(annotation.text, f"[{index}]") if file_citation := getattr(annotation, "file_citation", None): cited_file = client.files.retrieve(file_citation.file_id) citations.append(f"[{index}] {cited_file.filename}") print(message_content.value) print("\n".join(citations)) except Exception as e: logger.error(f"运行Assistant失败: {e}") raise e
此处,run_assistant() 函数接受Thread ID和Assistant ID以及instruction作为参数,在指定的Thread上运行Assistant。在这个函数中,还通过create_and_poll对Run进行轮询,一直到交互结束,用client.beta.threads.messages.list提取消息的文本内容,并输出。
接着,创建轮询Run状态的函数。
1 2 3 4 5 6 7 8 def poll_run_status(client, thread_id, run_id, interval=5): while True: run = client.beta.threads.runs.retrieve(thread_id=thread_id, run_id=run_id) logger.info(f"Run轮询状态: {run.status}") if run.status in ['requires_action', 'completed']: return run time.sleep(interval)
poll_run_status() 函数接受客户端、Thread ID、Run ID和轮询间隔作为参数,持续轮询Run的执行状态,直到Run完成或需要用户操作。它使用client.beta.threads.runs.retrieve()方法获取Run的最新状态,并记录到日志中。如果Run的状态变为requires_action或completed,则返回Run对象,否则按照指定的时间间隔继续轮询。
之后,获取Assistant回复。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def get_assistant_reply(thread_id): try: response = client.beta.threads.messages.list(thread_id=thread_id) for message in response.data: if message.role == 'assistant': reply = message.content[0].text.value logger.info(f"Assistant回复: {reply}") return reply logger.warning("Assistant没有生成有效回复") return None except Exception as e: logger.error(f"获取Assistant回复失败: {e}") raise e
此处,get_assistant_reply() 函数接受Thread ID作为参数,从指定Thread中获取Assistant的回复消息。它使用client.beta.threads.messages.list()方法列出Thread中的所有消息,然后遍历消息列表,找到角色为Assistant的消息,提取其文本内容作为回复。
最后就是主程序入口啦。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def main(): instructions = "你是一位销售数据分析助手。请利用提供的销售数据,尽可能准确完整地回答用户的问题。" # 创建启用了file_search工具的Assistant assistant = create_assistant(instructions) logger.info(f"创建Assistant成功,ID: {assistant.id}") # 创建Vector Store并上传销售数据文件 file_paths = [r"01_Assitants\Retrieval\flower_sales.docx"] vector_store, file_batch = create_vector_store("Sales Data", file_paths) # 将新的Vector Store关联到Assistant assistant = update_assistant_vector_store(assistant.id, vector_store.id) user_message = "请分析一下各种花卉的销售情况,哪个品种卖得最好,哪个卖得最差?对于销量不佳的品种,有什么推广建议吗?" # 获取Vector Store中的文件列表 files = list(client.beta.vector_stores.files.list(vector_store.id)) file_id = files[0].id # 获取第一个文件的ID # 创建Thread并附加文件ID thread = create_thread(user_message, file_id) logger.info(f"创建Thread成功,ID: {thread.id}") # 在Thread上运行Assistant run_instructions = "以花店店长的身份回答问题。" run_assistant(thread.id, assistant.id, run_instructions) if __name__ == "__main__": main()
主程序中,我们创建Assistant、创建并附加向量存储库、创建Thread、运行Assistant,并记录日志。这个程序流程非常清晰。
下面就是Asssitant运行后的输出,也非常令人满意。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 INFO:httpx:HTTP Request: POST https://api.openai.com/v1/assistants "HTTP/1.1 200 OK" INFO:__main__:创建Assistant成功,ID: asst_2sc4224nnJxhOrIPN03KP3N3 INFO:httpx:HTTP Request: POST https://api.openai.com/v1/vector_stores "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: POST https://api.openai.com/v1/files "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: POST https://api.openai.com/v1/vector_stores/vs_lIlA3S1N70YwMK1ZvGVVd6NZ/file_batches "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/vector_stores/vs_lIlA3S1N70YwMK1ZvGVVd6NZ/file_batches/vsfb_ecae4aaea913467cafac56c6b69b6506 "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/vector_stores/vs_lIlA3S1N70YwMK1ZvGVVd6NZ/file_batches/vsfb_ecae4aaea913467cafac56c6b69b6506 "HTTP/1.1 200 OK" INFO:__main__:文件批次状态: completed INFO:__main__:文件计数: FileCounts(cancelled=0, completed=1, failed=0, in_progress=0, total=1) INFO:httpx:HTTP Request: POST https://api.openai.com/v1/assistants/asst_2sc4224nnJxhOrIPN03KP3N3 "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/vector_stores/vs_lIlA3S1N70YwMK1ZvGVVd6NZ/files "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/vector_stores/vs_lIlA3S1N70YwMK1ZvGVVd6NZ/files?after=file-9VVUSDXsNZ2KFJzMYUQEcYJU "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: POST https://api.openai.com/v1/threads "HTTP/1.1 200 OK" INFO:__main__:Thread的tool_resources: ToolResources(code_interpreter=None, file_search=ToolResourcesFileSearch(vector_store_ids=['vs_s6piHqEThJ4BSuvnlrk0Cfou'])) INFO:__main__:创建Thread成功,ID: thread_gNRSn5iB9hIOJIS95TP8iy7n INFO:httpx:HTTP Request: GET https://api.openai.com/v1/threads/thread_gNRSn5iB9hIOJIS95TP8iy7n/runs/run_dGMXDzKquLYB11G8dK6ZBwTA "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/threads/thread_gNRSn5iB9hIOJIS95TP8iy7n/runs/run_dGMXDzKquLYB11G8dK6ZBwTA "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/threads/thread_gNRSn5iB9hIOJIS95TP8iy7n/runs/run_dGMXDzKquLYB11G8dK6ZBwTA "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/threads/thread_gNRSn5iB9hIOJIS95TP8iy7n/messages?run_id=run_dGMXDzKquLYB11G8dK6ZBwTA "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/threads/thread_gNRSn5iB9hIOJIS95TP8iy7n/messages?run_id=run_dGMXDzKquLYB11G8dK6ZBwTA&after=msg_uxxkKXF7PtXxRVMPpjPVUYu5 "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/files/file-9VVUSDXsNZ2KFJzMYUQEcYJU "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/files/file-9VVUSDXsNZ2KFJzMYUQEcYJU "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/files/file-9VVUSDXsNZ2KFJzMYUQEcYJU "HTTP/1.1 200 OK" INFO:httpx:HTTP Request: GET https://api.openai.com/v1/files/file-9VVUSDXsNZ2KFJzMYUQEcYJU "HTTP/1.1 200 OK" 根据提供的数据文件,以下是不同花卉的销售情况分析: 1. **最佳销售品种**: - 玫瑰(Rose)通常的销售情况较好,具体表现在销售数量和利润上[0]。 - 百合(Lily)的销售情况也不错,尤其是在利润方面[1]。 2. **销售表现较差的品种**: - 太阳花(Sunflower)在多次销售中表现不佳,损失相对较高[2]。 - 雏菊(Daisy)也有一些销售记录显示亏损[0]。 3. **对于销量不佳的品种的推广建议**: - **打折促销**:对于销售不佳的花卉如太阳花和雏菊,可以尝试短期打折促销,吸引顾客购买。 - **捆绑销售**:将销售表现不佳的花卉与热门品种如玫瑰或百合一起捆绑销售,提高销售量。 - **增加曝光**:通过社交媒体推广和花店内的显眼摆放,增加这些花卉的曝光率,引起顾客的注意。 - **提供创意玩法**:组织相关的花艺工作坊,教授顾客如何用这些花卉进行创意装饰,提高顾客的购买兴趣。 以上是基于现有数据的分析和建议,希望能帮助你提升花店的整体销售业绩。 [0] flower_sales.docx [1] flower_sales.docx [2] flower_sales.docx [3] flower_sales.docx
这个输出的亮点不仅仅在于包含了详细的API日志,而且还巧妙地通过脚注的方式列出了信息来源,这对于RAG系统的可信度有非常大的帮助。这是个新功能,因为在Assistant v1版本中,我可没有见过!
总结时刻 在本课中,我们深入探讨了Assistant中的File search工具。File search赋予了大语言模型从外部知识库中检索信息的能力,让其从单纯的“语言模型”升级为更加智能和全能的“知识工作者”。通过将文件检索与大语言模型相结合,诞生了RAG这一强大的范式。RAG让大语言模型拥有了更广阔的“知识视野”,能够借助外部信息来回答更加开放和专业的问题,其潜力之大,令人无限遐想。
OpenAI在其Assistant产品中提供了一个极简版的Retrieval工具,让开发者无需搭建和训练复杂的RAG模型,即可实现基于特定领域知识的智能对话功能。这极大降低了RAG技术的使用门槛,为各行各业打造定制化AI助手铺平了道路。
当然,生产环境中的RAG系统的实现,也许有些需求Assistant的File search无法完全满足,或者你不希望每天为OpenAI付费,因此你还是决定自己定制RAG系统。在这里我们只是初窥门径,对RAG有了一个初步的认识。在后续的课程(或新课程)中,我将带你更彻底地拆解RAG的技术架构,手把手教你从0到1构建更复杂的RAG应用,带着你全面掌握RAG的原理和开发流程,通过不同的技巧(如更好的文档分割、更高效的检索)提升检索和回答的准确率。敬请期待!
思考题 以下是几个思考题,可以帮助你更好地理解File search工具和RAG技术。
File search目前支持多种主流文件格式。假如你要为一家律师事务所公司搭建一个基于File search的客服系统,你会把哪些类型的数据纳入知识库?要让Assistant具备哪些核心功能? 如果是搭建律师使用的检索助手系统呢? 现在,你已经学完了启程篇,完全掌握了Assistant这个工具,你觉得,它实现了吴恩达老师提出的Agent模式中的哪几种?为什么? 知识获取是RAG的关键,但并非所有知识都是结构化或半结构化的,还有大量散落在视频、音频、图像等非结构化数据中的知识。如何将多模态信息纳入RAG的知识库,让大语言模型也能看图、听音、看视频,进而回答相关问题?(提示:这是我们后续课程要讲述的内容,你可以先自己研究一下。) 好啦,今天的内容就到这里。RAG为大语言模型带来了知识库这个强大的“外挂”,必将带来智能对话领域的新变革。希望这节课能让你对RAG有更深刻的理解,也期待在后续的讨论中听到你的想法和体会。
如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!