你好,我是黄佳。
在前两节课中,我们探讨了如何利用ChatGPT等大语言模型,通过精心设计的多步骤提示流程,自动生成Python单元测试代码以及SQL查询语句。这些示例生动地展示了提示工程的威力,以及语言模型在软件开发领域的广阔应用前景。
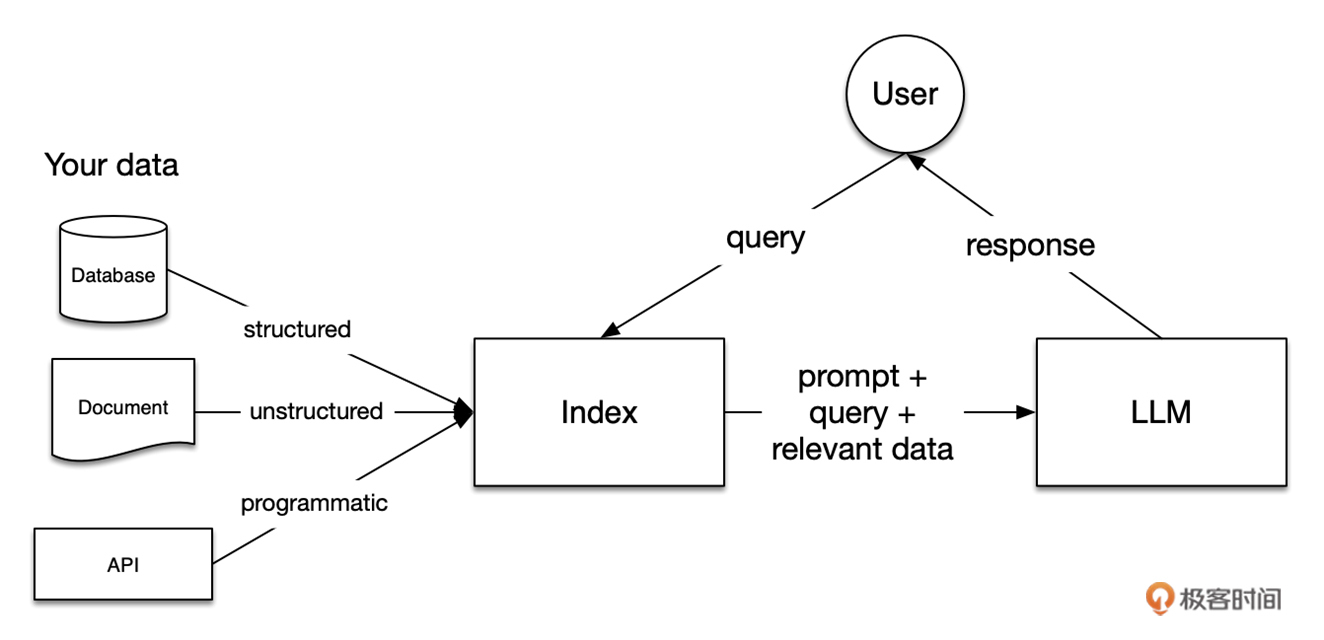
现在,我们将目光转向另一个更具挑战性的任务:构建一个能够读出PDF文档中的“图”的高级RAG(Retrieval-Augmented Generation)系统。RAG是一种将知识检索与语言生成相结合的系统,它先从外部知识库中检索出相关信息,然后将这些信息作为额外的输入,辅助模型生成更加准确和与问题相关的输出。因为 RAG 可以不断更新其所检索的数据源,适应新的信息和趋势,从而保持其回答的相关性和准确性。
RAG这个概念今年非常火爆,被很多人誉为是大模型技术落地第一站,而结合我平时的项目情况来看,事实也的确如此。这种技术之所以备受关注并被视为大模型落地的重要方向,主要有这样几个原因。
知识增强:RAG系统通过在生成过程中融入从外部知识库检索到的相关信息,使得模型能够利用更广泛、更准确的知识来完成任务。这大大提升了模型应对知识密集型任务的能力,如问答、对话、文档生成等。 可解释性:传统的端到端生成模型通常被视为一个黑盒子,难以解释其输出结果的依据。而RAG系统可以明确指出输出结果所引用的外部知识来源,增强了模型的可解释性和可信度,这对于许多需要结果可追溯、可验证的应用场景非常重要。 可扩展性:RAG系统的知识库是独立于模型训练的,这意味着我们可以灵活地扩充和更新知识,而无需重新训练模型。这种解耦设计使得RAG系统可以较容易地适应不同领域、不同规模的应用需求。 数据效率:与从零开始训练大模型相比,RAG系统可以更有效地利用外部知识,在较小的数据规模下取得不错的效果。这在实际应用中意味着更低的数据收集和标注成本。 技术成熟度:RAG系统所涉及的信息检索、语义匹配、语言生成等技术在近年来都取得了长足进展。一些开源的RAG实现方案,如LangChain、LlamaIndex,以及OpenAI的Assistants中提供的功能,都已经使得构建RAG系统的门槛大大降低,推动了其在业界的应用落地。 然而,传统的RAG系统主要处理文本格式的知识([我们的LangChain实战课就有这样的示例]),如果我们要处理PDF文档,特别是包含图片和图表的PDF(如下图,在这次实战中,我们就来读取我的这个直播分享 PPT ,看看效果),就需要引入更多的技术,如文档解析、图像理解等。这无疑增加了任务的复杂性。
下面我将带你一步步构建这样一个基于PDF的RAG系统。我们会使用一些开源库如pdfminer和pdf2image来解析PDF文档和处理图像,通过设计合理的系统架构和提示,我们最终将得到一个能够“读懂”PDF文档并基于其知识生成回答的智能问答系统。
程序总体设计 我们这个解读PDF文档的RAG系统的基本思路是,PDF里面含有多张PPT图片,因此我们会生成多个文本和图片的组合,一张图、一张文的配合起来。
具体来说,程序会执行以下步骤:
将PDF文件转换为一系列图像(即PPT图片)。 从PDF文件中提取文本内容。 遍历每一张PPT图片(除了第一张,因为它通常是简介),使用GPT-4V(具有读图能力的新版GPT,gpt-4-vision-preview)模型分析图片内容,并将分析结果存储在图片内容列表中。 将提取的文本内容按照 \f 分隔符分割成多个文本页面(去除第一页)。 遍历每一个文本页面,尝试找到与之匹配的图片描述(通过比较标题),并将文本内容和匹配的图片描述组合在一起,形成一个完整的内容片段,存储在新列表中。 对于未被匹配到的图片描述,将它们单独添加到新列表中。 对组合后的内容进行清理,去除多余的空格、换行符和页码等。 这样,如果PDF文件中包含多张PPT图片,程序会生成多个文本和图片的组合,每个组合对应一个完整的内容片段。这些内容片段将用于后续的相似度计算和查询匹配。
通过这种方式,程序能够充分利用PDF文件中的文本和图像信息,生成更全面、更准确的内容表示,从而提高RAG系统的查询匹配的质量。
程序实现细节 第 1 步,读取 PDF 图像中的文字 在这个步骤中,我们首先导入所需要的库,创建Client,然后读入单个PDF文件,然后提取PDF文件的文本内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 导入所需的库 from io import BytesIO import base64 from rich import print import pandas as pd import numpy as np # 初始化OpenAI客户端 from openai import OpenAI client = OpenAI() # 指定要读取的单个PDF文件路径 file_path = "data/pdf/GPT图解.pdf" # 提取文本内容 from pdfminer.high_level import extract_text def extract_text_from_doc(path): """从PDF文件中提取文本内容""" text = extract_text(path) return text text = extract_text_from_doc(file_path)
此处我定义了一个函数extract_text_from_doc,使用了pdfminer库的extract_text函数从PDF文件中提取文本。
输出如下(为节省篇幅,省略部分内容):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 大模型是怎样构建的 黄佳 新加坡科技局 AI研究员 ... ... 前埃森哲新加坡公司资深顾问 在一个遥远的未来世界,科技的力量无处不在。在这个世界里,聪明的人工智能助 手们为人类带来了无尽的便利。这个世界里,有两位闻名遐迩的人工智能研究员: 咖哥和小冰。 ... ... Thresholded Logic Unit Perceptron Adaline 神经 网络 寒冬 XOR Peoblem ... ... Transformer ChatGPT ... ... 信息/语言 你俩定 点啥菜? 别问我 特色菜谱 宫保鸡丁 芹菜炒肉 小鸡炖蘑菇 酸菜炖粉条 锅包肉 ... ... 吃了吗,亲? 对话 NLP 01000 01110 11100 NLP的目标是缩小人类语言和计算机代码之间的差距,使机器能够更自 然、更有效地与人类交流,提高信息处理的效率和智能化程度。 ... ... 深度学习 大数据驱动
可以看到,PDF工具成功地读出了PDF中的文本。
第 2 步,读取 PDF 中的图像 先定义一个函数convert_doc_to_images,用于将PDF文件转换为图像。这里,我们使用了pdf2image库的convert_from_path函数将PDF文件转换为图像。
使用pip命令安装。
需要注意的是,pdf2image库依赖于 Poppler 工具集 来进行PDF到图像的转换。需要下载适用于你的操作系统的Poppler版本,并将其解压缩到指定路径。在代码中,需要在poppler_path变量指定Poppler的安装路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 将PDF转换为图像 from pdf2image import convert_from_path def convert_doc_to_images(path): """将PDF文件转换为图像""" poppler_path = 'D:/venv/poppler/poppler-24.02.0/Library/bin' images = convert_from_path(path, poppler_path=poppler_path) return images imgs = convert_doc_to_images(file_path) # 将图像转换为base64编码的数据URI格式 def get_img_uri(img): """将图像转换为base64编码的数据URI格式""" buffer = BytesIO() img.save(buffer, format="jpeg") base64_image = base64.b64encode(buffer.getvalue()).decode("utf-8") data_uri = f"data:image/jpeg;base64,{base64_image}" return data_uri
这里定义了一个函数get_img_uri,用于将图像转换为base64编码的数据URI格式,以便传入GPT-V模型。
第 3 步,用 GPT-4V 分析图像内容 下面,我将定义用于指导GPT-4V模型来分析图像内容的系统提示。这个提示详细说明了如何描述图像中的图表、表格和文字内容,以及如何处理标题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 # 定义系统提示,用于指导GPT-4V分析图像内容 system_prompt = ''' 你将收到一张PDF页面或幻灯片的图像。你的目标是以技术术语讨论你所看到的内容,就像你在做演示一样。 如果有图表,请描述图表并解释其含义。 例如:如果有一个描述流程的图表,请说类似"流程从X开始,然后我们有Y和Z..." 如果有表格,请合理描述表格中的内容。 例如:如果有一个列出项目和价格的表格,请说类似"价格如下:A为X,B为Y..." 不要包括引用内容格式的术语 不要提及内容类型 - 专注于内容本身 例如:如果图像上有图表/图表和文字,请同时讨论两者,而不要提及一个是图表,另一个是文字。 只需描述你在图表中看到的内容以及你从文字中理解到的内容。 你应该保持简洁,但请记住,你的听众看不到图像,所以要详尽地描述内容。 排除与内容无关的元素: 不要提及页码或元素在图像上的位置。 ------ 如果有可识别的标题,请识别标题以按以下格式给出输出: {标题} {内容描述} 如果没有明确的标题,只需返回内容描述。 '''
函数analyze_image则将使用上面定义的提示,来调用GPT-4V(即gpt-4-vision-preview)模型进行图像分析。它将系统提示和图像URL作为消息发送给API,并返回模型生成的内容描述。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # 使用GPT-4V分析图像 def analyze_image(img_url): """使用GPT-4V分析图像""" response = client.chat.completions.create( model="gpt-4-vision-preview", temperature=0, messages=[ { "role": "system", "content": system_prompt }, { "role": "user", "content": [ { "type": "image_url", "image_url": img_url, }, ], } ], max_tokens=300, top_p=0.1 ) return response.choices[0].message.content # 分析PDF文档中的图像 def analyze_doc_image(img): """分析PDF文档中的图像""" img_uri = get_img_uri(img) data = analyze_image(img_uri) return data pages_description = [] # 移除第一张幻灯片,通常只是简介 for img in imgs[1:]: res = analyze_doc_image(img) pages_description.append(res)
上面的代码,用gpt-4-vision-preview模型一张张读取了图片格式的PDF,并将图片内容存储在pages_description中。
为了节省篇幅,我们没有给出图片内容的分析结果,但是以第2张PDF为例,大概应该是“这张图片中左边有一位帅哥男士的半身照,右边则是一些文字……可能是他的介绍或者简历”。你可以打印出pages_description看一看。
第 4 步,组合文本和图像分析结果 在这一步中,我们将组合文本和图像分析结果,同时整理组合后的内容,并将整理后的内容转换为DataFrame。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 # 组合文本和图像分析结果 combined_content = [] # 去除第一张幻灯片 text_pages = text.split('\f')[1:] description_indexes = [] for i in range(len(text_pages)): slide_content = text_pages[i] + '\n' # 尝试找到匹配的幻灯片描述 slide_title = text_pages[i].split('\n')[0] for j in range(len(pages_description)): description_title = pages_description[j].split('\n')[0] if slide_title.lower() == description_title.lower(): slide_content += pages_description[j].replace(description_title, '') # 记录已添加的描述的索引 description_indexes.append(j) # 将幻灯片内容和匹配的幻灯片描述添加到组合内容中 combined_content.append(slide_content) # 添加未使用的幻灯片描述 for j in range(len(pages_description)): if j not in description_indexes: combined_content.append(pages_description[j]) # 清理组合内容 import re clean_content = [] for c in combined_content: text = c.replace(' \n', '').replace('\n\n', '\n').replace('\n\n\n', '\n').strip() text = re.sub(r"(?<=\n)\d{1,2}", "", text) text = re.sub(r"\b(?:the|this)\s*slide\s*\w+\b", "", text, flags=re.IGNORECASE) clean_content.append(text) # 将清理后的内容转换为DataFrame df = pd.DataFrame(clean_content, columns=['content'])
代码中,我们遍历每个文档,将文本内容和图像描述按页分块。它尝试将每个幻灯片的文本内容与对应的图像描述匹配起来。然后对内容进行清理,移除多余的换行和幻灯片编号等。此处,你也可以打印出df的内容,查看一下。
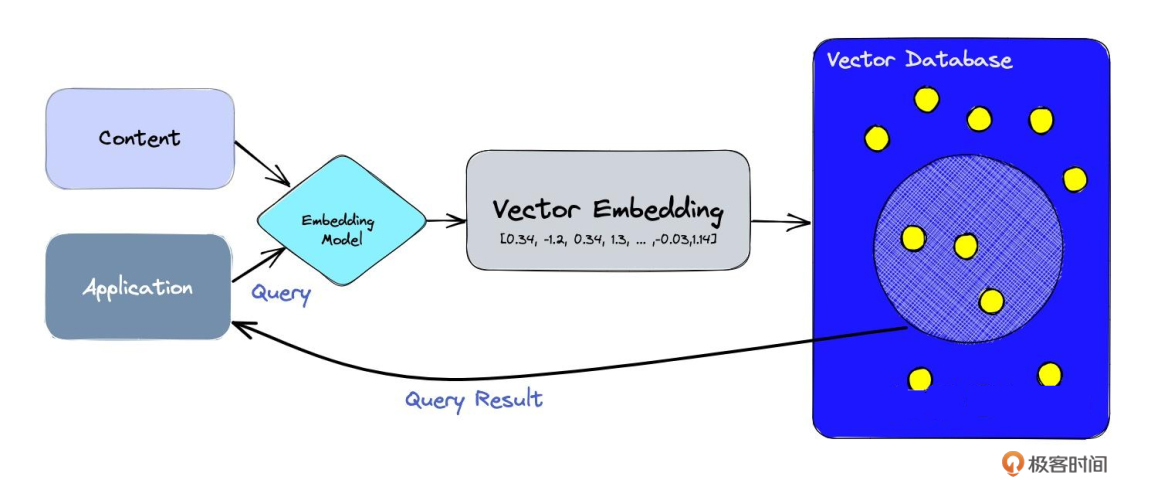
第 5 步,为每个内容片段生成嵌入向量 接下来,我们定义函数get_embeddings,这个函数用于生成内容片段的嵌入向量,然后为DataFrame中的每个内容片段生成嵌入向量。
1 2 3 4 5 6 7 8 9 10 11 12 # 获取嵌入向量 def get_embeddings(text): """获取给定文本的嵌入向量""" embeddings = client.embeddings.create( model="text-embedding-3-small", input=text, encoding_format="float" ) return embeddings.data[0].embedding # 为每个内容片段生成嵌入向量 df['embeddings'] = df['content'].apply(lambda x: get_embeddings(x))
这里我们使用text-embedding-3-small做嵌入的Model。这个过程如下图所示,有了嵌入向量,文本检索就非常方便了。
第 6 步,检索搜索相关内容 接下来,我们定义函数来实现检索逻辑,用于在DataFrame中搜索与输入文本最相关的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 搜索相关内容 from sklearn.metrics.pairwise import cosine_similarity def search_content(df, input_text, top_k): """搜索与输入文本最相关的内容""" embedded_value = get_embeddings(input_text) df["similarity"] = df.embeddings.apply(lambda x: cosine_similarity(np.array(x).reshape(1,-1), np.array(embedded_value).reshape(1, -1))) res = df.sort_values('similarity', ascending=False).head(top_k) return res # 获取相似度得分 def get_similarity(row): """获取给定行的相似度得分""" similarity_score = row['similarity'] if isinstance(similarity_score, np.ndarray): similarity_score = similarity_score[0][0] return similarity_score
此处,函数search_content首先获取输入文本的嵌入向量,然后计算每个内容片段与输入文本的余弦相似度,并返回相似度最高的前k个结果。函数get_similarity则用于从DataFrame的一行中获取相似度得分。
第 7 步,根据检索结果生成回答 整个RAG流程的最终一步,是根据检索结果生成回答。接下来,先定义系统提示,用于指导GPT-4如何根据提供的内容回复输入查询。提示中详细说明了如何判断内容是否相关以及如何生成回复。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 定义系统提示,用于指导GPT-4回复输入查询 system_prompt = ''' 你将获得一个输入提示和一些作为上下文的内容,可以用来回复提示。 你需要做两件事: 1. 首先,你要在内部评估提供的内容是否与回答输入提示相关。 2a. 如果内容相关,直接使用这些内容进行回答。如果内容相关,使用内容中的元素来回复输入提示。 2b. 如果内容不相关,使用你自己的知识回答,如果你的知识不足以回答,就说你不知道如何回应。 保持回答简洁,具体回复输入提示,不要提及上下文内容中提供的额外信息。 '''
然后,指定要使用的GPT-4模型生成输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 # 指定要使用的GPT-4模型 model="gpt-4-turbo-preview" # 生成输出 def generate_output(input_prompt, similar_content, threshold=0.5): """生成基于相似内容的输出""" content = similar_content.iloc[0]['content'] # 如果相似度高于阈值,添加更多匹配的内容 if len(similar_content) > 1: for i, row in similar_content.iterrows(): similarity_score = get_similarity(row) if similarity_score > threshold: content += f"\n\n{row['content']}" prompt = f"输入提示:\n{input_prompt}\n-------\n内容:\n{content}" completion = client.chat.completions.create( model=model, temperature=0.5, messages=[ { "role": "system", "content": system_prompt }, { "role": "user", "content": prompt } ] ) return completion.choices[0].message.content
运行查询示例,输出回复 运行查询示例,搜索相关内容并生成回复。
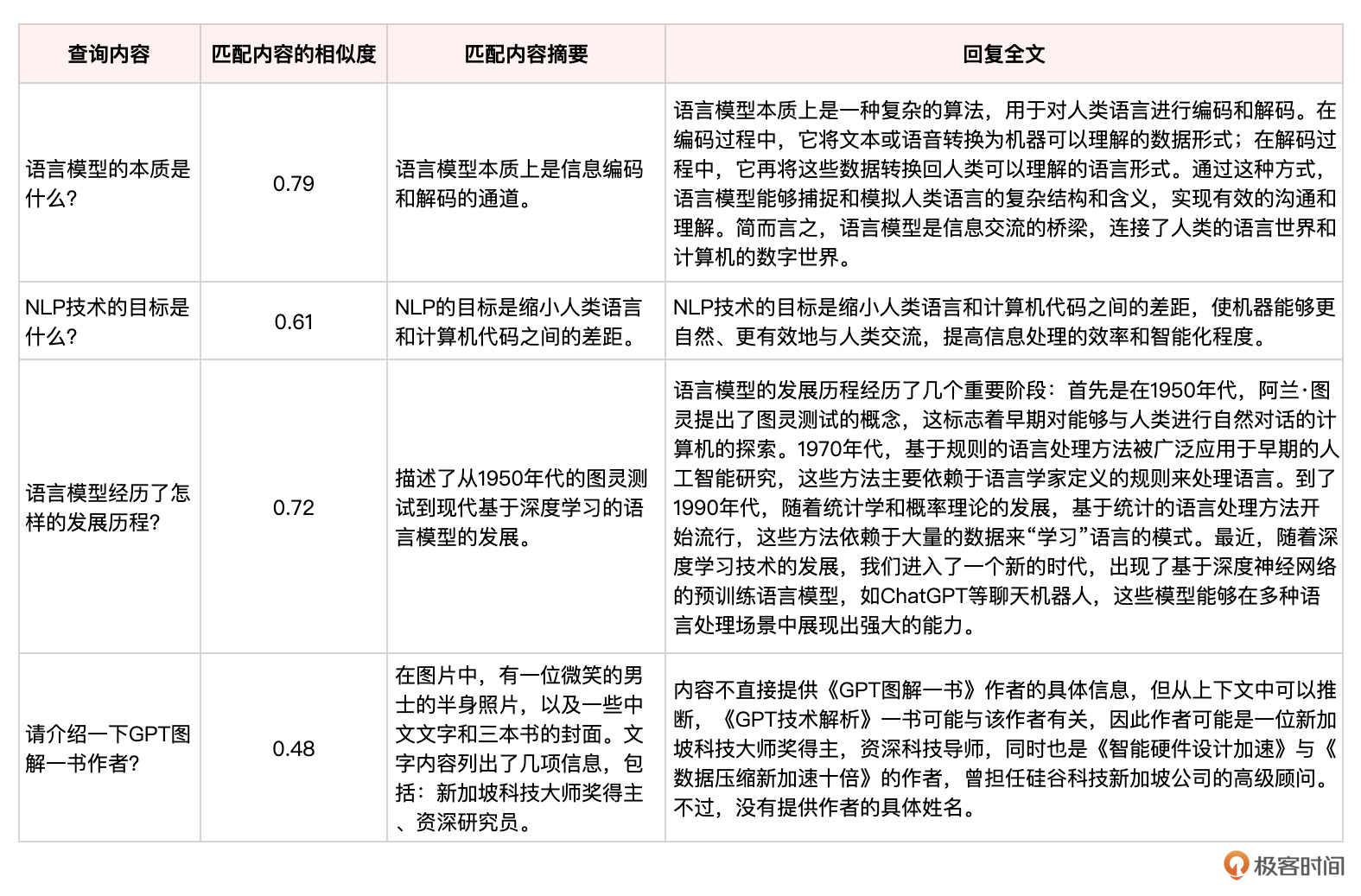
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 定义与内容相关的示例用户查询 example_inputs = [ '语言模型的本质是什么?', 'NLP技术的目标是什么?', '语言模型经历了怎样的发展历程?', '请介绍一下GPT图解一书作者?', ] # 运行示例查询 for ex in example_inputs: print(f"[deep_pink4][bold]查询:[/bold] {ex}[/deep_pink4]\n\n") matching_content = search_content(df, ex, 3) print(f"[grey37][b]匹配内容:[/b][/grey37]\n") for i, match in matching_content.iterrows(): print(f"[grey37][i]相似度: {get_similarity(match):.2f}[/i][/grey37]") content = str(match['content']) print(f"[grey37]{content[:100]}{'...' if len(content) > 100 else ''}[/[grey37]]\n\n") reply = generate_output(ex, matching_content) print(f"[turquoise4][b]回复:[/b][/turquoise4]\n\n[spring_green4]{reply}[/spring_green4]\n\n--------------\n\n")
输出结果列表总结如下:
很不错,这个问答系统在大部分问题上都能匹配到相关程度较高的内容,并据此生成简明扼要、切中要点的回复。最后一个问题,虽然回答得不好,其原因应该是程序代码中有一个逻辑就是把PDF的首页内容给删去了,而这个首页内容正是GPT图解一书的书名。
然而,基于 GPT-4V 的读图能力,ChatGPT 仍然推断出,图片中的半身照中的那个微笑的男士,很可能就是GPT图解一书的作者。
总结时刻 在这个案例中,我们巧妙地将不同大模型的能力融合在RAG系统的各个环节,实现了多模态理解、语义检索、知识融合等关键功能。这种灵活运用大模型的思路,值得在其他智能应用的开发中借鉴。
在这节课中,我们充分利用了几个大模型。
GPT-4V:作为GPT-4的视觉版本,GPT-4V(gpt-4-vision-preview)在RAG系统中扮演了关键角色。我们利用GPT-4V对PDF中的图像进行理解和描述,通过精心设计的提示,引导模型提取图表信息、识别标题等。这充分发挥了GPT-4V在多模态理解方面的能力,使得RAG系统能够同时处理文本和图像信息。 Embedding模型:使用OpenAI的 “text-embedding-3-small” 模型对文本片段进行向量化表示。将文本映射到高维向量空间,使得语义相似的内容在向量空间中更加接近。这种语义表示方法是实现高效内容检索的基础,使RAG系统能够快速找到与查询最相关的内容。 GPT-4:最后一步中使用GPT-4生成模型(gpt-4-turbo-preview),根据检索出的相关内容生成最终答案。这充分利用了GPT-4在自然语言生成方面的强大能力,能够根据上下文信息生成流畅、连贯的回复。同时,精心设计的系统提示也引导了GPT-4对相关性进行判断,提高了回复的质量。 另外,我也再次总结一下检索增强生成(RAG)技术,这是一种结合信息检索和文本生成的人工智能技术。通常将它用于问答系统、对话生成或内容摘要等自然语言处理任务。
RAG 的工作原理可以分为如下两个主要部分:
信息检索(Retrieval):在这一阶段,系统会从一个大型的数据集中检索相关信息。这个数据集通常包含大量的文本数据,如维基百科文章、新闻报道或其他相关文档。(当然,因为目前的检索也是通过大模型来完成,而且大模型通常具有多模态能力,因此这个被检索的数据集并不一定都是文档,还可以是图片、代码、关系数据库等多种形式。)当系统接收到一个查询(例如一个问题)时,它会在这个数据集中寻找与查询相关的信息。 文本生成(Generation):在检索到相关信息后,系统会使用这些信息来生成一个响应。这个阶段通常是通过一个预训练的语言模型完成的,如 GPT(Generative Pre-trained Transformer)。语言模型会根据检索到的信息来构造一个连贯、相关的回答或文本。 RAG 的优势在于,它结合了检索系统的精确信息获取能力和语言模型的流畅文本生成能力。这使得 RAG 在处理复杂的语言理解任务时,能够提供更加丰富、准确的信息。例如,在问答系统中,RAG 能够提供基于具体事实的答案,而不仅仅是基于语言模型的一般性推断。这是一个从用户查询到最终响应的闭环。用户提出查询,查询被用来从知识库中提取相关上下文,然后语言模型使用这些上下文信息来生成一个合适的响应。基于这个流程的 Agent,也可以在聊天机器人、搜索引擎、推荐系统或任何其他需要从大量数据中提取和处理信息的系统中发挥作用。
RAG代表了一种知识驱动的AI范式。它弥补了纯粹的数据驱动方法的局限性,在知识表示、可解释性、数据效率等方面展现了其独特优势。同时,其技术门槛相对较低,适合中小企业和开发者快速构建智能应用。这些特点使其成为了开发者将大模型能力引入实际应用的首选方案之一。
未来,RAG技术有望进一步发展,融合更先进的知识表示、推理和学习机制。它有望成为连接大模型技术和行业应用的重要桥梁,为人工智能应用开辟出更加广阔的空间。因此,在不久的将来,我还会以专栏或者视频课程的形式带你更全面地深挖RAG技术。
思考题 这节课我们主要讨论了基于PDF的RAG系统,那么对于其他非结构化数据,如音频、视频等,你认为该如何设计RAG系统的架构和工作流程呢?是否需要引入新的大模型或技术? 我们在处理PDF图像时,使用GPT-4V提取图片信息,然后与页面文本匹配。你认为这种方式在处理图文不对齐、图表缺失标题等情况时是否会遇到困难?你有什么改进建议吗? 在生成回复时,我们设置了一个相似度阈值,来决定是否使用更多的匹配内容。这个阈值如何选取?过高或过低会带来哪些问题?你认为还有哪些策略可以用于筛选和排序匹配内容? 期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!