你好,我是黄佳。
今天我们来聊两个实际的问题。第一,在调用OpenAI API时,可能会碰见哪些错误,应该如何处理。第二,如何通过各种日志记录工具,来监控大模型的应用的运行过程。
OpenAI API 的错误处理 在与OpenAI API交互时,你可能会遇到各种错误。了解如何处理这些错误,对于确保应用程序的稳定性和可靠性至关重要。如果了解可能出现的错误类型,那么就见怪不怪了。
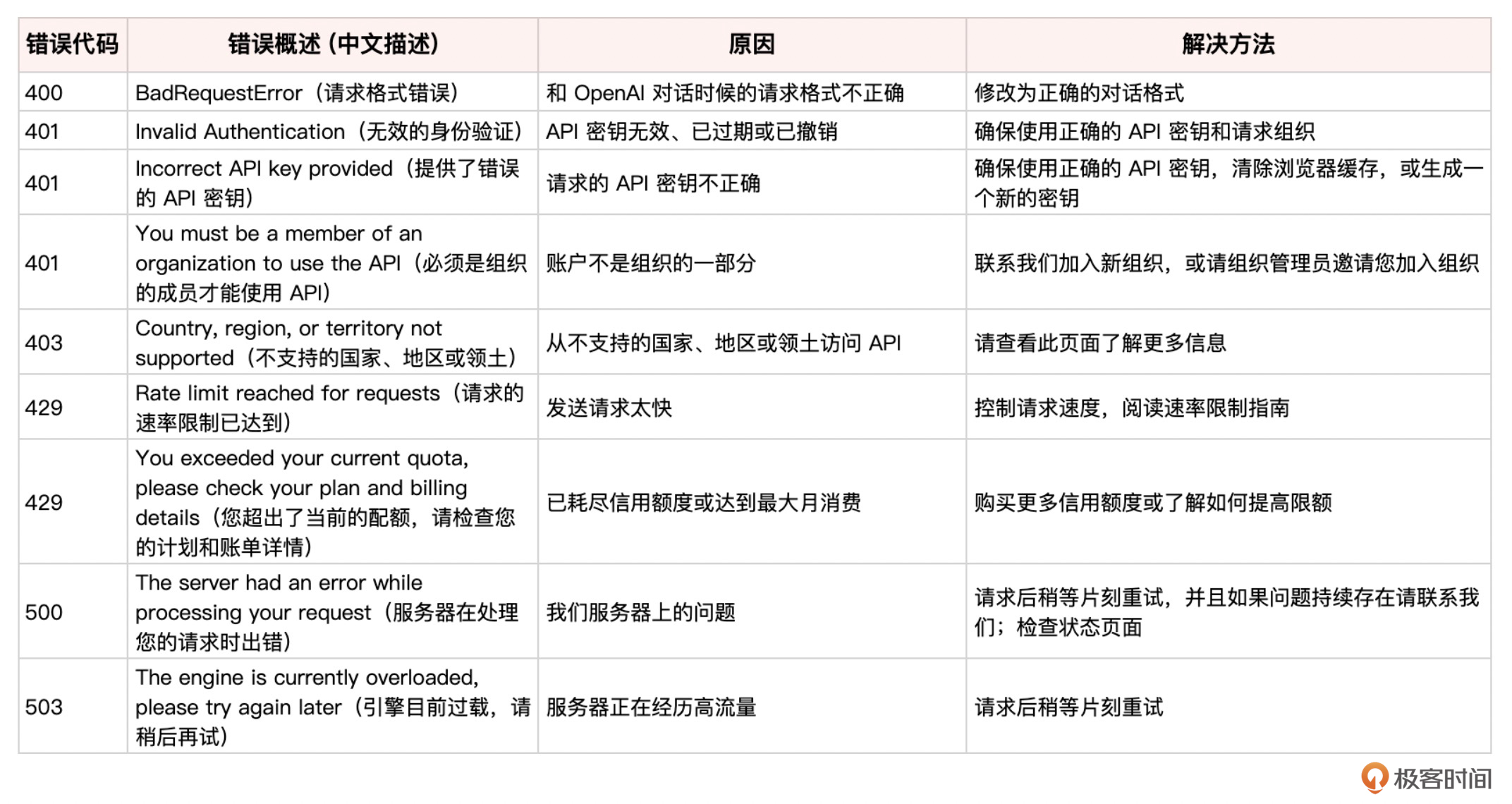
下面我们总结一下OpenAI API返回的常见错误类型,并提供处理这些错误的实用技巧。
OpenAI API返回的错误主要分为以下几类:
请求错误(400):表示请求格式不正确或缺少必需参数,如Token或输入。常见原因包括参数名称、类型、值或格式与文档不匹配。 身份验证错误(401):表示API密钥无效、已过期或已撤销。常见原因包括API密钥有错或已经发生了安全漏洞。 速率限制错误(429):表示在给定时间段内发送了太多Token或请求,超过了分配的速率限制。 服务器错误(500):表示服务器在处理请求时出现意外错误,可能是由于临时错误、bug或系统中断。 连接错误:表示请求无法到达服务器或建立安全连接,可能是由于网络问题、代理配置、SSL证书或防火墙规则。 超时错误:表示请求花费的时间太长而无法完成,服务器关闭了连接。可能是由于网络问题、服务器负载过重或请求过于复杂。 完整的错误信息列表如下。
如果遇到错误,见招拆招。先检查API密钥是否正确。如果遇到Connection的问题,很可能需要切换网络或调整代理设置。遇到速率限制错误时,减少请求频率,或等待速率限制重置。遇到服务器错误时,等待几秒钟后重试请求。检查OpenAI系统状态页面,了解是否有正在进行的事件或维护影响服务。也有的时候,ChatGPT会出现宕机,可以去ChatGPT网站看看是否有宕机声明。
这里我举一个调用OpenAI API时出错的例子。在下面这段代码中,我试图让GPT给我把某一个目录中所有的Markdown文档内容都做个总结,然后生成一个新的文档。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import os # 创建OpenAI客户端 from openai import OpenAI client = OpenAI() input_directory = '10_Applications/06_VideoCaption/output' output_file = '10_Applications/06_VideoCaption/output/Summary.md' def read_md_files(directory): md_contents = [] for filename in os.listdir(directory): if filename.endswith('.md'): with open(os.path.join(directory, filename), 'r', encoding='utf-8') as file: md_contents.append(file.read()) return md_contents def summarize_contents_with_gpt4o(contents): content_str = "\n\n".join(contents) response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "你正在生成视频的总结。请提供视频的总结,并以Markdown格式回应。"}, {"role": "user", "content": [ "这些是文件的内容:", {"type": "text", "text": "\n\n".join(contents)} ]} ], temperature=0.5, ) return response.choices[0].message.content def write_summary_file(summary, output_file): with open(output_file, 'w', encoding='utf-8') as file: file.write(summary) def main(): md_contents = read_md_files(input_directory) summary = summarize_contents_with_gpt4o(md_contents) write_summary_file(summary, output_file) print(f"Summary file created at {output_file}") if __name__ == "__main__": main()
运行程序会出现下面的错误。
openai.BadRequestError: Error code: 400 - {‘error’: {‘message’: “Invalid type for ‘messages[1].content[0]’: expected an object, but got a string instead.”, ‘type’: ‘invalid_request_error’, ‘param’: ‘messages[1].content[0]’, ‘code’: ‘invalid_type’}}
下面调整一下程序,增加 try/except 块处理OpenAI API返回的错误。这虽然没有解决本质问题,但是至少能够让程序正常结束。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def summarize_contents_with_gpt4o(contents): try: response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "你正在生成视频的总结。请提供视频的总结,并以Markdown格式回应。"}, {"role": "user", "content": [ "这些是文件的内容:", {"type": "text", "text": "\n\n".join(contents)} ]} ], temperature=0.5, ) return response.choices[0].message.content except Exception as e: print(f"Error generating summary: {e}") return None
那么,实际上,问题出在构建messages时,试图将一个列表嵌入到content字段中,而这个字段预期的类型是字符串。这导致了BadRequestError错误。为了解决这个问题,我们需要将内容连接成一个单一的字符串,而不是列表。这个修改程序的过程就留给你作为一个额外的思考题来完成。
使用 Weights & Biases 跟踪应用开发过程 在机器学习和AI等涉及大量数据和模型调试的工作中,经常会用到Weights & Biases (wandb) 这个工具。这是一个用于机器学习和深度学习项目的实验跟踪和可视化工具,它能够自动记录和跟踪实验参数、超参数、模型架构和训练指标,提供实时监控和可视化图表,支持团队协作,集成超参数优化工具,管理和部署模型,并生成详细的实验报告。
这些功能可以帮助开发者和研究人员高效地管理、监控和优化模型及其实验过程。
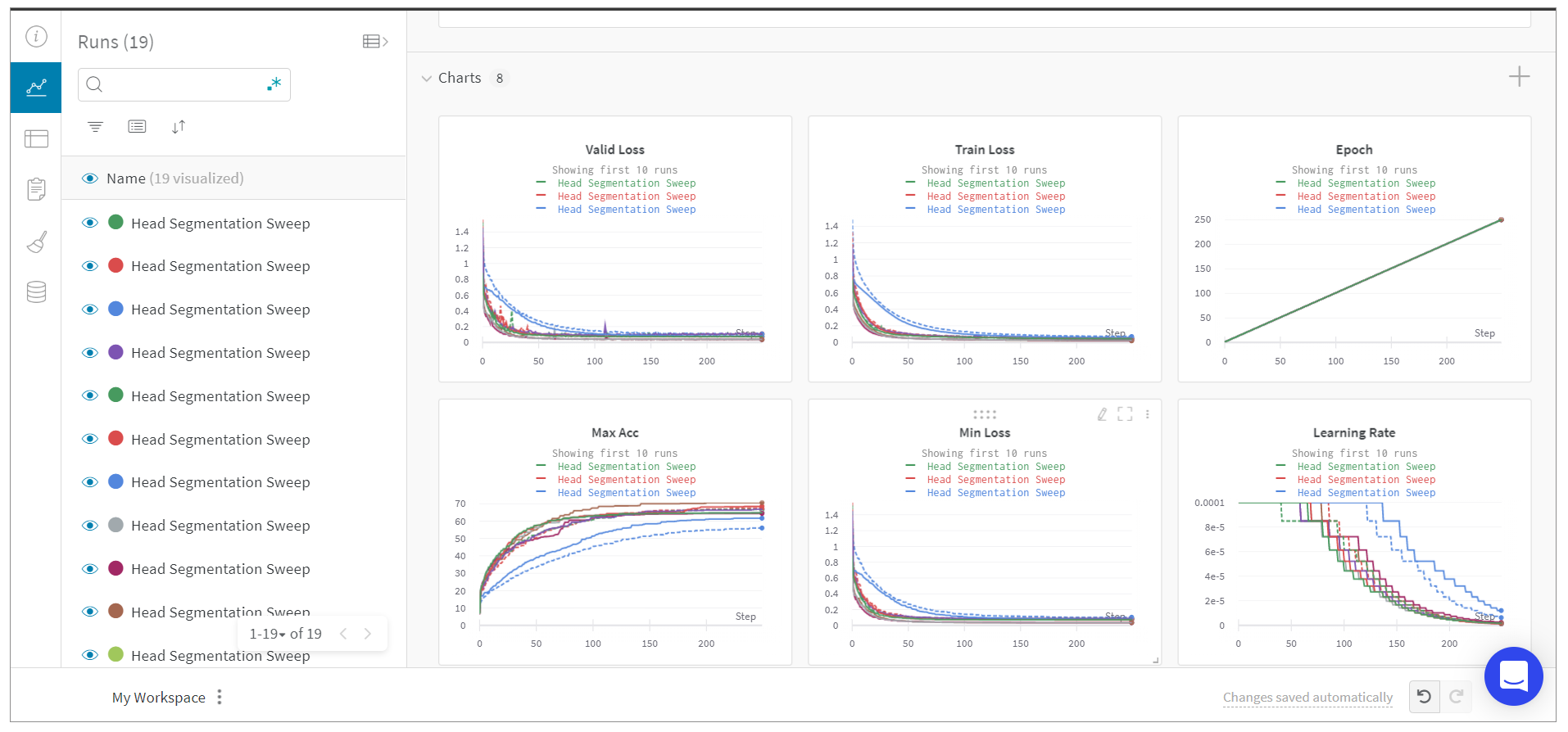
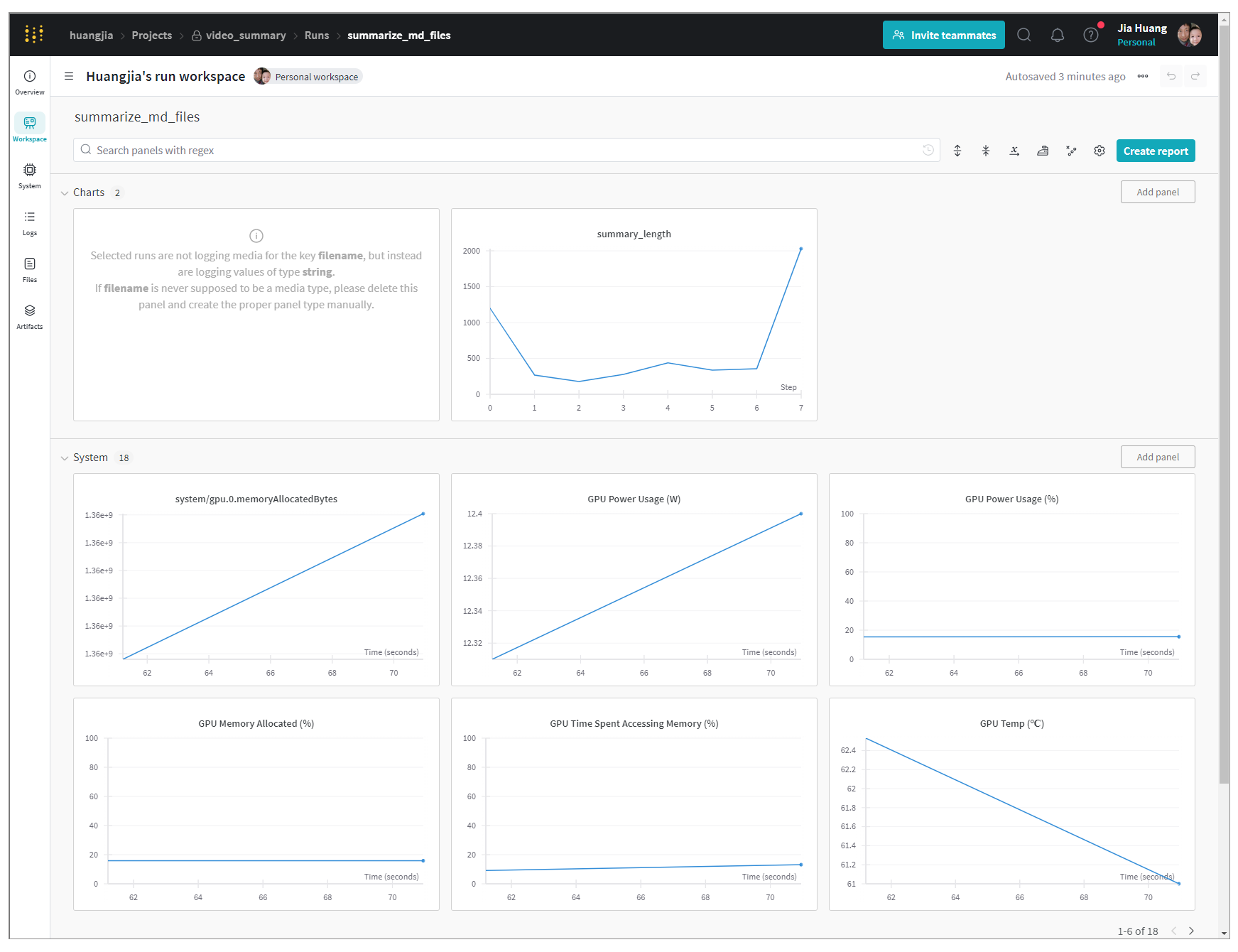
上图所示为一个典型的机器学习模型训练过程,通过wandb这个工具来可视化训练过程中各个轮次的损失和准确率。
对于我们的大模型应用开发来说,虽然我们不需要训练模型,但是,我们也可以利用wandb的强大的Logging、Tracing以及可视化的能力,来监控我们的大模型应用运行状态。比如说,如果我让大模型帮我总结 100 个文档,我可以通过日志记录每个文档的大小,我传输过程中 Token 的数量,总结完成后的文本长度等等 。这就是wandb这个工具的重要价值所在。
这里我们先安装好wandb这个包。
好的,那么现在可以去这里创建 一个账号了。并且,申请到Access Key,等一下跑程序的时候需要用到。
我把刚才的文档总结程序进行下面的改造,意图就是记录,并且检测每一次文档总结时候的以下细节,比如说文件名、总结的长度等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def read_md_files(directory): md_contents = [] filenames = [] for filename in os.listdir(directory): if filename.endswith('.md'): with open(os.path.join(directory, filename), 'r', encoding='utf-8') as file: md_contents.append(file.read()) filenames.append(filename) return md_contents, filenames def main(): # 初始化wandb wandb.init(project="video_summary", name="summarize_md_files") md_contents, filenames = read_md_files(input_directory) all_summaries = [] for content, filename in zip(md_contents, filenames): try: summary = summarize_contents_with_gpt4o(content) all_summaries.append(f"# Summary for {filename}\n\n{summary}\n\n") wandb.log({"filename": filename, "summary_length": len(summary)}) except Exception as e: print(f"Error summarizing {filename}: {e}") wandb.log({"filename": filename, "error": str(e)}) final_summary = "\n".join(all_summaries) write_summary_file(final_summary, output_file) print(f"Summary file created at {output_file}") wandb.finish()
代码的结构也很清晰。
在代码中初始化wandb会话,通过 wandb.init(project="video_summary", name="summarize_md_files")。 在main函数中,逐个处理Markdown文件,调用summarize_contents_with_gpt4o进行总结。 记录每个文件的总结状态和长度,通过wandb.log将总结的文本长度这个信息发送到wandb服务器。同时,在总结过程中捕获异常,并将错误信息记录到wandb。 将所有文件的总结合并成一个文件,并写入指定的输出文件。 通过上述步骤,你可以实现对每个Markdown文件的逐个总结,并使用wandb监控和记录每个总结过程的状态和结果。这不仅有助于跟踪处理进度,还能在出现问题时快速定位并解决。
运行程序时,wandb会要求我选择是否已经有账号。我选择2,因为我刚刚已经创建了账号。
然后找到我的Key,并且输入。
这样,wandb就开始在跑程序的时候监控并记录日志了。
程序运行结束,在本地的wandb目录下,也可以看到日志。
当然,更漂亮的是,在网页端,wandb满足了我们的核心需求:记录这些文件的summary的长度。同时还有其他一些信息,包括我跑代码时候GPU的使用情况。
好了,这样,我们就成功的把程序的运行日志,通过Weights & Biases进行了实时的记载和可视化。
使用 LangSmith 监控大模型调用 不过,对于大模型应用开发来说,Weights & Biases还不够完美,因为有些细节,比如说调用大模型时候的输入输出,调用的细节,调用了多少Token,花费了多少钱,这些东西Weights & Biases没法自动帮我们进行归纳。
此时,LangChain 这个大模型开发生态环境中的 LangSmith 工具就能够帮到我们。LangSmith是一个用于构建生产级LLM应用程序的平台,可以帮你密切监控和评估应用程序,而且使用LangSmith不需要依赖LangChain包,也就是说这个工具可以独立于LangChain而存在。
首先,安装LangSmith。
1 pip install -U langsmith
然后,到设置页面,创建API密钥。
接下来,设置环境变量。
1 2 export LANGCHAIN_TRACING_V2=true export LANGCHAIN_API_KEY=<your-api-key>
接下来就可以使用LangSmith来记录任意的大模型调用过程了。下面,我们使用 @traceable 装饰器来自动trace LLM调用。这个程序,是我们在前几课中曾经讲解过的给Video做Summary的程序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 from dotenv import load_dotenv load_dotenv() import os import openai from langsmith.wrappers import wrap_openai from langsmith import traceable # 创建OpenAI客户端并使用langsmith进行包装 client = wrap_openai(openai.Client()) input_directory = '10_Applications/06_VideoCaption/output' output_file = '10_Applications/06_VideoCaption/output/Summary.md' def read_md_files(directory): md_contents = [] filenames = [] for filename in os.listdir(directory): if filename.endswith('.md'): with open(os.path.join(directory, filename), 'r', encoding='utf-8') as file: md_contents.append(file.read()) filenames.append(filename) return md_contents, filenames @traceable def summarize_contents_with_gpt4o(content): response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "你正在生成视频的总结。请提供视频的总结,并以Markdown格式回应。"}, {"role": "user", "content": "这些是文件的内容:\n\n" + content} ], temperature=0.5, ) return response.choices[0].message.content def write_summary_file(summary, output_file): with open(output_file, 'w', encoding='utf-8') as file: file.write(summary) def main(): md_contents, filenames = read_md_files(input_directory) all_summaries = [] for content, filename in zip(md_contents, filenames): try: summary = summarize_contents_with_gpt4o(content) all_summaries.append(f"# Summary for {filename}\n\n{summary}\n\n") # 使用langsmith记录日志 print(f"Summary for {filename} length: {len(summary)}") except Exception as e: print(f"Error summarizing {filename}: {e}") # 使用langsmith记录错误日志 print(f"Error: {str(e)}") final_summary = "\n".join(all_summaries) write_summary_file(final_summary, output_file) print(f"Summary file created at {output_file}") if __name__ == "__main__": main()
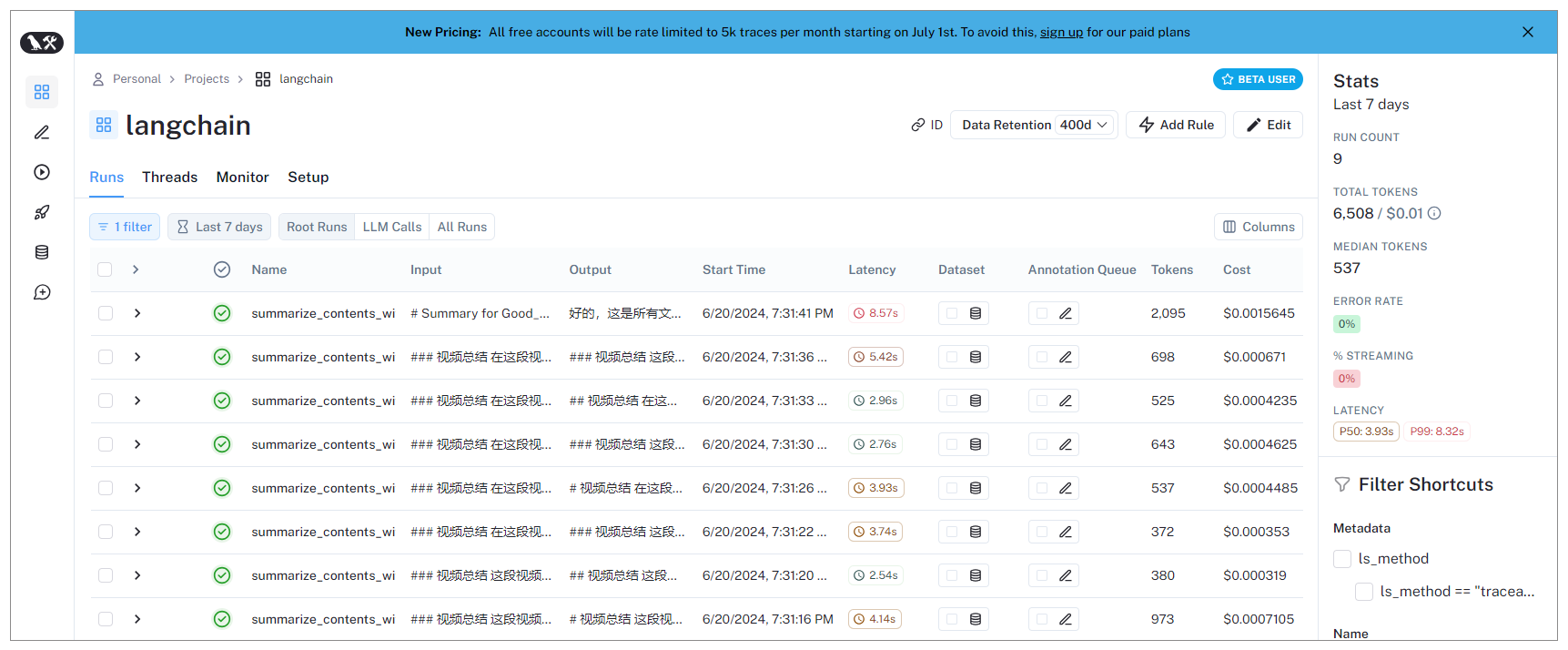
程序代码中,先使用LangSmith包装OpenAI客户端。其中,wrap_openai函数用于将OpenAI客户端包装为LangSmith兼容的客户端,以便进行追踪和日志记录。之后,添加traceable装饰器。@traceable装饰器用于将函数标记为可追踪的,这样LangSmith可以记录函数调用的输入和输出。
程序运行之后,再度登录LangSmith,将看到程序与大模型的交互细节都被记录。
总结时刻 在调用OpenAI API时,常见的错误类型包括请求错误(400)、身份验证错误(401)、速率限制错误(429)、服务器错误(500)、连接错误和超时错误。针对这些错误,我们可以采取相应的处理措施,如检查API密钥、调整网络设置、减少请求频率、重试请求等。
为了更好地监控和记录大模型应用的运行过程,可以使用日志记录工具,如Weights & Biases和LangSmith。Weights & Biases适用于记录和可视化训练过程中的各类参数和指标,而LangSmith更适合追踪大模型调用的详细信息,包括输入输出、调用次数、消耗的Token数等。
除了Weights & Biases之外,TensorBoard也是常用的机器学习可视化工具,尤其是用于监控和记录基于TensorFlow的模型训练过程中的指标、模型结构和数据流图。另一个机器学习开源监控平台是MLflow,用于管理机器学习的生命周期,包括实验跟踪、项目管理、模型管理和部署。这两个工具,你也可以了解一下。
思考题 你曾遇到过哪些OpenAI API错误,如何解决的? Weights & Biases和LangSmith各自的优缺点是什么?在什么场景下你会选择使用Weights & Biases?在什么场景下你会选择使用LangSmith? 期待你的分享,欢迎与我交流。如果今天的内容让你有所收获,也欢迎你把这节课转发给有需要的朋友!我们下节课再见!