你好,我是郑建勋。
这节课,我们来学习分析Go程序的利器:pprof和trace。
pprof及其使用方法
先来看pprof。pprof用于对指标或特征的分析(Profiling)。借助pprof,我们能够定位程序中的错误(内存泄漏、race 冲突、协程泄漏),也能对程序进行优化(例如 CPU 利用率不足等问题)。
Go 语言运行时的指标并不对外暴露,而是由标准库 net/http/pprof 和 runtime/pprof 来与外界交互。其中, runtime/pprof需要嵌入到代码进行调用,而net/http/pprof 提供了一种通过 HTTP 获取样本特征数据的便利方式。而要对特征文件进行分析,就得依赖谷歌推出的分析工具pprof了。这个工具在 Go 安装时就存在,可以用go tool pprof执行。
要用 pprof 进行特征分析需要执行两个步骤:收集样本和分析样本。
收集样本有两种方式。一种是引用 net/http/pprof,并在程序中开启 HTTP 服务器,net/http/pprof 会在初始化 init 函数时注册路由。
1 | import _ "net/http/pprof" |
通过HTTP收集样本是实践中最常见的方式,但它并不总是合适的,例如对于一个测试程序,或是只跑一次的定时任务就是如此。
另一种方式是直接在需要分析的代码处嵌入分析函数,例如下例中我们调用了 runtime/pprof 的StartCPUProfile 函数,这样,在程序调用完 StopCPUProfile 函数之后,就可以指定特征文件保存的位置了。
1 | func main(){ |
接下来,让我们用第一种方式在项目的main函数中注册pprof。
1 | package main |
pprof库在init函数中默认注册了下面几个路由。
1 | func init() { |
接着,我们需要在Master中开启一个默认的HTTP服务器,用它来接收外界的pprof请求。
其实在之前实现GRPC-gateway时,已经为Master和Worker开启了HTTP的服务器。但是当时开启的HTTP服务器并不是Go中默认的HTTP路由器,所以我们不能为pprof复用该端口。
我们在这里开启一个新的HTTP服务器来处理pprof请求,处理方式如下。
1 | // cmd/master.go |
有了用于处理pprof请求的HTTP服务器之后,我们就可以调用相关的HTTP接口,获取性能相关的信息了。pprof的URL为debug/pprof/xxxx形式,最常用的 3 种 pprof 类型包括了堆内存分析(heap)、协程栈分析(goroutine)和 CPU 占用分析(profile)。
- profile用于获取CPU相关信息,调用如下。
1 | curl -o cpu.out http://localhost:9981/debug/pprof/profile?seconds=30 |
- goroutine用于获取协程堆栈信息,调用如下。
1 | curl -o goroutine.out http://localhost:9981/debug/pprof/goroutine |
- heap用于获取堆内存信息,调用如下。在实践中我们大多使用 heap 来分析内存分配情况。
1 | curl -o heap.out http://localhost:9981/debug/pprof/heap |
- cmdline用于打印程序的启动命令,调用如下。
1 | » curl -o cmdline.out <http://localhost:9981/debug/pprof/cmdline> |
另外,block、threadcreate、mutex 这三种类型在实践中很少使用,一般只用于特定的场景分析。
获取到特征文件后,我们就可以开始具体地分析了。
一般我们使用 go tool pprof 来分析。
1 | » go tool pprof heap.out jackson@bogon |
此外,我们也可以直接采用下面的形式完成特征文件的收集与分析,通过 HTTP 获取到的特征文件将存储在临时目录中。
1 | go tool pprof http://localhost:9981/debug/pprof/heap |
pprof堆内存分析
当我们用pprof分析堆内存的特征文件时,默认的分析类型为inuse_space,代表它是分析程序正在使用的内存,文件的最后一行会出现等待进行交互的命令。
交互命令有许多,我们可以通过 help 指令查看,比较常用的包括top、list、tree等。首先来看看使用最多的top指令,top指令能够显示出分配资源最多的函数。
我们现在启动Worker,在只有一个任务(爬取豆瓣图书的信息)的情况下,利用pprof查看堆内存的占用情况。可以看到,当前收集的内存量为5915.93KB。
1 | » go tool pprof heap.out jackson@bogon |
我们当前收集的内存量为5915.93KB,这些内存来自哪里呢?top可以为我们分析出分配内存最多的函数来自哪里。其中2562.81KB由runtime.allocm函数分配,这是运行时创建线程m的函数。还有768.26kB来自Zap日志库的zapcore.newCounters方法。
top 会列出以 flat 列从大到小排序的序列。不同的场景下flat对应值的含义不同。当类型为heap的inuse_space 模式时,flat对应的值表示当前函数正在使用的内存大小。
cum 列对应的值是一个累积的概念,指当前函数及其调用的一系列函数flat的和。flat本身只包含当前函数的栈帧信息,不包括它的调用函数的栈帧信息,cum字段正好弥补了这一点,flat%和cum%分别表示flat和cum字段占总字段的百分比。
要注意的是,5915.93KB 并不是当前程序的内存大小,它只是样本的大小。在实践过程中,很多人会想当然地犯错。那如果我们想获取当前时刻程序的内存大小要怎么做呢?
在程序中,我们可以使用runtime标准库来获取当前的内存指标,下面是我打印出的程序当前的内存大小。
1 | memStats := new(runtime.MemStats) |
另外我们也可以用pprof做到这一点,在HTTP请求中添加debug=1参数,我们就可以打印出当前的堆栈信息和内存指标了。
1 | curl http://localhost:9981/debug/pprof/heap?debug=1 |
打印结果如下所示。
1 | ... |
我们还可以使用top-cum命令,对cum进行排序,查看哪一个函数分配的内存量最多(包含了其子函数的内存分配)。
以runtime.newm函数为例进行说明,通过runtime.newm的flat指标可知,其自身没有分配内存,但是由于runtime.newm调用了runtime.allocm,而runtime.allocm分配了2.50MB,所以 runtime.allocm 的 cum 量也达到了2.50MB。
1 | (pprof) top -cum |
我们还可以使用tree命令查看当前函数的调用链。例如,runtime.allocm分配了2.5M内存,其中512.56KB是runtime.mcall调用的,另外2050.25KB是由runtime.mstart0调用的。(runtime.mstart0是程序启动时调用的函数)。
1 | (pprof) tree |
更进一步地,我们还可以使用 list runtime.allocm 列出内存分配是在哪里发生的。如下所示,可以看到,runtime.allocm函数位于runtime/proc.go,它的内存分配位于第1743行代码的mp := new(m)。
1 | (pprof) list runtime.allocm |
这样一来,当遇到内存问题时,我们就可以非常精准地知道要查看哪一行代码了。
除却默认的分析类型inuse_space,在heap中,还有另外三种类型分别是:alloc_objects、alloc_space和inuse_objects。其中alloc_objects 与inuse_objects 分别代表“已经被分配的对象”和“正在使用的对象”的数量,alloc_space表示内存分配的数量,alloc_objects与alloc_space都没有考虑对象的释放情况。
要切换展示的类型很简单,只需要输入对应的指令即可。例如,输入alloc_objects 后再次输入top 指令,当前 flat 代表的就不再是分配的内存大小,而是分配内存的次数。可以看到,分配内存次数最多的是 go-micro 中的 json.Get 函数。
1 | (pprof) alloc_objects |
proof 工具还提供了强大的可视化功能,可以生成便于查看的图片或HTML文件。但实现这种功能需要先安装Graphviz(开源的可视化工具)。你可以在官网找到最新的下载方式,安装完成后,在pprof提示符中输入 Web 就可以在浏览器中看到资源分配的可视化结果了。
1 | (pprof) web |

从图中,我们能够直观地看出当前函数的调用链、内存分配数量和比例,找出程序中内存分配的关键部分,越大的方框代表分配内存的次数更多。
我们来详细解读一下这张图片。
- 节点颜色: 红色代表累计值 cum 为正,并且很大; 绿色代表累计值 cum 为负,并且很大; 灰色代表累计值 cum 可以忽略不计。
- 节点字体大小: 较大的字体代表当前值较大; 较小的字体代表当前值较小。
- 边框颜色:当前值较大且为正数时为红色; 当前值较小且为负数时为绿色;当前值接近 0 时为灰色。
- 箭头大小:箭头越粗代表当前的路径消耗的资源越多, 箭头越细代表当前的路径消耗的资源越小。
- 箭头线型:虚线箭头表示两个节点之间的某些节点已被忽略,为间接调用;实线箭头表示两个节点之间为直接调用。
pprof协程栈分析
除了堆内存分析,协程栈分析使用得也比较多。分析协程栈有两个作用,一是查看协程的数量,判断协程是否泄漏;二是查看当前协程在重点执行哪些函数,判断当前协程是否健康。
下面这个例子,我们查看协程信息会发现,当前收集到了36个协程,程序总的协程数为37个。收集到的协程中,33个协程都位于runtime.gopark中,而runtime.gopark意味着协程陷入到了休眠状态。
1 | » go tool pprof <http://localhost:9981/debug/pprof/goroutine> jackson@bogon |
我们再执行tree,会看到大多数协程陷入到了网络堵塞和select中。这是符合预期的,因为我们的程序是网络I/O密集型的,当有大量协程在等待服务器返回时,协程会休眠等待网络数据准备就绪。
1 | (pprof) tree |
pprof mutex堵塞分析
mutex 主要用于查看锁争用产生的休眠时间,它还可以帮助我们排查由于锁争用导致 CPU 利用率不足的问题。但是这两种特征并不常用,下面我们模拟了频繁的锁争用场景。
1 | var mu sync.Mutex |
接着我们分析pprof mutex会发现,当前程序陷入到互斥锁的休眠时间总共为2.46s,这个时长大概率是有问题的,需要再结合实际程序判断锁争用是否导致了CPU 利用率不足。
1 | » go tool pprof <http://localhost:9981/debug/pprof/mutex> |
pprof CPU占用分析
在实践中,我们还会使用 pprof 来分析 CPU 的占用情况。它可以在不破坏原始程序的情况下估计出函数的执行时间,找出程序的瓶颈。
我们可以执行下面的指令进行 CPU 占用分析。其中,seconds 参数可以指定一共要分析的时间。下面的例子代表我们要花费60s收集CPU信息。
1 | curl -o cpu.out <http://localhost:9981/debug/pprof/profile?seconds=60> |
收集到CPU信息后,我们一般会用下面的指令在Web页面里进行分析。
1 | go tool pprof -http=localhost:8000 cpu.out |
Worker的 CPU信息的可视化图像如下所示。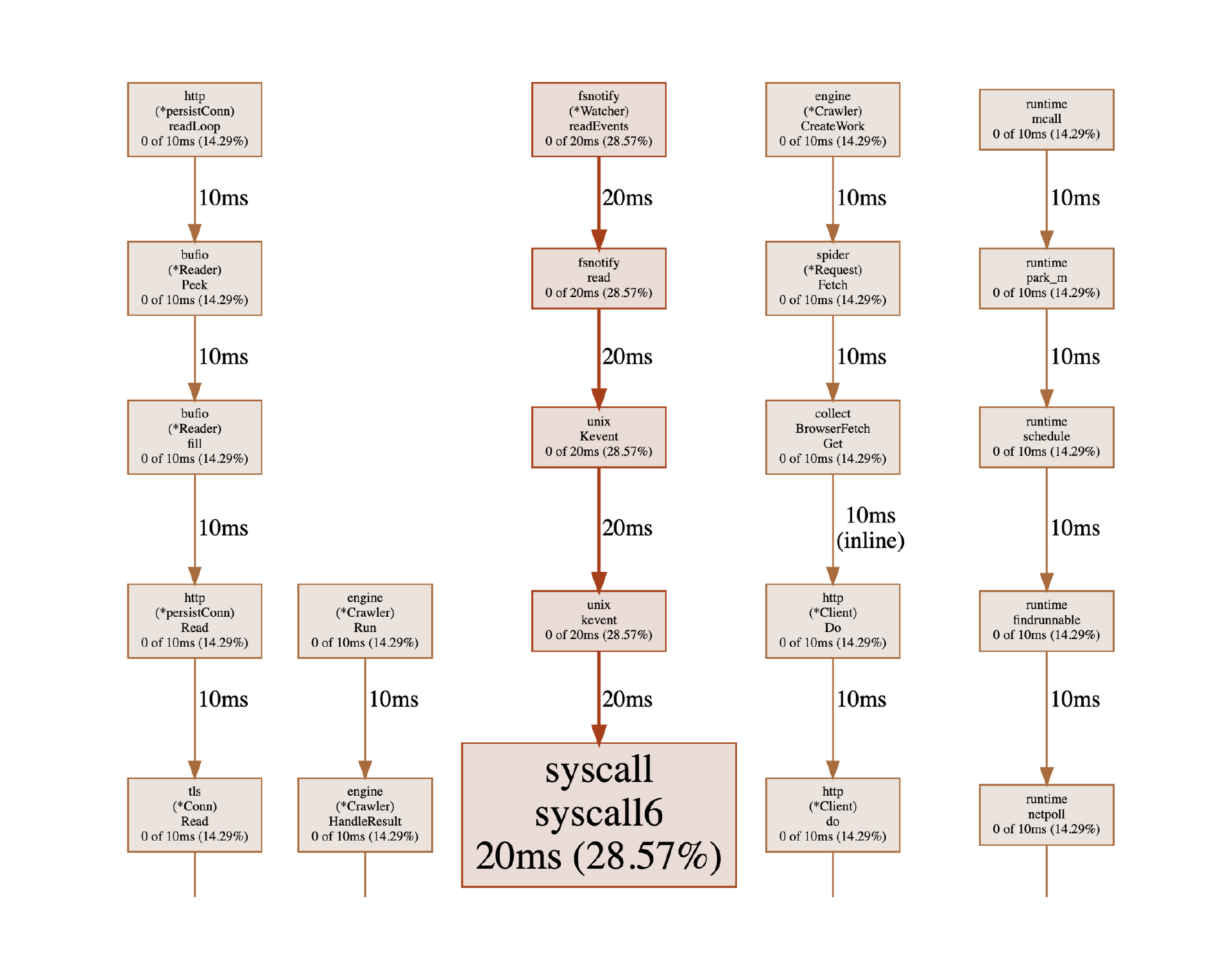
从图片中我们可以看出耗时最多的函数在哪里。例如,从第一列调用链可以看出,在我们探测的周期内,程序有14.29%的时间是在http.readLoop函数中工作,这个函数是http标准库中读取数据的协程。从整体上可以看出,我们的耗时主要是在网络数据处理上。用户协程的数据处理占用的CPU极少。
除此之外,我们还可以将上面的图像切换为火焰图。火焰图是用于分析CPU特征和性能的利器,因为它的形状和颜色像火焰而得名。火焰图可以快速准确地识别出使用最频繁的代码路径,让我们看到程序的瓶颈所在。
Go 1.11 之后,火焰图已经内置到了pprof 分析工具中,用于分析堆内存与CPU的使用情况。Web 页面的最上方为导航栏,可以查看之前提到的许多 pprof 分析指标,点击导航栏中VIEW 菜单下的Flame Graph 选项,可以切换到火焰图。如下所示,颜色最深的函数为HTTP请求的发送与接收。
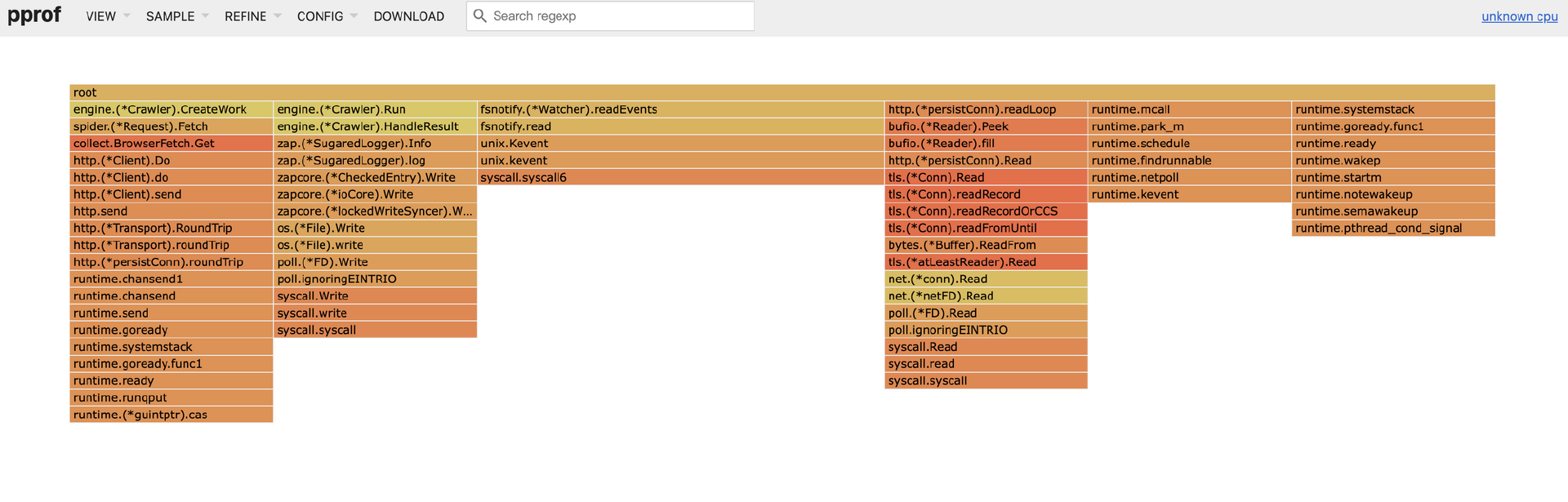
我们以CPU 火焰图为例说明一下。
- 最上方的 root 框代表整个程序的开始,其他的框各代表一个函数。
- 火焰图每一层的函数都是平级的,下层函数是它对应的上层函数的子函数。
- 函数调用栈越长,火焰就越高。
- 框越长、颜色越深,代表当前函数占用 CPU 的时间越久。
- 可以单击任何框,查看该函数更详细的信息。
trace及其使用方法
通过 pprof 的分析,我们能够知道一段时间内的CPU 占用、内存分配、协程堆栈信息。这些信息都是一段时间内数据的汇总,但是它并不能让我们了解整个周期内发生的具体事件,例如指定的 Goroutines 何时执行,执行了多长时间,什么时候陷入了堵塞,什么时候解除了堵塞,GC 是怎么影响单个 Goroutine 的执行的,STW 中断花费的时间是否太长等。而这正是 Go1.5 之后推出的trace 工具的强项,它提供了指定时间内程序中各事件的完整信息,具体如下。
- 协程的创建、开始和结束
- 协程的堵塞,系统调用、通道和锁
- 网络 I / O 相关事件
- 系统调用事件
- 垃圾回收相关事件
收集 trace 文件的方式和收集 pprof 特征文件也非常相似,主要有两种,一种是在程序中调用runtime/trace 包的接口。
1 | import "runtime/trace" |
另一种方式仍然是使用pprof库。net/http/pprof 库中集成了 trace 的接口,下面这个例子,我们获取了 60s 内的trace 事件并存储到了trace.out 文件中。
1 | curl -o trace.out <http://127.0.0.1:9981/debug/pprof/trace?seconds=60> |
要对获取的文件进行分析,需要使用 trace 工具。
1 | go tool trace trace.out |
执行上面的命令会默认打开浏览器,显示出超链接信息。

这几个选项中最复杂、信息最丰富的当数第1 个 View trace 选项。点击它会出现一个交互式的可视化界面,它展示的是整个执行周期内的完整事件。
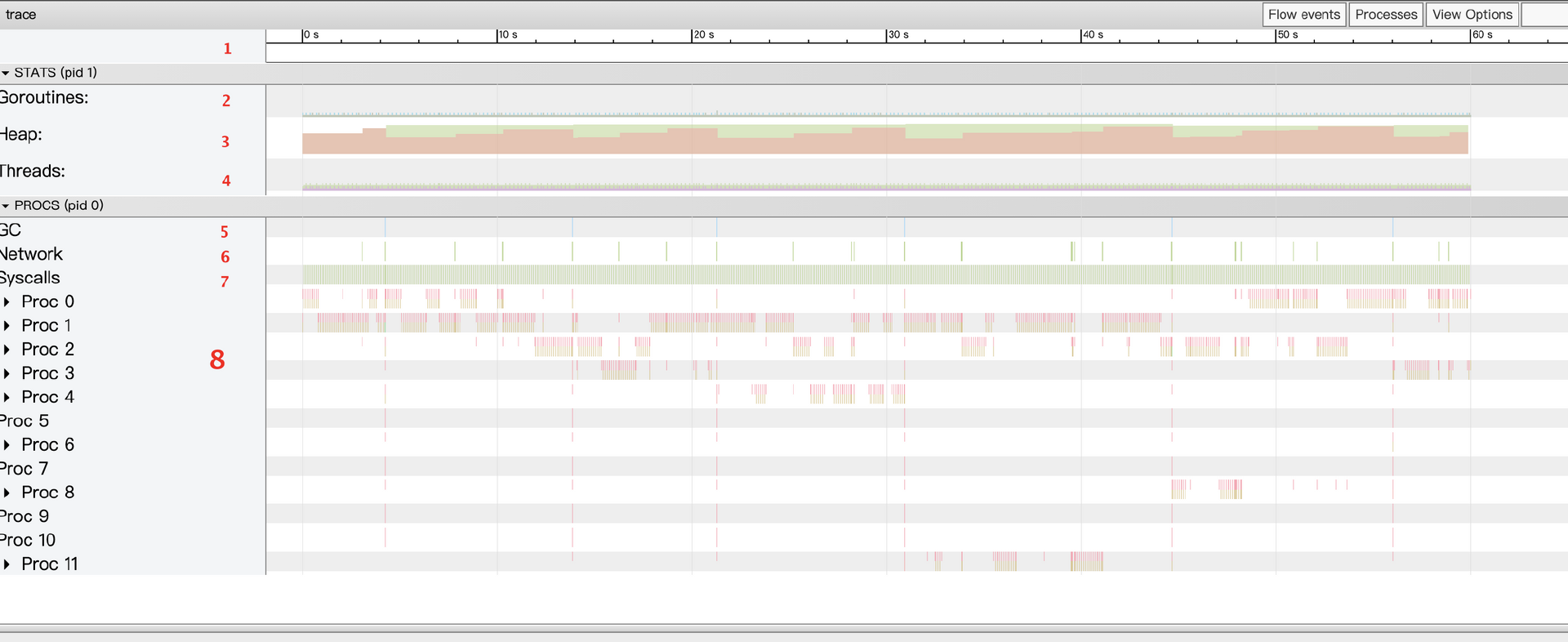
我们来详细说明一下图中的信息。
- 时间线。显示的是执行的时间,时间单位可以放大或缩小,可以使用键盘快捷键(WASD) 浏览时间轴。
- 堆内存。显示的是执行期间内存的分配情况,对于“查找内存泄漏”及“检查每次运行时 GC 释放的内存”非常有用。
- Goroutines。显示每个时间点正在运行的 Goroutine 的数量及可运行(等待调度)的Goroutine 的数量。如果存在大量可运行的 Goroutine,可能意味着调度器繁忙。
- 操作系统线程。显示的是正在使用的操作系统线程数和被系统调用阻止的线程数。
- GC的情况。
- 网络调用情况。
- 系统调用情况。
- 每个逻辑处理器的运行情况。
点击一个特定的协程,可以在下方信息框中看到许多协程的信息,具体包括下面几点。

- Title:协程的名字。
- Start:协程开始的时间。
- Wall Duration:协程持续时间。
- Start Stack Trace:协程开始时的栈追踪。
- End Stack Trace:协程结束时的栈追踪。
- Event:协程产生的事件信息。
对上面的程序进行分析,我们可以得出下面几点结论。
- 程序每隔2秒钟进行一次网络调用,这是符合预期的,因为我们设置了任务的请求间隔。
- 程序中有12个逻辑处理器P,每一个P中间都可以明显看到大量的间隙,这些间隙代表没有执行任何任务。
- 查看Goroutines,会发现在任一时刻,当前存在的协程都并不多,表明当前程序并无太多需要执行的任务,还未达到系统的瓶颈。
- 观察内存的使用情况,可以看到内存的占用很小,只有不到8MB。但内存的增长表现出了锯齿状。进一步观察,我们发现在60s内,执行了6次GC。点击触发GC的位置,会发现触发GC主要来自于ioutl.ReadAll函数。
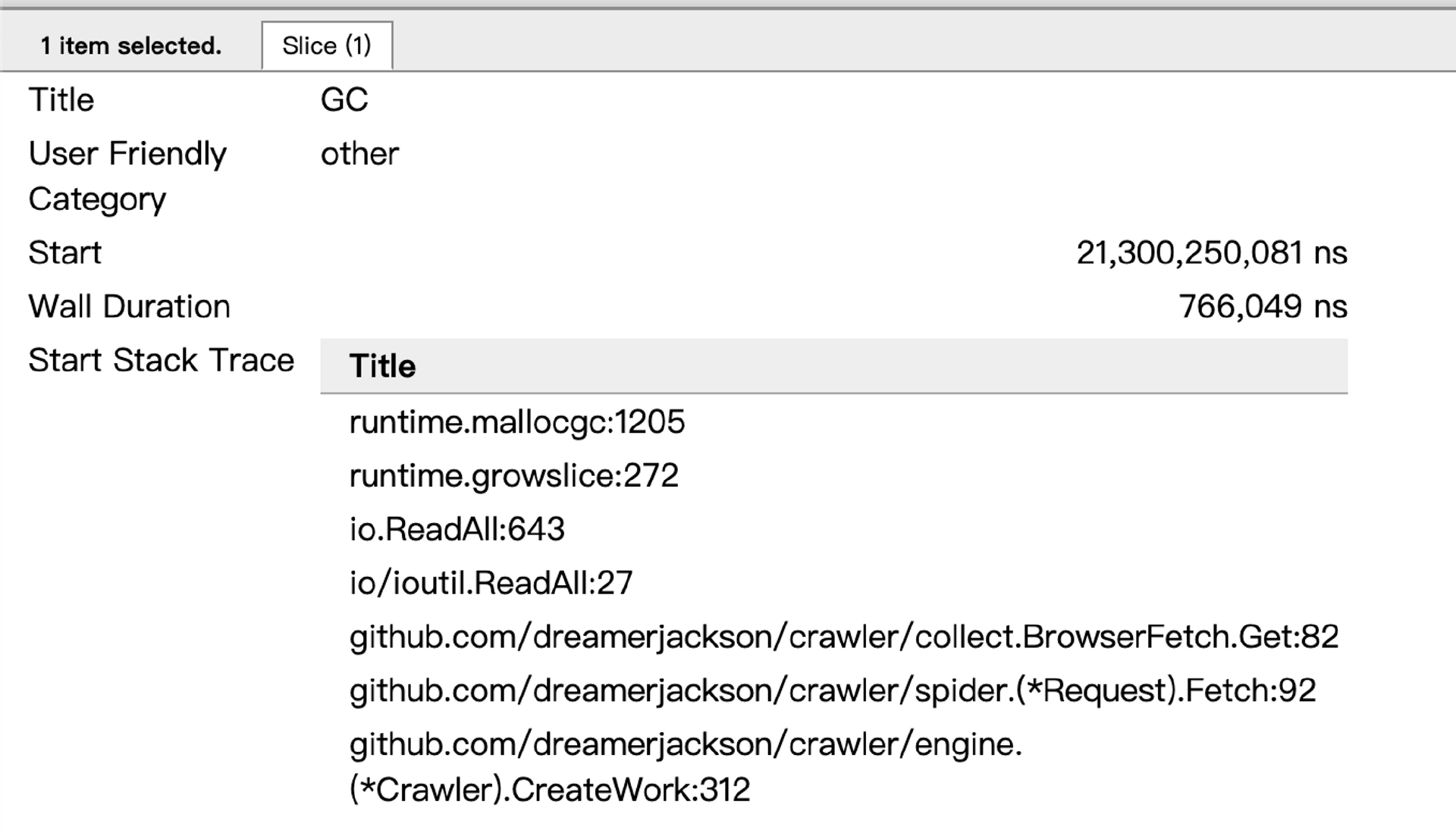
接着查看函数堆栈信息,会发现我们在采集引擎中使用了ioutil.ReadAll读取数据。每一次HTTP请求都会新建一个切片,切片使用完毕后就变为了垃圾内存。因此我们可以考虑在此处复用内存,优化内存的分配,减少程序GC的频率。
1 | func (b BrowserFetch) Get(request *spider.Request) ([]byte, error) { |
trace 工具非常强大,它提供了追踪到的运行时的完整事件和宏观视野。不过 trace 仍然不是万能的,如果想查看协程内部函数占用 CPU 的时间、内存分配等详细信息,还是需要结合 pprof 来实现。
pprof底层原理
这节课的最后,我们再来了解一下pprof的底层原理。pprof 分为采样和分析两个阶段。
采样指一段时间内某种类型的样本数据,pprof 并不会像 trace 一样记录每个事件,因此相对于trace ,pprof收集到的文件要小得多。
以堆内存为例,对堆内存进行采样时,最好的时机就是分配内存的时候。Go分配内存的函数为mallocgc。但是并不是每次调用 mallocgc 分配堆内存信息都会被记录下来,这里有一个指标:MemProfileRate。当多次内存分配的大小累积到该指标以上时,样本才会被pprof记录一次。
1 | if rate := MemProfileRate; rate > 0 { |
记录下来的每个样本都是一个bucket。该 bucket 会存储到全局 mbuckets 链表中,mbuckets 链表中的对象不会被 GC 扫描,因为它加入到了 span 中的special 序列。bucket 中保留的重要数据除了当前分配的内存大小,还包括具体触发了内存分配的函数以及该函数的调用链,这可以借助栈追踪来实现。
堆内存样本收集考虑到了垃圾回收的情况,最大程度地希望当前内存的分配信息表征是当前程序中活着的内存。但是内存分配是实时发生的,垃圾内存的清扫却是懒清扫,这导致了从当前时刻来看内存会存在一些没来得及回收的内存。为了解决这一问题,Go语言做了特殊的处理,如果你想深挖下去,可以查看runtime/mprof.go中的注释。
pprof分析 CPU 占用的能力更令人惊讶。它可以得到在某段时间内每个函数执行的时间,而不必修改原始程序。这是如何实现的呢?
其实,和调度器的抢占类似,这需要借助程序中断的功能为分析和调试提供时机。在类 Unix 操作系统中,这需要调用操作系统库的函数 setitimer 实现。 setitimer 将按照设定好的频率中断当前程序,然后进入操作系统内核处理中断事件,这个过程显然进行了线程的上下文切换。操作系统会从内核态返回用户态,进入之前注册好的信号处理函数,从而为分析提供时机。

当调用 pprof 获取 CPU 样本接口时,程序会将 setitimer 函数的中断频率设置为100Hz,即每秒中断 100 次。这是深思熟虑的选择,因为中断也会花费时间成本,所以中断的频率不可过高。同时,中断的频率也不可过低,否则我们就无法准确地计算出函数花费的时间了。
调用 setitimer 函数时,中断的信号为ITIMER_PROF。当内核态返回到用户态之后,会调用注册好的sighandler 函数,sighandler 函数识别到信号为_SIGPROF 时,执行 sigprof 函数记录CPU样本。
1 | func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) { |
sigprof 的核心功能是记录当前的栈追踪,同时添加CPU的样本数据。CPU 样本会写入叫作data 的 buf 中,每份样本数据都包含该样本的长度、时间戳、hdrsize和栈追踪指针。
pprof 的所有样本数据最后都会经过序列化被转为Protocol Buffers格式并通过 gzip 压缩后写入文件。用户获取该文件后,可以使用 go tool pprof 对样本文件进行解析。go tool pprof 可以将文件解码并还原为Protocol Buffers 格式。
trace底层原理
但是,即便我们使用 net/http/pprof来获取trace信息,底层仍然会调用 runtime/trace库。在 trace 的初始阶段首先需要STW,然后获取协程的快照、状态、栈帧信息,接着设置trace.enable=true 开启GC,最后重新启动所有协程。
trace 提供了强大的内省功能,但这种功能不是没有代价的。Go 语言在运行时源码中每个重要的事件处都加入了判断trace.enabled 是否开启的条件,并编译到了程序中。trace 开启后,会触发 traceEvent 写入事件。
1 | if trace.enabled { |
这些关键的事件包括协程的生命周期、协程堵塞、网络 I/O、系统调用、垃圾回收等。根据事件的不同,运行时可以保存和此事件相关的参数和栈追踪数据。每个逻辑处理器 P 都有一个缓存(p.tracebuf),用于存储已经被序列化为字节的事件(Event)。
事件的版本、时间戳、栈ID、协程ID等整数信息使用LEB128 编码,用于有效压缩数字的长度。字符串使用UFT-8 编码。每个逻辑处理器P的缓存都是有限度的。当超过了缓存限度后,逻辑处理器P 中的 tracebuf 会转移到全局链表中。同时,trace 工具会新开一个协程专门读取全局trace 上的信息,此时全局的事件对象已经是序列化之后的字节数组了,直接添加到文件中即可。
当指定的时间到期后,我们需要结束 trace 任务,程序会再次陷入 STW 状态,刷新逻辑处理器P 上的tracebuf 缓存,设置trace.enabled = false,完成整个 trace 收集周期。
完成收集工作并将数据存储到文件后,go tool trace 会解析 trace 文件并开启HTTP服务供浏览器访问,在 Go 源码中可以看到具体的解析过程。trace 的 Web 界面来自trace-viewer 项目,trace-viewer可以从多种事件格式中生成可视化效果。
总结
这节课,我结合我们的爬虫项目介绍了调试Go语言程序的强大工具pprof和trace。除却使用方法,我们还介绍了它们的底层原理,这有助于我们更深入地理解pprof和trace的能力与局限。
pprof 提供了内存大小、CPU 使用时间、协程堆栈信息、堵塞时间等多种维度的样本统计信息。通过查看占用资源的代码路径,我们可以方便地检查出程序遇到的内存泄露、死锁、CPU 利用率过高等问题。在实践中,我们可以放心地将 pprof 以HTTP的形式暴露出来,在不调用HTTP接口的情况下,这种做法对程序的性能几乎没有影响。
而 trace 是以事件为基础的信息追踪工具,它可以反映出一段时间内程序的变化,例如频繁的 GC 和协程调度情况等,方便我们追踪程序的运行状态,分析程序遇到的瓶颈问题。
思考题
学完这节课,给你留一道思考题。
如果我们利用 pprof 分析内存和CPU,找到了内存分配最多和CPU耗时最长的函数,那它们就一定是最大的瓶颈吗?为什么?
欢迎你在留言区与我交流讨论,我们下节课再见。